
출처 : http://eknote.tistory.com/1128
JBoss를 실행하려고 하니... 1098 포트 에러가 발생했다.
JVM바인딩 하는 포트가 1098번 이라고 하면서 이미 사용중인 포트라고 말하는것 같은데..
-_-; 머냐 이거..아무런 문제 없던것이.. ( 해결하고 작성하는 거라..-_- 이미는 없다..)
다음은 해결책.
1. 이미 사용중인 포트 번호를 알아보자
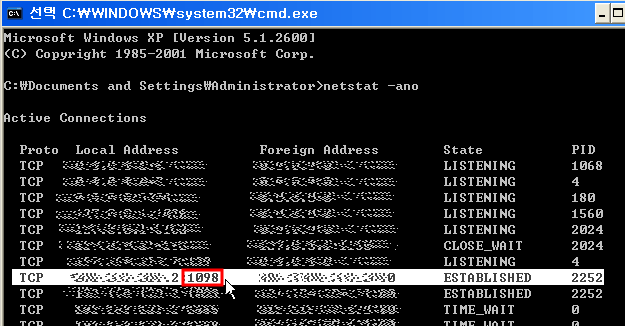
cmmand 창을 열고 c:\>netstate -ano 을 쳐보자 ( * netstat에 대한 설명 >netstat -help )
그러면 다음과 같이 사용중인 포트 정보를 보여준다.
그중에서 에러를 발생시는 녀석의 PID(우측)를 확인하자.
(이 캡쳐는 에러시에 확인한 포트리스트다.)
2. Window 작업 관리자'를 열고 해당 PID를 사용하는 프로세스를 확인하고 강제종료 한다.
( 본인은 웹마에서 사용중이었다..-_-;)
2.1. Window 작업 관리자 여는 법
- 우측의 트레이에 마우스를 가져간후 마우스 오른쪽을 클릭한후, '작업 관리자(K)' 선택
- 혹은 Ctrl 키 + Alt키 + Delete 키를 동시에 누른다.
 2.2. PID 확인하는 방법
2.2. PID 확인하는 방법
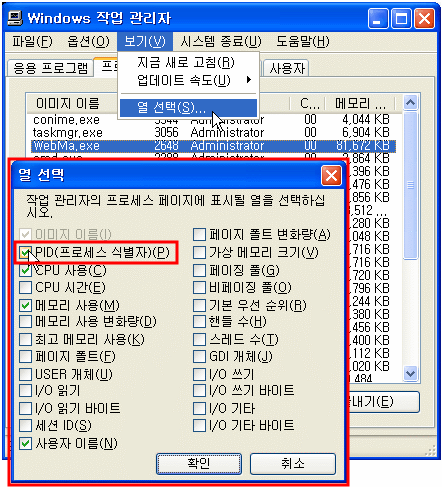
: 상단의 메뉴의 보기(V)에서 열선택(S)를 선택한후,
PID(프로세스 식별자)(p) 을 체크해줍니다.
(본인은 웹마가 1098을 사용중이었습니다. -_-; 아래 캡쳐는 해결한 후..)
JBoss를 실행하려고 하니... 1098 포트 에러가 발생했다.
JVM바인딩 하는 포트가 1098번 이라고 하면서 이미 사용중인 포트라고 말하는것 같은데..
-_-; 머냐 이거..아무런 문제 없던것이.. ( 해결하고 작성하는 거라..-_- 이미는 없다..)
다음은 해결책.
1. 이미 사용중인 포트 번호를 알아보자
[열기] cmd창 여는법
1. 시작 > 모든 프로그램 > 보조 프로그램 > 명령 프롬포트
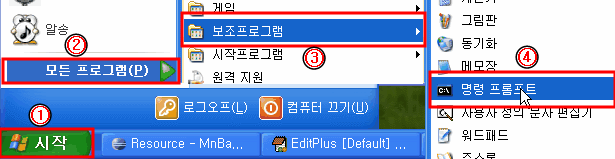
2. 시작 > 실행 > 'cmd' 입력 > 확인

2. 시작 > 실행 > 'cmd' 입력 > 확인
cmmand 창을 열고 c:\>netstate -ano 을 쳐보자 ( * netstat에 대한 설명 >netstat -help )
그러면 다음과 같이 사용중인 포트 정보를 보여준다.
그중에서 에러를 발생시는 녀석의 PID(우측)를 확인하자.
(이 캡쳐는 에러시에 확인한 포트리스트다.)
2. Window 작업 관리자'를 열고 해당 PID를 사용하는 프로세스를 확인하고 강제종료 한다.
( 본인은 웹마에서 사용중이었다..-_-;)
2.1. Window 작업 관리자 여는 법
- 우측의 트레이에 마우스를 가져간후 마우스 오른쪽을 클릭한후, '작업 관리자(K)' 선택
- 혹은 Ctrl 키 + Alt키 + Delete 키를 동시에 누른다.
: 상단의 메뉴의 보기(V)에서 열선택(S)를 선택한후,
PID(프로세스 식별자)(p) 을 체크해줍니다.
(본인은 웹마가 1098을 사용중이었습니다. -_-; 아래 캡쳐는 해결한 후..)
출처 : http://blog.naver.com/makesome?Redirect=Log&logNo=150071511335
http://dev.anyframejava.org/anyframe/doc/core/3.1.0/corefw/guide/cache.html
|
|
|
|
|
| cache.memory | 메모리 Cache를 사용할 것인지 정의한다. false로 설정되면 메모리로 캐싱될 수 없다. |
|
|
| cache.capacity | Cache에 저장할 수 있는 object의 최대 갯수를 지정한다. 음수로 설정되면 이 기능을 사용하지 않는다. 캐싱 가능한 object의 갯수를 제한하지 않는다. |
|
|
| cache.algorithm | caching algorithm의 classname을 지정한다. 이 클래스는 com.opensymphony.oscache.base.algorithm.AbstractConcurrentReadCache를 extend 해야한다. cache capacity가 양수로 설정되면 default algorithm으로 LRUCache가 사용되고, 음수로 설정되면 com.opensymphony.oscache.base.algorithm.UnlimitedCache가 사용된다. |
|
|
| cache.unlimited.disk | Persistence cache의 size를 제한할 것인지 또는 in-memory cache와 동일한 사이즈로 제한할 것인지를 나타낸다. 이 값이 true 로 설정되면 persistent cache는 제한없이 사용될 수 있다. |
|
|
| cache.blocking | 새로운 content를 캐싱하거나 이미 캐싱된 content를 검색할 때 block waiting 해야 하는지를 정의한다. |
|
|
| cache.persistence.class | Persistence cache를 사용하고자 할 때 Persistence cache를 구현한 classname을 정의한다. 이 클래스는 PersistenceListener를 extend 해야한다. |
|
|
| cache.persistence .overflow.only |
메모리 Cache가 overflow mode일때 Persistence Cache를 사용할지 지정한다. |
|
|
| cache.event.listeners | Cache에 적용한 event handler를 지정한다. event handler가 여러개 일 경우 각각의 classname을 콤마로 구분하여 정의한다. |
|
|
| cache.cluster.properties | JavaGroupsBroadcastingListener를 사용할때 이 property를 정의한다. JavaGroups channel properties를 사용한다. JavaGroups의 실행을 제어할 수 있다. |
|
|
| cache.cluster.multicast.ip | JavaGroupsBroadcastingListener를 사용할 때 이 property를 정의한다. broadcasting을 사용하기 위해 JavaGroups는 multicast IP를 사용해야 한다. |
|
|
| cache.cluster.jms.node.name | JMS10BroadcastingListener 또는 JMSBroadcastingListener를 사용할 때 이 property를 정의한다. JMS connection factory를 사용한다. |
|
|
| cache.cluster.jms.topic.name | JMS10BroadcastingListener 또는 JMSBroadcastingListener를 사용할때 이 property를 정의한다. 이것은 JMS topic name 이다. |
|
|
| cache.cluster.jms.topic.factory | JMS10BroadcastingListener 또는 JMSBroadcastingListener를 사용할때 이 property를 정의한다. 이 노드의 이름은 cluster에 존재하고, 각각의 node마다 unique한 값을 갖는다. |
|
|
| cache.path | DiskPersistenceListener를 사용할 때 이 property를 정의한다. 데이터를 캐싱하기 위한 path를 지정한다. |
|
|
| cache.persistence.disk .hash.algorithm |
disk의 filname으로 간단한 cache key를 생성하기 위한 hash algorithm이다. |
|
|
출처 : http://theeye.pe.kr/379
iBATIS는 공식적으로 캐시를 할때에 OSCache를 사용할 수 있도록 되어있습니다. 하지만 그 기능이 매우 자동적이며 제한적이고 세세한 설정을 개발자가 할수가 없습니다. 그래서 다음을 한번 알아 보기로 할까요. 다음의 예시는 [이곳]에 언급된 내용을 살짝 수정하였습니다.
위의 SQL맵 예제에서는 INSERT문 한개와 SELECT문 3개가 존재합니다. 모두 cacheModel이라는 id의 캐시모델과 연관되어집니다. 이것을 간단하게 그림으로 그려보면 다음과 같은 모양을 가지고 있습니다.

그려놓고 보니깐 좀 말이 안되는 그림 같아 보이네요;; 아무튼 하나의 캐시 모델에 3가지의 캐시를 생성할 수 있는 조건이 있고 2가지 캐시를 삭제할 수 있는 조건이 있다고 봐주시면 되겠습니다. 둥근 사각형은 개발자가 임의로 호출을 해야만 하는 기능들이고 위의 동그라미는 캐시 유지 시간 설정으로 봐주시면 되겠습니다.
이제 다음의 몇가지 예시 상황들에 대한 캐시의 처리 과정에 대해 알아보겠습니다.
1. 한개의 캐시 처리 (makeCache1 → flushCache)
makeCache1이 수행되면 cacheModel에 하나의 캐시가 생성됩니다. 앞으로 makeCache1이 호출될때마다 캐시가 존재하는한 DB에 접근없이 캐시결과값을 제공하게 됩니다. flushCache를 수행하면 캐시가 삭제됩니다. 다시 makeCache1을 호출하면 DB에서 결과를 가져와서 반환함과 동시에 캐시를 생성하게 됩니다. 캐시가 생성된 시점에서 flushInterval에 설정된 시간이 경과하도록 flushCache가 호출되지 않는다면 시간 만료로 자동 삭제됩니다.
2. 두개의 캐시 처리 (makeCache1 → makeCache2 → flushCache)
makeCache1이 호출되면 cacheModel에 하나의 캐시가 생성됩니다. makeCache2가 호출되면 마찬가지로 cacheModel에 또다른 하나의 캐시가 생성됩니다. 이 두개의 캐시는 엄연히 다르며 각각의 makeCacheX가 호출될때 해당하는 만들어진 캐시값을 반환하게 됩니다. 하지만 둘다 모두 동일하게 cacheModel안에 소속됩니다. 이어서 flushCache를 호출하게 되면 두 캐시가 모두 삭제됩니다. 정확히는 flush에 대한 설정을 해두면 해당 캐시모델의 모든 캐시를 소거한다고 보시면 됩니다. 그러므로 이런 부분에 주의하여 캐시모델을 함께 사용할지 따로 다른 캐시모델을 만들지를 결정하셔야 합니다.
3. 인자값의 차이에 따른 처리 (makeCache3[1] -> makeCache3[2] -> flushCache)
makeCache3에는 parameterClass를 사용하여 동적인 쿼리를 수행하도록 되어있습니다. 예시로 간단하게 int값을 받도록 하였는데요. 캐시를 생성할때의 키값에는 이 인자값들이 모두 포함되어 키를 이룹니다. 그러므로 paramterClass로 넘어오는 값이 1일때와 2일때는 다른 쿼리(키)가 됩니다. 그러므로 1이라는 값의 인자를 받아 실행되는 makeCache3의 캐시와 2라는 값을 받아 실행되는 makeCache3는 각각 별개의 캐시가 생성됩니다. 마찬가지로 하나의 cacheModel안에서 호출되지만요. flushCache를 호출하면 이 두캐시가 모두 삭제됩니다.
결론을 내보자면 위와 같은 iBATIS에서 제공하는 기본적인 캐시모델로는 같은 쿼리지만 다른 결과가 나올 수 있는 부분에는 사용할 수 없습니다. SNS 서비스에서 볼 수 있을 다음을 생각해 봅시다.
위를 수행하였을 때 친구들의 정보가 바뀌어도 사용자는 계속 캐시된 값을 받게됨을 알 수 있습니다. 그러므로 친구들의 업데이트 된 정보를 적시에 얻기가 힘듭니다. 하지만 그렇다고 친구의 정보가 업데이트 될때 다른 사용자의 캐시를 삭제하는데도 무리가 있습니다. 왜냐하면 캐시 키 값을 모르기 때문이죠. 이부분을 해결하려면 iBATIS의 SQL맵 캐시 기능을 사용하지 말고 자체적인 알고리즘으로 구현을 해야 할 것 같습니다.
iBATIS는 공식적으로 캐시를 할때에 OSCache를 사용할 수 있도록 되어있습니다. 하지만 그 기능이 매우 자동적이며 제한적이고 세세한 설정을 개발자가 할수가 없습니다. 그래서 다음을 한번 알아 보기로 할까요. 다음의 예시는 [이곳]에 언급된 내용을 살짝 수정하였습니다.
<cacheModel type="OSCACHE" id="cacheModel" readOnly="true">
<flushInterval hours="24"/>
<flushOnExecute statement="flushCache"/>
</cacheModel>
<resultMap class="kr.pe.theeye.Cache" id="CacheResult">
...
</resultMap>
<insert id="flushCache" resultClass="string">
INSERT ...
</insert>
<select id="makeCache1" resultMap="CacheResult" cacheModel="cacheModel">
SELECT ...
</select>
<select id="makeCache2" resultMap="CacheResult" cacheModel="cacheModel">
SELECT ...
</select>
<select id="makeCache3" resultMap="CacheResult" parameterClass="int"
cacheModel="cacheModel">
SELECT ... WHERE PAGE = #value#
</select>위의 SQL맵 예제에서는 INSERT문 한개와 SELECT문 3개가 존재합니다. 모두 cacheModel이라는 id의 캐시모델과 연관되어집니다. 이것을 간단하게 그림으로 그려보면 다음과 같은 모양을 가지고 있습니다.
그려놓고 보니깐 좀 말이 안되는 그림 같아 보이네요;; 아무튼 하나의 캐시 모델에 3가지의 캐시를 생성할 수 있는 조건이 있고 2가지 캐시를 삭제할 수 있는 조건이 있다고 봐주시면 되겠습니다. 둥근 사각형은 개발자가 임의로 호출을 해야만 하는 기능들이고 위의 동그라미는 캐시 유지 시간 설정으로 봐주시면 되겠습니다.
이제 다음의 몇가지 예시 상황들에 대한 캐시의 처리 과정에 대해 알아보겠습니다.
1. 한개의 캐시 처리 (makeCache1 → flushCache)
makeCache1이 수행되면 cacheModel에 하나의 캐시가 생성됩니다. 앞으로 makeCache1이 호출될때마다 캐시가 존재하는한 DB에 접근없이 캐시결과값을 제공하게 됩니다. flushCache를 수행하면 캐시가 삭제됩니다. 다시 makeCache1을 호출하면 DB에서 결과를 가져와서 반환함과 동시에 캐시를 생성하게 됩니다. 캐시가 생성된 시점에서 flushInterval에 설정된 시간이 경과하도록 flushCache가 호출되지 않는다면 시간 만료로 자동 삭제됩니다.
2. 두개의 캐시 처리 (makeCache1 → makeCache2 → flushCache)
makeCache1이 호출되면 cacheModel에 하나의 캐시가 생성됩니다. makeCache2가 호출되면 마찬가지로 cacheModel에 또다른 하나의 캐시가 생성됩니다. 이 두개의 캐시는 엄연히 다르며 각각의 makeCacheX가 호출될때 해당하는 만들어진 캐시값을 반환하게 됩니다. 하지만 둘다 모두 동일하게 cacheModel안에 소속됩니다. 이어서 flushCache를 호출하게 되면 두 캐시가 모두 삭제됩니다. 정확히는 flush에 대한 설정을 해두면 해당 캐시모델의 모든 캐시를 소거한다고 보시면 됩니다. 그러므로 이런 부분에 주의하여 캐시모델을 함께 사용할지 따로 다른 캐시모델을 만들지를 결정하셔야 합니다.
3. 인자값의 차이에 따른 처리 (makeCache3[1] -> makeCache3[2] -> flushCache)
makeCache3에는 parameterClass를 사용하여 동적인 쿼리를 수행하도록 되어있습니다. 예시로 간단하게 int값을 받도록 하였는데요. 캐시를 생성할때의 키값에는 이 인자값들이 모두 포함되어 키를 이룹니다. 그러므로 paramterClass로 넘어오는 값이 1일때와 2일때는 다른 쿼리(키)가 됩니다. 그러므로 1이라는 값의 인자를 받아 실행되는 makeCache3의 캐시와 2라는 값을 받아 실행되는 makeCache3는 각각 별개의 캐시가 생성됩니다. 마찬가지로 하나의 cacheModel안에서 호출되지만요. flushCache를 호출하면 이 두캐시가 모두 삭제됩니다.
결론을 내보자면 위와 같은 iBATIS에서 제공하는 기본적인 캐시모델로는 같은 쿼리지만 다른 결과가 나올 수 있는 부분에는 사용할 수 없습니다. SNS 서비스에서 볼 수 있을 다음을 생각해 봅시다.
1. 친구들의 최근근황을 모아서 볼 수 있는 기능이 있다고 가정한다.
2. 사용자가 접속하여 친구들의 최근근황을 확인하였다. [캐시 생성됨]
3. 친구중 한명이 최근 근황을 업데이트 하였다.
4. 사용자가 다시한번 친구들의 최근근황을 확인하였다. [캐시값 반환됨]
2. 사용자가 접속하여 친구들의 최근근황을 확인하였다. [캐시 생성됨]
3. 친구중 한명이 최근 근황을 업데이트 하였다.
4. 사용자가 다시한번 친구들의 최근근황을 확인하였다. [캐시값 반환됨]
위를 수행하였을 때 친구들의 정보가 바뀌어도 사용자는 계속 캐시된 값을 받게됨을 알 수 있습니다. 그러므로 친구들의 업데이트 된 정보를 적시에 얻기가 힘듭니다. 하지만 그렇다고 친구의 정보가 업데이트 될때 다른 사용자의 캐시를 삭제하는데도 무리가 있습니다. 왜냐하면 캐시 키 값을 모르기 때문이죠. 이부분을 해결하려면 iBATIS의 SQL맵 캐시 기능을 사용하지 말고 자체적인 알고리즘으로 구현을 해야 할 것 같습니다.


