
'Database/MS-SQL'에 해당되는 글 5건
- 2009.03.31 서브쿼리, 테이블 생성
- 2009.03.26 [DB] 트리거(trigger)로 로그테이블 만들기
- 2009.03.19 DELETE 와 TRUNCATE
- 2009.03.19 논리합연산자 - WHERE 조건의 동적구성시 OR/UNION ALL을 통한 해결
- 2009.03.13 MSSQL에서 시퀀스 트랜젝션 생성 하는 방법
SUBQUERY
- SUBQUERY의 사용방법과 SUBQUERY에 의해
검색된 데이터 정렬에 대해 알아보자!
-SUBQUERY를 사용할 수 있는 절
. WHERE, HAVING, UPDATE
. INSERT구문의 INTO
. UPDATE구문의 SET
. SELECT나 DELETE의 FROM절
-단일 행 SUBQUERY
단일 행 SUBQUERY는 내부 SELECT문장으로 부터
하나의 행을 검색하는 질의이다.
예문) emp테이블에서 SCOTT의 급여보다 많은
사원의 정보를 사번, 이름, 담당업무, 급여를 출력해 보자
우리가 SCOTT이라는 사람의 급여를 알지 못하므로
두번의 SQL문이 필요하다.
SELECT sal FROM emp WHERE name='SCOTT';
위의 결과를 가지고 다시 조건에 사용 되는
SQL문이 있어야 한다.
SELECT empno,ename,job,sal
FROM emp
WHERE sal > 3000;
위의 경우를 SUBQUERY로 구현을 한다면 다음과 같다.
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal > (SELECT sal
4 FROM emp
5 WHERE ename = 'SCOTT');
문제) emp테이블에서 사번이 7521인 사람의 업무와
같고 급여가 7934보다 많은 사원의 정보를
사번, 이름, 업무, 입사일, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, hiredate, sal
2 FROM emp
3 WHERE job = (SELECT job
4 FROM emp
5 WHERE empno = 7521)
6 AND
7 sal > (SELECT sal
8 FROM emp
9 WHERE empno = 7934);
:: SUBQUERY에서 그룹함수 사용
예문) emp테이블에서 급여의 평균보다 적은 사원의
정보를 사번, 이름, 업무, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal < (SELECT AVG(sal)
4 FROM emp);
:: SUBQUERY에서 HAVING절 사용
예문) emp테이블에서 20번 부서의 최소 급여보다
많은 모든 부서를 출력해보자!
SQL> SELECT deptno, MIN(sal)
2 FROM emp
3 GROUP BY deptno
4 HAVING MIN(sal) > (SELECT MIN(sal)
5 FROM emp
6 WHERE deptno = 20);
문제) emp테이블에서 업무별로 가장 적은 급여의 평균을
출력해 보자! (업무명, 급여의 평균값 순으로 출력)
SQL> SELECT JOB,AVG(sal)
2 FROM emp
3 GROUP BY job
4 HAVING AVG(sal) = (SELECT MIN(AVG(sal))
5 FROM emp
6 GROUP BY job);
:: 다중 행 SUBQUERY연산자
- IN연산자
- ANY연산자
- ALL연산자
- EXISTS연산자
1) IN 연산자
2개 이상의 행을 결과로 받는 SUBQUERY에 대하여
비교 연산자(=,>=...)를 기술하면 ERROR가 발생한다.
이런 경우 SUBQUERY에서 반환되는 모든 행의 값들을
비교하여 QUERY를 수행하는 연산자가 IN이다.
예문) emp테이블에서 업무별로 최소 급여를 받는
사원의 사번, 이름, 업무, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal = (SELECT MIN(sal)
4 FROM emp
5 GROUP BY job);
위는 서브쿼리에서 넘겨지는 결과가 하나의 결과가 아니라
여러개의 결과 이므로 =이라는 연산을 수행하지 못한다.
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal IN (SELECT MIN(sal)
4 FROM emp
5 GROUP BY job);
2) ANY 연산자
2개 이상의 결과를 반화하는 SUBQUERY에 대하여
어떻게 사용하는가를 지정해 두어야 한다.
비교 연산자(=,>=...)와 SUBQUERY 사이에
ANY연산자를 기술하여 반환된 결과 값 모두를 비교한다.
예문) emp테이블에서 30번 부서의 최소 급여를 받는
사원보다 급여를 더 많이 받는 사원의 정보를
사번,이름,업무, 입사일, 급여, 부서번호를 출력 해보자
(단, 30번 부서는 제외)
SQL> SELECT empno,ename,job,hiredate,sal,deptno
2 FROM emp
3 WHERE deptno != 30 AND
4 sal > ANY (SELECT MIN(sal)
5 FROM emp
6 WHERE deptno = 30);
테이블 생성
CREATE TABLE 문장을 실행하여 테이블을 생성한다.
이 문장은 DDL문장으로 오라클 DataBase 구조를 생성,
수정, 삭제 하는데 사용되는 SQL문장이다. 이러한 문장은
DataBase에 즉각 영향을 미치며 DataBase 사전(DATA
DICTIONARY)에 정보를 기록 한다.
문법:
CREATE TABLE [테이블명]
(컬럼명 자료형,...);
이름 규칙
1) 문자로 시작
2) 문자의 길이는 1~30 이내로 사용
3) 오직 A~Z, 0~9, _, $, #만을 사용 가능하다.
4) 동일한 사용자가 소유한 객체 이름은 중복될 수 없다.
5) 예약어를 사용 불가
자료형
1) VARCHAR2(n) :
가변 길이 문자 데이터 (1~4000byte)
2) CHAR(n) :
고정 길이 문자 데이터(1_2000byte)
3) NUMBER(p.s)
전체 p자리 중 소수점 이하 s자리(p: 1~38, s: -84~127)
4) DATE
7byte를 차지하는 세기,년,월,일,시,분,초를 기억하는
날짜 데이터
5) LONG
가변 길이 문자 데이터(1~2Gbyte)
6) CLOB
단일 바이트 가변 길이 문자 데이터(1~4Gbyte)
7) BLOB
가변 길이 이진 데이터(1~4Gbyte)
8) BFILE
가변 길이 외부 파일에 저장된 이진 데이터(1~4Gbyte)
9) RAW(n)
n byte의 원시 이진 데이터(1~2000)
10) LONG RAW
가변 길이 원시 이진 데이터(1~2Gbyte)
예문)
SQL> CREATE TABLE test_T(
2 name VARCHAR2(10),
3 age NUMBER(3),
4 phone VARCHAR2(15),
5 idNum CHAR(14)
6 addr1 VARCHAR2(10)
:: 제약 조건
오라클 서버는 부적절한 자료가 입력되는 것을
방지하기 위하여 constraint를 사용한다.
- 제약 조건은 테이블 LEVEL에서 규칙을 적용한다.
- 제약 조건은 종속성이 존재할 경우
테이블 삭제를 방지 한다.
- 테이블에서 행이 삽입, 갱신, 삭제 될 때마다
테이블에서 규칙을 적용한다.
:: 제약 조건 정의 방법
1) 컬럼 레벨
열(Column)별로 제약 조건을 정의한다.
- 무결성 제약 조건 5가지를 모두 적용 가능 하다.
1. PRIMARY KEY(PK) :
유일하게 테이블의 각 행을 구별한다.(NOT NULL
과 UNIQUE-중복 불가능 조건을 만족 한다.)
2. FOREIGN KEY(FK) :
열과 참조된 열 사이의 외래키 관계를 적용한다.
3. UNIQUE KEY(UK) :
테이블의 모든 행을 유일하게 하는 값을 가진 열
(NULL을 허용)
4. NOT NULL(NN) :
열은 NULL값을 포함할 수 없다.
5. CHECK(CK) :
참(TRUE)이어야 하는 조건을 지정함
(업무 규칙 설정 시)
- NOT NULL제약 조건은 컬럼 LEVEL에서만 가능하다
특정한 열(Column)에 대입되는 값이 절대로
NULL값을 허용해서는 안될때 사용한다.
idNum CHAR(14) CONSTRAINT NOT NULL
2) 테이블 레벨
테이블의 컬럼 정의와는 개별적으로 정의한다.
하나 이상의 열을 참조할 경우에 사용
NOT NULL을 제외한 나머지 제약 조건만 정의 가능하다
:: 테이블 생성 연습 SQL문
SQL> CREATE TABLE test_T(
2 id VARCHAR2(10) CONSTRAINT test_T_pk PRIMARY KEY,
3 name VARCHAR2(10),
4 pwd VARCHAR2(10));
SQL> CREATE TABLE test2_T(
2 hiredate date,
3 license VARCHAR2(20),
4 id VARCHAR2(10) CONSTRAINT test2_t_fk
REFERENCES test_T (id));
위의 내용을 달리 한다면
SQL> CREATE TABLE test2_T(
2 hiredate date,
3 license VARCHAR2(20),
4 id VARCHAR2(10),
5 CONSTRAINT test2_fk FOREIGN KEY (id)
REFERENCES test_T (id));
주의)
FOREIGN KEY값은 MASTER TABLE에서 존재하는
값과 일치해야 하거나 NULL이 되어야 한다.
예문) 다음 테이블 생성 코드를 보고 설명해 보자!
SQL> CREATE TABLE post(
2 post1 CHAR(3),
3 post2 CHAR(3),
4 addr VARCHAR2(60) CONSTRAINT
post_addr_nn NOT NULL,
5 CONSTRAINT post_post12_pk
PRIMARY KEY (post1, post2));
SQL> insert into post values('100','121','서울');
SQL> CREATE TABLE member_T(
2 id VARCHAR2(10) CONSTRAINT
member_T_pk PRIMARY KEY,
3 name VARCHAR2(10) CONSTRAINT
member_T_name_nn NOT NULL,
4 sex CHAR(1) CONSTRAINT
member_T_sex_ck
CHECK (sex IN ('1','2','3','4')),
5 jumin1 CHAR(6),
6 jumin2 CHAR(7),
7 tel VARCHAR2(15),
8 post1 CHAR(3),
9 post2 CHAR(3),
10 addr VARCHAR2(60),
11 CONSTRAINT member_jumin12_uk
UNIQUE (jumin1, jumin2),
12 CONSTRAINT member_post12_fk
FOREIGN KEY (post1, post2)
REFERENCES post (post1, post2));
위와 같이 제약 조건을 걸고 다음과 같이 데이터를
넣게 되면 오류가 발생 한다. 이유는?
SQL> INSERT INTO MEMBER_T VALUES(
'abc','마루치','1','123456','1234567',
'011','100','200','서울');
:: 테이블 생성시 유익한 Tip
emp테이블에서 사번, 이름, 업무, 입사일, 부서번호만
포함하여 emp_temp라는 테이블을 생성해보자
자료들은 포함하지 않고 구조만 생성하자!!
SQL> CREATE TABLE emp_temp
2 AS SELECT empno,ename,job,hiredate,deptno
3 FROM emp
4 WHERE 1 = 2;
확인
SQL> SELECT * FROM emp_temp;
SQL> desc emp_temp;
테이블 수정
:: 새로운 열(Column) 추가
SQL> ALTER TABLE emp_temp
2 ADD (etc VARCHAR2(20));
:: 열(Column) 수정
SQL> ALTER TABLE emp_temp
2 MODIFY (etc CHAR(30));
:: 열(Column)에 제약 조건 추가
SQL> ALTER TABLE emp_temp
2 ADD CONSTRAINT emp_temp_etc_nn
NOT NULL (etc);
주의)
NOT NULL제약 조건은 컬럼 정의 시에만 가능하다.
그러므로 위의 제약 조건 추가 문은 오류가 발생한다.
SQL> ALTER TABLE emp_temp
2 ADD CONSTRAINT emp_temp_etc_uk
UNIQUE (etc);
:: 열(Column)에 제약 조건 삭제
SQL> ALTER TABLE emp_temp
2 DROP CONSTRAINT emp_temp_etc_uk;
:: 사용되는 계정에 따른 제약 조건을 확인하기 위해
다음과 같은 DATA DICTIONARY를 통해 확인한다.
SQL> SELECT constraint_name,table_name,status
2 FROM user_constraints;
:: 테이블 삭제
SQL> DROP TABLE emp_temp;
아래는 테이블 삭제가 아니라 테이블에 있는 데이터 모두를
삭제하는 문장이다.
SQL> DELETE FROM emp_temp;
[출처] 서브쿼리, 테이블 생성|작성자 자바강지
특정 테이블(DATA_TBL)에 대해서 트리거를 걸고,
해당 이벤트를 기록하는 테이블(LOG_TBL) 이 존재한다고 할때, 테이블당 하나씩
트리거를 걸면 되므로 심플하게 되는데...
종종 이런로그를 쌓을때, 특정 자료들을 가공해서 써야 할때가 있습니다.
| 게시판코드 | 게시판번호 | 제목 | 본문 |
| BBS_001 | 0001 | 테스트제목1 | 본문입니다 |
| BBS_001 | 0002 | 테스트제목2~ | 본문2 |
| BBS_004 | 001 | 어때..이힝 | 정민철 메롱 |
다수의 게시판이 아니라,
하나의 게시판에 게시판 코드로 구분되어 만들어 지는 경우...
게시판 코드가 아니라...
BBS_001 , BBS_002, BBS_003 게시판은 ===> 멀티미디어게시판
BBS_004 , BBS_005, BBS_006 게시판은 ===> 텍스트게시판
나머지 ===> 기타게시판
뭐 묶음으로 로그를 남긴다고 해야하나??
아니면 분류를 새로 해서 로그를 남긴거나 아무튼 이런겁니다.
[샘플예제]
오라클기준으로 작성하였답니다
> KONAN_TEST (트리거가 걸릴 테이블)
| BBS_CODE | TITLE | BODY |
> KONAN_TEST_LOG (KONAN_TEST의 로그가 쌓일곳)
| LOGID (로그고유번호 rowid로함) | TABLENAME (해당 테이블명) | EVENT (업데이트, 삽입, 삭제) |
> kw_logtest
TRIGGER kw_logtest
AFTER INSERT OR DELETE OR UPDATE ON KONAN_TEST
FOR EACH ROW
DECLARE
tbl_name VARCHAR2(30) := ''; --테이블명
BEGIN
-- 테이블코드 가져오기
IF INSERTING THEN
IF (UPPER(:new.BBS_CODE) in ('BBS_01', 'BBS_02', 'BBS_03')) THEN
tbl_name := '게시판1-3';
ELSIF (UPPER(:new.BBS_CODE) in ('BBS_04', 'BBS_05', 'BBS_06')) THEN
tbl_name := '게시판4-6'
ELSE
tbl_name := '기타게시판';
END IF;
ELSE
IF (UPPER(:old.BBS_CODE) in ('BBS_01', 'BBS_02', 'BBS_03')) THEN
tbl_name := '멀티미디어게시판';
ELSIF (UPPER(:old.BBS_CODE) in ('BBS_04', 'BBS_05', 'BBS_06')) THEN
tbl_name := '게시판1-3';
ELSE
tbl_name := '게시판4-6'
END IF;
END IF;
--실제로그쌓기
IF INSERTING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:new.rowid, tbl_name ,'I');
ELSIF DELETING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:old.rowid, tbl_name, 'D');
ELSIF UPDATING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:old.rowid,tbl_name, 'U');
END IF;
END;
[테스트결과]
| 단계1. 삽입(Insert) | 단계2. 수정(Update) | 단계3. 삭제(Delete) |
|
|
|
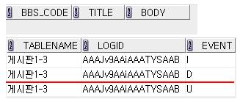 |
이런식으로 로그테이블에 해당 이벤트와 BBS_CODE가 아닌
재정의한 게시판 1-3 같은내용이 들어가는것!
하지만 같은기능을 두개의 명령어로 사용할 필요는 없겠죠?
그래서 두 명령어의 차이점에 대해 알아보겠습니다.
TRUNCATE는 DDL, DELETE 는 DML 입니다.
DDL(Data Definition Language)은 데이터를 정의하는 언어로서 개체를 만들고 변경, 삭제하는 CREATE, ALTER, DROP문과 같은 것들을 말합니다.
DML(Data Manipulation Language)은 데이터 조작 언어로서 데이터를 가공하는 SELECT, INSERT, UPDATE, DELETE문과 같은 것들을 말합니다
구문은 다음과 같습니다.
[TRUNCATE 구문]
[DELETE 구문]
[ WITH <common_table_expression> [ ,...n ] ]
DELETE [ TOP ( expression ) [ PERCENT ] ] [ FROM ] { <object> | rowset_function_limited [ WITH ( <table_hint_limited> [ ...n ] ) ] }
[ <OUTPUT Clause> ]
[ FROM <table_source> [ ,...n ] ]
[ WHERE { <search_condition> | { [ CURRENT OF { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ]
[ OPTION ( <Query Hint> [ ,...n ] ) ] [; ]
<object> ::=
{ [ server_name.database_name.schema_name. | database_name. [ schema_name ] . | schema_name. ] table_or_view_name }
구문만 보더라도 TRUNCATE는 DELETE보다 간단한걸 볼 수 있습니다.
간단하다는 말은 TRUNCATE는 단순한 조건일 것이고 DELETE는 다양한 조건이 가능하다고 추측할 수 있습니다.
그럼 MSDN에서 두 명령어에 대해 비교해놓은 내용을 참고로 보겠습니다.
DELETE 문과 비교하여 TRUNCATE TABLE에는 다음과 같은 이점이 있습니다.
- 트랜잭션 로그 공간을 덜 사용합니다.
DELETE 문은 행을 한번에 하나씩 제거하고 삭제된 각 행에 대해 트랜잭션 로그에 항목을 기록합니다. 반면 TRUNCATE TABLE은 테이블의 데이터를 저장하는 데 사용되는 데이터 페이지의 할당을 취소하는 방식으로 데이터를 제거하며 페이지 할당 취소만을 트랜잭션 로그에 기록합니다.
- 일반적으로 적은 수의 잠금이 사용됩니다.
행 잠금을 사용하여 DELETE 문을 실행하면 삭제를 위해 테이블의 각 행이 잠깁니다. TRUNCATE TABLE은 항상 테이블과 페이지를 잠그지만 각 행은 잠그지 않습니다.
- 빈 페이지는 예외 없이 테이블에 남습니다.
DELETE 문이 실행된 후에도 테이블은 계속 빈 페이지를 포함할 수 있습니다. 예를 들어 힙의 빈 페이지는 최소한 배타적인(LCK_M_X) 테이블 잠금이 있어야만 할당 취소할 수 있으므로 삭제를 위해 테이블 잠금을 사용하지 않는 경우 테이블(힙)에는 빈 페이지가 많이 남게 됩니다. 인덱스의 경우도 삭제 작업 후에 빈 페이지가 남을 수 있지만 이러한 페이지는 백그라운드 정리 프로세스에 의해 신속하게 할당 취소됩니다.
TRUNCATE TABLE은 테이블에서 모든 행을 제거하지만 테이블 구조와 테이블의 열, 제약 조건, 인덱스 등은 그대로 남습니다. 테이블 정의 및 테이블의 데이터를 제거하려면 DROP TABLE 문을 사용하십시오.
테이블에 ID 열이 포함되어 있으면 해당 열의 카운터는 열에 대한 초기값으로 다시 설정됩니다. 초기값이 정의되어 있지 않으면 기본값인 1이 사용됩니다. ID 카운터를 보존하려면 DELETE를 대신 사용하십시오.
친절하게도 MSDN에 자세하게 설명이 되어있군요 글을 읽어보면 금방 이해가 될것이라 생각이 듭니다.
여기서 마지막 내용으로 예제를 만들어 보도록 하겠습니다.
먼저 테이블을 생성하도록 하겠습니다.
CREATE TABLE TABLENAME
( A INT IDENTITY ,B INT )
자동증가값을 가지는 A 컬럼, 정수형의 B 컬럼이 있는 TABLENAME이라는 테이블을 생성하였습니다.
INSERT INTO TABLENAME VALUES(1)
INSERT INTO TABLENAME VALUES(2)
INSERT INTO TABLENAME VALUES(3)
입력 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
1 1
2 2
3 3
DELETE문을 이용해서 전체를 삭제후 다시 입력을 해보겠습니다.
DELETE FROM TABLENAME
INSERT INTO TABLENAME VALUES(4)
INSERT INTO TABLENAME VALUES(5)
INSERT INTO TABLENAME VALUES(6)
처리된 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
4 4
5 5
6 6
(3개 행 적용됨)
전체 삭제후 새롭게 입력을 했을때 자동증값은 삭제된 항목의 최대값 다음의 증가값으로 입력된걸 확인할 수 있습니다.
이번엔 TRUNCATE문을 이용해서 삭제후 다시 입력을 해보겠습니다.
TRUNCATE TABLE TABLENAME
INSERT INTO TABLENAME VALUES(7)
INSERT INTO TABLENAME VALUES(8)
INSERT INTO TABLENAME VALUES(9)
처리된 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
1 7
2 8
3 9
(3개 행 적용됨)
자동증가값이 초기값이 되고나서 증가되었음을 확인할 수 있습니다.
이제 이해가 좀 쉽게되시죠? ^^
하지만 TRUNCATE문의 단점도 있습니다.
DELETE문은 WHERE절을 이용하여 조건을 사용할 수 있지만 TRUNCATE는 조건을 사용할 수 없습니다.
그리고 DDL이기 때문에 사용권한 문제도 있습니다.(아래는 MSDN에 있는 사용권한 내용입니다.)
최소한 table_name에 대한 ALTER 권한이 필요합니다. TRUNCATE TABLE 권한은 테이블 소유자, sysadmin 고정 서버 역할 및 db_owner 및 db_ddladmin 고정 데이터베이스 역할의 기본 권한이며 위임할 수 없습니다. 하지만 저장 프로시저와 같은 모듈 내에 TRUNCATE TABLE 문을 통합한 뒤 EXECUTE AS 절을 사용하여 적절한 권한을 모듈에 허용할 수 있습니다. 자세한 내용은 EXECUTE AS를 사용하여 사용자 지정 권한 집합 만들기를 참조하십시오
TRUNCATE를 사용하기위한 제한 사항들도 있습니다.(아래는 MSDN에 있는 제한사항 내용입니다.)
다음과 같은 테이블에서는 TRUNCATE TABLE 문을 사용할 수 없습니다.
- FOREIGN KEY 제약 조건에 의해 참조됩니다. 자신을 참조하는 외래 키가 있는 테이블을 잘라낼 수 있습니다.
- 인덱싱된 뷰에 참여합니다.
- 트랜잭션 복제 또는 병합 복제에 의해 게시됩니다.
이런 특징을 한 개 이상 갖고 있는 테이블의 경우 DELETE 문을 대신 사용하십시오.
TRUNCATE TABLE은 개별 행 삭제를 기록하지 않기 때문에 트리거를 실행할 수 없습니다. 자세한 내용은 CREATE TRIGGER(Transact-SQL)를 참조하십시오.
어느게 좋다 나쁘다 이런문제가 아닙니다. 사용목적에 따라 적절하게 사용하시는게 최선이라고 생각합니다.
MSDN참조 경로 : (http://msdn.microsoft.com/ko-kr/library/ms177570.aspx)
PURPOSE
WHERE조건의 동적구성에 따른 OR 또는 UNION ALL 활용(실행계획분리) 방안 이해
SCOPE & APPLICATION
실무에서는 프로그램 변수 값에 따라서 SQL WHERE 조건을 달리 가지고 가는 경우를 흔히 볼 수 있다. 예를 들어,
if (sw = 0) strSQL = “SELECT EMPNAME, SAL FROM EMP WHERE SAL > 2000000
else strSQL = “SELECT EMPNAME, SAL FROM EMP WHERE SAL > 2000000 AND DEPTNO = 1
와 같이 sw 값에 따라 SQL이 동적으로 구성되는 경우이다. 이러한 프로그램 방식은 dynamic SQL을 이용하는 방식으로서 변수 값에 따라 최적의 SQL을 만들어 낼 수 있는 장점이 있는 반면, 변수 값이 바뀜에 따라서 계속적인 SQL 파싱이 일어나 메모리 overhead가 많을 뿐 아니라 수행속도도 떨어진다는 것이다.
그래서, 본 topic에서는 OR이나 UNION ALL을 이용하여 dynamic SQL의 장점을 취하면서 단점을 보완할 수 있는 방법을 실무예제를 통해서 알아본다.
KEY IDEA
논리합연산자, OR, UNION ALL, 실행계획분리, dynamic SQL
SUPPOSITION
다음은 모 통신회사에서 고객에 대한 개통 회선정보를 보고자 하는 perl 프로그램의 일부이다.
if($link eq '0') { $query_link = "";
} else { $query_link = "AND publlink=$link"; }
………
$query1 = "
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,lineband
FROM publ,line
WHERE publnumb > 1000 $query_link
AND publnumb=linenumb AND to_char(linelast,'yyyymm')=?";
$cursor1 = $dbh->prepare("$query1");
$cursor1->execute;
- 인덱스 : PUBL_PK = publnumb, LINE_PK = linenumb+lineused+lineband
- publlink : 회선지역을 나타내는 코드성 컬럼
위 프로그램에서는 변수 $link 값에 따라서 SQL 구성이 달라진다. 즉, dynamic SQL을 사용한다. 이것을 static SQL로 고쳐서 parsing overhead도 줄이면서 수행속도도 보장 받을 수 있는 방안은 무엇인가?
DESCRIPTION
위 SQL의 내용을 살펴보면, $link 값이 0이면 “AND publlink=$link” 조건을 체크하지 말고, 0가 아니면 “AND publlink=$link” 조건을 체크하여 질의결과를 구하라는 의미의 dynamic SQL이다. 이것을 static SQL로 바꾸기 위한 방법은 대체로 3가지 정도의 방법이 있다.
1. OR 이용
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND (? = 0 OR (? != 0 AND publlink = ?))
2. UNION ALL 이용
SELECT *
FROM ( SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND ? = 0
UNION ALL
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND ? != 0 AND publlink = ? )
3. DECODE() 함수 이용
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,lineband
FROM publ,line
WHERE publnumb > 1000 AND nvl(publlink,0) = decode(?,0,nvl(publlink,0),?)
AND publnumb = linenumb AND to_char(linelast,'yyyymm') = ?
이 3가지 방법 중 어떤 방법을 선택하느냐?에 있어서 반드시 고려해야 할 사항이 있다. 그것은 dynamic WHERE 조건이 주관조건(driving condition)이 되느냐의 여부이다. 위 SQL에서는 dynamic WHERE 조건을 구성하는 컬럼인 publlink가 분포도가 안 좋은 코드성 컬럼이기 때문에 publ 테이블의 PK인 publnumb의 조건이나 line 테이블의 linelast의 조건이 주관조건이 되고 dynamic WHERE 조건은 체크조건으로 활용될 것이다. 그러므로, 1,2,3 중 어떤 방법을 이용하더라도 수행속도에 큰 차이는 없다.
그러나, publlink가 분포도가 좋은 컬럼으로 인덱스가 잡혀 있어 주관조건으로 사용된다면 1번과 3번 방법은 사용하지 않는 것이 좋다. 1번(OR이용) 방법의 경우, ‘(? = 0 OR (? != 0 AND publlink = ?))’ 조건에서 ‘(? != 0 AND publlink = ?)’ 조건은 publlink 인덱스를 사용하겠지만 ‘? = 0’ 조건은 publlink 인덱스를 사용하지 않으므로 full scan 방식을 택할 수 밖에 없다. (Index scan OR full scan)은 full scan 이므로 1번 방법은 변수 $link 값에 무엇이 들어오든 full scan 실행계획이 수립되어 전체 SQL 수행속도를 떨어뜨릴 것이다. 3번(DECODE()사용) 방법의 경우, ‘nvl(publlink,0) = decode(?,0,nvl(publlink,0),?)’ 조건은 좌변이 가공되어 있으므로 publlink 인덱스를 원척적으로 사용할 수 없다. 또한, $link 조건이 보다 복잡하게 들어올 경우는 DECODE()문이 복잡해져서 구현하기도 쉽지 않다. 그러므로, 2번(UNION ALL사용) 방법을 사용해야 한다. 이러한 방법을 ‘분리실행계획’을 세운다고 하는데, 문제에서 $link 값에 0이 들어오면 full scan을 하고 0이외의 값이 들어오면 index scan을 하므로 각각의 경우에 따라 최적의 실행계획을 보장받을 수 있다.
이와 같이, dynamic SQL을 bind variable을 사용하는 static SQL로 바꾸는 방법은 다양하게 존재하나 dynamic WHERE 조건이 전체 SQL에 어떤 성격의 조건으로 활용되느냐에 따라서 신중하게 생각해서 선택해야 한다.
MSSQL에서 시퀀스 트랜젝션 생성 하는 방법이 3가지
(@@IDENTITY ,IDENT_CURRENT,SCOPE_IDENTITY)
Returns the last identity value generated for a specified table in any session and any scope.
Syntax
IDENT_CURRENT('table_name')
Arguments
table_name
Is the name of the table whose identity value will be returned. table_name is varchar, with no default.
Return Types
sql_variant
Remarks
IDENT_CURRENT is similar to the Microsoft® SQL Server™ 2000 identity functions SCOPE_IDENTITY and @@IDENTITY.
All three functions return last-generated identity values.
However, the scope and session on which 'last' is defined in each of these functions differ
IDENT_CURRENT returns the last identity value generated for a specific table in any session and any scope.
@@IDENTITY returns the last identity value generated for any table in the current session, across all scopes.
SCOPE_IDENTITY returns the last identity value generated for any table in the current session and the current scope
2. 종류
SELECT IDENT_CURRENT('table_name')
/* Returns value inserted into t6, which was the INSERT statement 4 stmts before this query.*/
SELECT @@IDENTITY
/* Returns NULL since there has been no INSERT action so far in this session.*/
SELECT SCOPE_IDENTITY()
/* Returns NULL since there has been no INSERT action so far in this scope in this session.*/
3. IDENT_CURRENT('T1') 과 @@IDENTITY 의 차이점
@@IDENTITY는 반드시 입력(INSERT)을 한 후에 정확한 값을 알수 있습니다.
IDENT_CURRENT('T1') 는 입력 하기 전에 알수 가 있습니다.
따라서 @@IDENTITY 는 입력을 한후에 다른 테이블에 똑같은 값을 입력 하기 위해서 사용 하면 됩니다.
트랜 젝션이 많은 서비스에서 이용 가능 하다고 봅니다.
IDENT_CURRENT('T1') 는 전세션에서 접근이 가능 합니다.
그러나 문제는 입력을 하기전에 알수 있기는 하지만 입력을 하기전에 값을 읽어 오고
그값으로 테이블에 입력을 하는경우 문제가 있습니다.
읽고 나서 입력을 하는 사이의 시간에 다른 트렌 젝션이 들어오면 중첩될 확률이 높다는 것입니다.
따라서 트랜 젝션이 많은 서비스에서 이용이 불가능 하다고 봅니다.
4. 결론
@@IDENTITY 나 SCOPE_IDENTITY() 를 이용하며 입력을 먼저 하고 그 값으로 다른 작업을 하는 것이 적절합니다.
오라클도 마찬 가지고 MYSQL도 마찬가지 가 되겠지요 .
오라클은 returning
INSERT INTO emp (empno, ename) VALUES (:empno,:ename)
RETURNING ROWID INTO :rid
mysql은
INSERT INTO person VALUES (NULL, 'Antonio Paz');
INSERT INTO shirt VALUES
(NULL, 'polo', 'blue', LAST_INSERT_ID()), (NULL, 'dress', 'white', LAST_INSERT_ID());
% 사용 용례 ( 두개의 세션을 열고 아래와 같이 작업 해보았다)



