
'Database'에 해당되는 글 38건
- 2010.10.07 sum(decode)참조
- 2010.01.21 오라클에서 not exists, not in, minus의 성능차이
- 2009.03.31 서브쿼리, 테이블 생성
- 2009.03.26 [DB] 트리거(trigger)로 로그테이블 만들기
- 2009.03.19 DELETE 와 TRUNCATE
- 2009.03.19 [SQL] SQL 작성을 위한 표준 지침
- 2009.03.19 논리합연산자 - WHERE 조건의 동적구성시 OR/UNION ALL을 통한 해결
- 2009.03.13 MSSQL에서 시퀀스 트랜젝션 생성 하는 방법
- 편리한 나머지 남용하는 사례가 늘고 있다;
가. NULL값의 처리
- 예의 널 공포증 문제
- 함부로 NVL함수를(특히 행 단위 처리 내에서) 사용하면 비효율이 발생한다.
- NULL 값은 애초에 비교 대상에서 제외되므로, NULL인 행을 선택하는 DECODE가 아니면 NVL을 사용할 필요가 없다.
- SUM(DECODE…) 연산에서는 NULL은 아예 연산에서 제외되므로 굳이 NVL(col, 0)을 사용할 필요가 없다. (NVL을 DECODE 안에 사용하면 쓸데없는 연산이 발생한다.)
- SUM(DECODE…)에서 DECODE로 추출된 행 전체의 값이 NULL이어서 결과가 NULL인 경우, 0으로 표시해주고 싶다면, SUM 바깥에 NVL을 사용해주면 된다.
- 두 개 이상의 열의 연산에 대한 SUM이 필요한 경우
: DECODE문 안에 NVL을 안 쓰면 한 열만 NULL인 행도 연산에서 제외되는 문제 발생
à 각 열의 SUM에 대한 연산으로 전개하면 굳이 NVL을 사용하지 않아도 된다.
- ELSE 부의 값이 0인 경우 SUM에서는 NULL인 경우와 결과가 달라지지 않으므로 굳이 ELSE부를 쓸 이유가 없다. (ELSE부 값이 없으면 NULL처리되므로 수행속도의 차이 발생)
- SUM(DECODE…)에서 가장 부하가 큰 부분은 DECODE 콤보; 부분이다.
- 특히 nested decode는 매우 부하가 크다.
- 수행속도를 위해 DECODE를 단순하게 만들어 줄 필요가 있다.
- 수행속도 절감 사례;
- 여러 열에 대해 계속 다중 DECODE를 쓰는 경우
: 각 열을 하나로 concatnation해서 DECODE하면 하나의 DECODE로 줄일 수 있다. (DECODE 안은 좀 길어지지만;)
- 범위 처리(a : SUM(DECODE(SIGN(b-x), 1, DECODE(SIGN(a-x), -1, y)))
à SUM(DECODE(ABS(a-x)+ABS(b-x), b-a, y))
- 열 조합에 의한 경우의 수가 매우 많은 경우
: 2진분류나 10진분류등 기수법 체계를 활용한다.
- 여러가지 수학함수를 이용해서 최대한 간단한 수학적 모델을 만들어낸다.
- SUM(DECODE…)를 이용해 추출할 열이 많은 경우의 부하를 줄이기 위해 GROUP BY를 사용할 수 있다.
SUM(DECODE(공통수식, 경우1, 값1)), SUM(DECODE(공통수식, 경우2, 값2)), SUM(DECODE(공통수식, 경우3, 값3)), ……
à SUM(DECODE(A, 경우1, 값1)), SUM(DECODE(A, 경우2, 값2)), SUM(DECODE(A, 경우3, 값3)), …... FROM (SELECT 공통수식 A, …… GROUP BY 공통수식)
è 결과값은 뒤의 SQL이 좀더 보기 흉해-_-지지만 수행속도는 훨씬 빠르다.
(GROUP BY를 한 번더 사용하는 성형수술은 부하가 크지 않다.)
- SUM(DECODE…)를 이용해 추출할 열이 많은 경우의 부하를 줄이기 위해 GROUP BY를 사용할 수 있다.
- 개수만 알아내는 데에는 SUM보다 COUNT가 수행속도면에서 훨씬 유리하다. (근데 대체 개수 알아내는데 SUM을 왜 쓰냐? -_-)
- COUNT(특정 열) 보다 COUNT(*)이 더 빠르다.
- *는 ‘모든 열’이 아니라 ‘조건을 만족하는 열에 대한 wild card’의 의미를 가진다.
- 일관성을 지키지 않은 못된-_- 테이블을 처리해야 하는 경우, GROUP BY 연산에서 해당 열이 NULL인 행과 NULL이 아닌 행에 대해 각각 새로운 행이 생성되는 경우가 있다.
à MIN을 이용해 해결한다.
- SUM, AVG등은 숫자에만 가능하지만, MIN, MAX등은 모든 형태에 다 사용 가능하다.
- 뻔한 얘기;
3.3.1. 확장 UPDATE문
- DECODE와 같이 조건 처리를 할 수 없는 DBMS에서는 효용이 적다.
- UPDATE에서 가장 중요한 것은 UPDATE할 대상 집합의 명확화이다.
- UPDATE 구문에서는 WHERE절이 선택하는 집합의 크기가 UPDATE의 작업량을 결정하므로 잘 관리해야 한다.
- WHERE절에 있는 서브쿼리가 먼저 수행되면, 결과물이 상수의 집합이 되므로 WHERE절의 처리 범위를 줄일 수 있다.
- 행을 FETCH해서 가공, 처리, 다시 UPDATE하는 절차적 PL/SQL 프로그래밍 루틴을, UPDATE와 SELECT를 이용해서 하나의 SQL로 만들 수 있다.
- 프로그램 루틴의 SQL화 작업 시 주의점
1. SQL이 매우 커지므로 큰 롤백 세그먼트가 필요하며, 롤백이나 커밋시에 매우 많은 행 이 수정되므로 다른 작업에 영향을 줄 수가 있다.
2. 처리 시에 발생하는 개별 행의 에러를 선별하기가 곤란하다.
3. 하나의 SELECT 가공 결과로 여러 테이블을 UPDATE할 수 없다.
4. 서브쿼리에 조건을 만족하는 값이 하나도 없어 선택된 행이 없는 경우, NULL이 업데 이트 될 수 있다. à 가장 critical한 문제점
è EXISTS루틴 등으로 해결
- Error와 Fail의 차이점 : Error는 SQL이 수행되지 않았을 때, Fail은 수행되었으나 결 과가 공집합일 때 발생한다.
- GROUP함수에서 SQL은 절대 실패하지 않는다. (최소 하나의 행이 생성된다.)
è 실패한 SQL에서는 NVL을 사용해도 NULL 값의 발생을 막을 수 없지만, GROUP 함수와 같이 실패하지 않은 SQL에서는 NVL을 사용해 NULL값을 가공할 수 있다.
5. UPDATE문은 항상 UPDATE되는 테이블이 선행해야 하고, SET 절 내의 서브쿼리는 항상 나중에 반복수행되므로, 서브쿼리에서 가공을 위해 추출해야 하는 행이 많을 때에 는 다중처리 방법을 이용해야 한다.
- 오라클 7.3 이상부터 적용
- 과거에 비해 비교적 자유롭게 조인 뷰에서 INSERT, DELETE, UPDATE를 할 수 있다. (그래도 여전히 제약이 많다.)
- 오라클 7.3부터 FROM절에 하나 이상의 테이블이나 뷰가 위치하는 조인이 된 뷰를 수정할 수 있게 됨
- 제약조건 : DISTINCT, 그룹함수(SUM, AVG등), 집합처리(UNION, INTERSECT등), GROUP BY와 HAVING처리, ROWNUM의 사용, 순환처리(CONNECT BY/START WITH 구문)을 사용한 뷰는 수정할 수 없다.
- 최종 뷰로 병합 가능한 뷰만 수정할 수 있다.
- 조인된 테이블 중에서 키보존 테이블만 수정할 수 있다.
- 조인으로 인해 변화가 일어난 집합의 논리적인 기본키가 자신의 기본키대로 유지되는 테이블 (조인을 했어도 자기 집합의 키 레벨은 변하지 않는 테이블)
- 1:M 조인의 경우 - 조인 결과의 키는 M측 테이블의 키 레벨이 되므로, M측 테이블은 키 레벨이 변하지 않지만, 1측 테이블은 조인 집합을 식별하는 기본키가 될 수 없다.
- M:M 조인의 경우 – 조인 결과는 둘의 Cartesian Product 만큼의 행이 생성 되므로, 두 테이블 모두 키보존 테이블이 될 수 없다. (M:M은 구현 단계에서 나와서는 안되는 구조이므로 별 걱정할 필요 없다-_-)
- 1:1 조인의 경우 – 조인 결과가 양쪽 테이블의 키 레벨과 같으므로, 두 테이블 모두 키보존 테이블이 될 수 있다.
- 키 레벨이 변경되지 않았어도 OUTER JOIN에 의해 생성된 집합에서는 최하위 테이블이 키보존 테이블이 될 수 없는 경우가 있다. (M측 테이블이 OUTER JOIN되는 경우 NULL 필드들이 양산되므로 더 이상 기본키의 역할을 할 수 없다.)
- 조인뷰의 UPDATE에서 WHERE절에는 아무거나 올 수 있지만, SET 절에는 키보존 테이블의 열만 올 수 있다.
- 조인뷰의 DELETE에서는 반드시 단 하나의 키보존 테이블만 가져야 한다.
- 조인뷰의 INSERT는 DELETE와 같이 하나의 키보존 테이블만 가져야 가능하며, 여기에 덧붙여 원 테이블의 제약조건(constraints)을 만족해야 한다. (당연한 얘기;)
이 문제는 오라클만의 문제가 아니고 거의 모든 RDBMS 제품들에 대해 공통적인 문제입니다.
일단 SQL 튜닝에서는 모든 상황에 항상 맞는 것은 없습니다.
즉, SQL 튜닝엔 왕도가 없다는 말입니다. 수학공식 외우듯이 외워서 튜닝을 하는 것은 아니며 그때 그때 데이터의 분포, 서버의 상태, 인덱스의 유무 및 SQL trace나 tkprof결과 등의 각종 참조가능한 수치들을 분석하여 튜닝방향을 정합니다.
상황에 따라 다른 모든 경우엔 가장 안 좋던 방법이 특정 경우엔 최적의 솔루션이 될 수 있습니다.
참고하세요...;
질문의 3가지 + @ 방법의 두드러진 특징만 구별할 수 있어도 판단에 많은 도움이 되겠지요.
A 집합에서 B집합의 데이터를 제외한 나머지만 구하는 방법은 질문의 3가지를 포함하여 상황에 따라 보통 크게 5가지정도를 주로 쓰게 됩니다. 하나씩 특징만 간단히 적겠습니다...자세한 내용은 직접 공부하세요...;
1. not in ...
SELECT * FROM A WHERE a.key not in (SELECT b.key FROM B)
형태의 구문이며, B쪽을 먼저 access하여 b.key로 a.key에 공급자역할을 하는 서브쿼리로 쓰고 싶을 때 주로 사용합니다.
2. not exists ...
SELECT * FROM A WHERE not exists (SELECT * FROM B WHERE b.key = a.key)
형태의 구문이며, A쪽을 먼저 access하고 나서 a의 각 row들을 not exists로 조사하여 filtering하는 처리를 할 때 주로 사용합니다. 즉, B를 access하기 전에 A쪽의 전체범위가 먼저 access됩니다.
이 때의 서브쿼리는 공급자가 아닌 확인자역할만 해 줄 수 있습니다.
3. minus ...
SELECT key, col1, col2 FROM A
MINUS
SELECT key, col1, col2 FROM B
형태의 구문이며, 테스트 해 보면 아시겠지만 MINUS는 특성 상 sort와 중복제거 수행을 동반합니다.
그러므로 가장 이해하기는 간단하나 대용량에서는 사용 시 주의해야 합니다.
A나 B집합의 access대상이 대량인 경우 대량의 sort와 중복제거가 발생하므로 이들 처리에 많은 시간이 소요될 수 있는 쿼리입니다.
4. Outer + Null Check ...
SELECT * FROM A, B WHERE A.key = B.Key(+) AND B.Key IS NULL
형태의 구문이며, 위의 not in이나 not exists가 주로 Nested Loop Join 또는 Nested Loop Anti Join 방법을 수행하는데 비해 대용량의 경우 Hash Join이나 Merge Join을 유도하여 성능을 보장받을 수 있는 방법입니다.
단, 각 DBMS 마다 A LEFT OUTER JOIN B ON ~ , (*)등으로 아우터조인에 대한 표현은 약간 씩 다릅니다.
5. UNION ALL + Group count 또는 count() over() 분석함수 이용등 ...
SELECT *
FROM(
SELECT a.*
, COUNT(DISTINCT gbn) OVER(PARTITION BY key) AS cnt
, COUNT(DISTINCT DECODE(gbn, 'A', 1)) OVER(PARTITION BY key) AS a_cnt
FROM(
SELECT 'A' AS gbn, key, col1, col2 FROM A UNION ALL
SELECT 'B' AS gbn, key, col1, col2 FROM B
) a
)
WHERE cnt < 2 AND a_cnt = 1
형태의 구문이며, UNION ALL은 MINUS와 달리 sort나 중복제거를 하지 않고 별다른 조인도 없기 때문에 양쪽집합에 scan할 마땅한 인덱스가 없거나 하는 상황에서 위력을 발휘할 수 있는 솔루션입니다.
GROUP BY와 COUNT 함수로도 위의 의미를 그대로 만들 수 있습니다...분석함수나 통계함수를 지원하지 않는 DBMS들은 COUNT() OVER() 대신 GROUP BY / COUNT로 변경해야겠지요...;
이외에도 구현할 수 있는 방법들이야 더 있겠지만, 대부분의 상황들에서 위의 예시들이 주로 많이 쓰인다는 것을 거듭 밝힙니다.
SUBQUERY
- SUBQUERY의 사용방법과 SUBQUERY에 의해
검색된 데이터 정렬에 대해 알아보자!
-SUBQUERY를 사용할 수 있는 절
. WHERE, HAVING, UPDATE
. INSERT구문의 INTO
. UPDATE구문의 SET
. SELECT나 DELETE의 FROM절
-단일 행 SUBQUERY
단일 행 SUBQUERY는 내부 SELECT문장으로 부터
하나의 행을 검색하는 질의이다.
예문) emp테이블에서 SCOTT의 급여보다 많은
사원의 정보를 사번, 이름, 담당업무, 급여를 출력해 보자
우리가 SCOTT이라는 사람의 급여를 알지 못하므로
두번의 SQL문이 필요하다.
SELECT sal FROM emp WHERE name='SCOTT';
위의 결과를 가지고 다시 조건에 사용 되는
SQL문이 있어야 한다.
SELECT empno,ename,job,sal
FROM emp
WHERE sal > 3000;
위의 경우를 SUBQUERY로 구현을 한다면 다음과 같다.
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal > (SELECT sal
4 FROM emp
5 WHERE ename = 'SCOTT');
문제) emp테이블에서 사번이 7521인 사람의 업무와
같고 급여가 7934보다 많은 사원의 정보를
사번, 이름, 업무, 입사일, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, hiredate, sal
2 FROM emp
3 WHERE job = (SELECT job
4 FROM emp
5 WHERE empno = 7521)
6 AND
7 sal > (SELECT sal
8 FROM emp
9 WHERE empno = 7934);
:: SUBQUERY에서 그룹함수 사용
예문) emp테이블에서 급여의 평균보다 적은 사원의
정보를 사번, 이름, 업무, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal < (SELECT AVG(sal)
4 FROM emp);
:: SUBQUERY에서 HAVING절 사용
예문) emp테이블에서 20번 부서의 최소 급여보다
많은 모든 부서를 출력해보자!
SQL> SELECT deptno, MIN(sal)
2 FROM emp
3 GROUP BY deptno
4 HAVING MIN(sal) > (SELECT MIN(sal)
5 FROM emp
6 WHERE deptno = 20);
문제) emp테이블에서 업무별로 가장 적은 급여의 평균을
출력해 보자! (업무명, 급여의 평균값 순으로 출력)
SQL> SELECT JOB,AVG(sal)
2 FROM emp
3 GROUP BY job
4 HAVING AVG(sal) = (SELECT MIN(AVG(sal))
5 FROM emp
6 GROUP BY job);
:: 다중 행 SUBQUERY연산자
- IN연산자
- ANY연산자
- ALL연산자
- EXISTS연산자
1) IN 연산자
2개 이상의 행을 결과로 받는 SUBQUERY에 대하여
비교 연산자(=,>=...)를 기술하면 ERROR가 발생한다.
이런 경우 SUBQUERY에서 반환되는 모든 행의 값들을
비교하여 QUERY를 수행하는 연산자가 IN이다.
예문) emp테이블에서 업무별로 최소 급여를 받는
사원의 사번, 이름, 업무, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal = (SELECT MIN(sal)
4 FROM emp
5 GROUP BY job);
위는 서브쿼리에서 넘겨지는 결과가 하나의 결과가 아니라
여러개의 결과 이므로 =이라는 연산을 수행하지 못한다.
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal IN (SELECT MIN(sal)
4 FROM emp
5 GROUP BY job);
2) ANY 연산자
2개 이상의 결과를 반화하는 SUBQUERY에 대하여
어떻게 사용하는가를 지정해 두어야 한다.
비교 연산자(=,>=...)와 SUBQUERY 사이에
ANY연산자를 기술하여 반환된 결과 값 모두를 비교한다.
예문) emp테이블에서 30번 부서의 최소 급여를 받는
사원보다 급여를 더 많이 받는 사원의 정보를
사번,이름,업무, 입사일, 급여, 부서번호를 출력 해보자
(단, 30번 부서는 제외)
SQL> SELECT empno,ename,job,hiredate,sal,deptno
2 FROM emp
3 WHERE deptno != 30 AND
4 sal > ANY (SELECT MIN(sal)
5 FROM emp
6 WHERE deptno = 30);
테이블 생성
CREATE TABLE 문장을 실행하여 테이블을 생성한다.
이 문장은 DDL문장으로 오라클 DataBase 구조를 생성,
수정, 삭제 하는데 사용되는 SQL문장이다. 이러한 문장은
DataBase에 즉각 영향을 미치며 DataBase 사전(DATA
DICTIONARY)에 정보를 기록 한다.
문법:
CREATE TABLE [테이블명]
(컬럼명 자료형,...);
이름 규칙
1) 문자로 시작
2) 문자의 길이는 1~30 이내로 사용
3) 오직 A~Z, 0~9, _, $, #만을 사용 가능하다.
4) 동일한 사용자가 소유한 객체 이름은 중복될 수 없다.
5) 예약어를 사용 불가
자료형
1) VARCHAR2(n) :
가변 길이 문자 데이터 (1~4000byte)
2) CHAR(n) :
고정 길이 문자 데이터(1_2000byte)
3) NUMBER(p.s)
전체 p자리 중 소수점 이하 s자리(p: 1~38, s: -84~127)
4) DATE
7byte를 차지하는 세기,년,월,일,시,분,초를 기억하는
날짜 데이터
5) LONG
가변 길이 문자 데이터(1~2Gbyte)
6) CLOB
단일 바이트 가변 길이 문자 데이터(1~4Gbyte)
7) BLOB
가변 길이 이진 데이터(1~4Gbyte)
8) BFILE
가변 길이 외부 파일에 저장된 이진 데이터(1~4Gbyte)
9) RAW(n)
n byte의 원시 이진 데이터(1~2000)
10) LONG RAW
가변 길이 원시 이진 데이터(1~2Gbyte)
예문)
SQL> CREATE TABLE test_T(
2 name VARCHAR2(10),
3 age NUMBER(3),
4 phone VARCHAR2(15),
5 idNum CHAR(14)
6 addr1 VARCHAR2(10)
:: 제약 조건
오라클 서버는 부적절한 자료가 입력되는 것을
방지하기 위하여 constraint를 사용한다.
- 제약 조건은 테이블 LEVEL에서 규칙을 적용한다.
- 제약 조건은 종속성이 존재할 경우
테이블 삭제를 방지 한다.
- 테이블에서 행이 삽입, 갱신, 삭제 될 때마다
테이블에서 규칙을 적용한다.
:: 제약 조건 정의 방법
1) 컬럼 레벨
열(Column)별로 제약 조건을 정의한다.
- 무결성 제약 조건 5가지를 모두 적용 가능 하다.
1. PRIMARY KEY(PK) :
유일하게 테이블의 각 행을 구별한다.(NOT NULL
과 UNIQUE-중복 불가능 조건을 만족 한다.)
2. FOREIGN KEY(FK) :
열과 참조된 열 사이의 외래키 관계를 적용한다.
3. UNIQUE KEY(UK) :
테이블의 모든 행을 유일하게 하는 값을 가진 열
(NULL을 허용)
4. NOT NULL(NN) :
열은 NULL값을 포함할 수 없다.
5. CHECK(CK) :
참(TRUE)이어야 하는 조건을 지정함
(업무 규칙 설정 시)
- NOT NULL제약 조건은 컬럼 LEVEL에서만 가능하다
특정한 열(Column)에 대입되는 값이 절대로
NULL값을 허용해서는 안될때 사용한다.
idNum CHAR(14) CONSTRAINT NOT NULL
2) 테이블 레벨
테이블의 컬럼 정의와는 개별적으로 정의한다.
하나 이상의 열을 참조할 경우에 사용
NOT NULL을 제외한 나머지 제약 조건만 정의 가능하다
:: 테이블 생성 연습 SQL문
SQL> CREATE TABLE test_T(
2 id VARCHAR2(10) CONSTRAINT test_T_pk PRIMARY KEY,
3 name VARCHAR2(10),
4 pwd VARCHAR2(10));
SQL> CREATE TABLE test2_T(
2 hiredate date,
3 license VARCHAR2(20),
4 id VARCHAR2(10) CONSTRAINT test2_t_fk
REFERENCES test_T (id));
위의 내용을 달리 한다면
SQL> CREATE TABLE test2_T(
2 hiredate date,
3 license VARCHAR2(20),
4 id VARCHAR2(10),
5 CONSTRAINT test2_fk FOREIGN KEY (id)
REFERENCES test_T (id));
주의)
FOREIGN KEY값은 MASTER TABLE에서 존재하는
값과 일치해야 하거나 NULL이 되어야 한다.
예문) 다음 테이블 생성 코드를 보고 설명해 보자!
SQL> CREATE TABLE post(
2 post1 CHAR(3),
3 post2 CHAR(3),
4 addr VARCHAR2(60) CONSTRAINT
post_addr_nn NOT NULL,
5 CONSTRAINT post_post12_pk
PRIMARY KEY (post1, post2));
SQL> insert into post values('100','121','서울');
SQL> CREATE TABLE member_T(
2 id VARCHAR2(10) CONSTRAINT
member_T_pk PRIMARY KEY,
3 name VARCHAR2(10) CONSTRAINT
member_T_name_nn NOT NULL,
4 sex CHAR(1) CONSTRAINT
member_T_sex_ck
CHECK (sex IN ('1','2','3','4')),
5 jumin1 CHAR(6),
6 jumin2 CHAR(7),
7 tel VARCHAR2(15),
8 post1 CHAR(3),
9 post2 CHAR(3),
10 addr VARCHAR2(60),
11 CONSTRAINT member_jumin12_uk
UNIQUE (jumin1, jumin2),
12 CONSTRAINT member_post12_fk
FOREIGN KEY (post1, post2)
REFERENCES post (post1, post2));
위와 같이 제약 조건을 걸고 다음과 같이 데이터를
넣게 되면 오류가 발생 한다. 이유는?
SQL> INSERT INTO MEMBER_T VALUES(
'abc','마루치','1','123456','1234567',
'011','100','200','서울');
:: 테이블 생성시 유익한 Tip
emp테이블에서 사번, 이름, 업무, 입사일, 부서번호만
포함하여 emp_temp라는 테이블을 생성해보자
자료들은 포함하지 않고 구조만 생성하자!!
SQL> CREATE TABLE emp_temp
2 AS SELECT empno,ename,job,hiredate,deptno
3 FROM emp
4 WHERE 1 = 2;
확인
SQL> SELECT * FROM emp_temp;
SQL> desc emp_temp;
테이블 수정
:: 새로운 열(Column) 추가
SQL> ALTER TABLE emp_temp
2 ADD (etc VARCHAR2(20));
:: 열(Column) 수정
SQL> ALTER TABLE emp_temp
2 MODIFY (etc CHAR(30));
:: 열(Column)에 제약 조건 추가
SQL> ALTER TABLE emp_temp
2 ADD CONSTRAINT emp_temp_etc_nn
NOT NULL (etc);
주의)
NOT NULL제약 조건은 컬럼 정의 시에만 가능하다.
그러므로 위의 제약 조건 추가 문은 오류가 발생한다.
SQL> ALTER TABLE emp_temp
2 ADD CONSTRAINT emp_temp_etc_uk
UNIQUE (etc);
:: 열(Column)에 제약 조건 삭제
SQL> ALTER TABLE emp_temp
2 DROP CONSTRAINT emp_temp_etc_uk;
:: 사용되는 계정에 따른 제약 조건을 확인하기 위해
다음과 같은 DATA DICTIONARY를 통해 확인한다.
SQL> SELECT constraint_name,table_name,status
2 FROM user_constraints;
:: 테이블 삭제
SQL> DROP TABLE emp_temp;
아래는 테이블 삭제가 아니라 테이블에 있는 데이터 모두를
삭제하는 문장이다.
SQL> DELETE FROM emp_temp;
[출처] 서브쿼리, 테이블 생성|작성자 자바강지
특정 테이블(DATA_TBL)에 대해서 트리거를 걸고,
해당 이벤트를 기록하는 테이블(LOG_TBL) 이 존재한다고 할때, 테이블당 하나씩
트리거를 걸면 되므로 심플하게 되는데...
종종 이런로그를 쌓을때, 특정 자료들을 가공해서 써야 할때가 있습니다.
| 게시판코드 | 게시판번호 | 제목 | 본문 |
| BBS_001 | 0001 | 테스트제목1 | 본문입니다 |
| BBS_001 | 0002 | 테스트제목2~ | 본문2 |
| BBS_004 | 001 | 어때..이힝 | 정민철 메롱 |
다수의 게시판이 아니라,
하나의 게시판에 게시판 코드로 구분되어 만들어 지는 경우...
게시판 코드가 아니라...
BBS_001 , BBS_002, BBS_003 게시판은 ===> 멀티미디어게시판
BBS_004 , BBS_005, BBS_006 게시판은 ===> 텍스트게시판
나머지 ===> 기타게시판
뭐 묶음으로 로그를 남긴다고 해야하나??
아니면 분류를 새로 해서 로그를 남긴거나 아무튼 이런겁니다.
[샘플예제]
오라클기준으로 작성하였답니다
> KONAN_TEST (트리거가 걸릴 테이블)
| BBS_CODE | TITLE | BODY |
> KONAN_TEST_LOG (KONAN_TEST의 로그가 쌓일곳)
| LOGID (로그고유번호 rowid로함) | TABLENAME (해당 테이블명) | EVENT (업데이트, 삽입, 삭제) |
> kw_logtest
TRIGGER kw_logtest
AFTER INSERT OR DELETE OR UPDATE ON KONAN_TEST
FOR EACH ROW
DECLARE
tbl_name VARCHAR2(30) := ''; --테이블명
BEGIN
-- 테이블코드 가져오기
IF INSERTING THEN
IF (UPPER(:new.BBS_CODE) in ('BBS_01', 'BBS_02', 'BBS_03')) THEN
tbl_name := '게시판1-3';
ELSIF (UPPER(:new.BBS_CODE) in ('BBS_04', 'BBS_05', 'BBS_06')) THEN
tbl_name := '게시판4-6'
ELSE
tbl_name := '기타게시판';
END IF;
ELSE
IF (UPPER(:old.BBS_CODE) in ('BBS_01', 'BBS_02', 'BBS_03')) THEN
tbl_name := '멀티미디어게시판';
ELSIF (UPPER(:old.BBS_CODE) in ('BBS_04', 'BBS_05', 'BBS_06')) THEN
tbl_name := '게시판1-3';
ELSE
tbl_name := '게시판4-6'
END IF;
END IF;
--실제로그쌓기
IF INSERTING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:new.rowid, tbl_name ,'I');
ELSIF DELETING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:old.rowid, tbl_name, 'D');
ELSIF UPDATING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:old.rowid,tbl_name, 'U');
END IF;
END;
[테스트결과]
| 단계1. 삽입(Insert) | 단계2. 수정(Update) | 단계3. 삭제(Delete) |
|
|
|
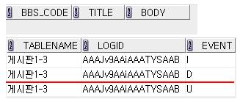 |
이런식으로 로그테이블에 해당 이벤트와 BBS_CODE가 아닌
재정의한 게시판 1-3 같은내용이 들어가는것!
하지만 같은기능을 두개의 명령어로 사용할 필요는 없겠죠?
그래서 두 명령어의 차이점에 대해 알아보겠습니다.
TRUNCATE는 DDL, DELETE 는 DML 입니다.
DDL(Data Definition Language)은 데이터를 정의하는 언어로서 개체를 만들고 변경, 삭제하는 CREATE, ALTER, DROP문과 같은 것들을 말합니다.
DML(Data Manipulation Language)은 데이터 조작 언어로서 데이터를 가공하는 SELECT, INSERT, UPDATE, DELETE문과 같은 것들을 말합니다
구문은 다음과 같습니다.
[TRUNCATE 구문]
[DELETE 구문]
[ WITH <common_table_expression> [ ,...n ] ]
DELETE [ TOP ( expression ) [ PERCENT ] ] [ FROM ] { <object> | rowset_function_limited [ WITH ( <table_hint_limited> [ ...n ] ) ] }
[ <OUTPUT Clause> ]
[ FROM <table_source> [ ,...n ] ]
[ WHERE { <search_condition> | { [ CURRENT OF { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ]
[ OPTION ( <Query Hint> [ ,...n ] ) ] [; ]
<object> ::=
{ [ server_name.database_name.schema_name. | database_name. [ schema_name ] . | schema_name. ] table_or_view_name }
구문만 보더라도 TRUNCATE는 DELETE보다 간단한걸 볼 수 있습니다.
간단하다는 말은 TRUNCATE는 단순한 조건일 것이고 DELETE는 다양한 조건이 가능하다고 추측할 수 있습니다.
그럼 MSDN에서 두 명령어에 대해 비교해놓은 내용을 참고로 보겠습니다.
DELETE 문과 비교하여 TRUNCATE TABLE에는 다음과 같은 이점이 있습니다.
- 트랜잭션 로그 공간을 덜 사용합니다.
DELETE 문은 행을 한번에 하나씩 제거하고 삭제된 각 행에 대해 트랜잭션 로그에 항목을 기록합니다. 반면 TRUNCATE TABLE은 테이블의 데이터를 저장하는 데 사용되는 데이터 페이지의 할당을 취소하는 방식으로 데이터를 제거하며 페이지 할당 취소만을 트랜잭션 로그에 기록합니다.
- 일반적으로 적은 수의 잠금이 사용됩니다.
행 잠금을 사용하여 DELETE 문을 실행하면 삭제를 위해 테이블의 각 행이 잠깁니다. TRUNCATE TABLE은 항상 테이블과 페이지를 잠그지만 각 행은 잠그지 않습니다.
- 빈 페이지는 예외 없이 테이블에 남습니다.
DELETE 문이 실행된 후에도 테이블은 계속 빈 페이지를 포함할 수 있습니다. 예를 들어 힙의 빈 페이지는 최소한 배타적인(LCK_M_X) 테이블 잠금이 있어야만 할당 취소할 수 있으므로 삭제를 위해 테이블 잠금을 사용하지 않는 경우 테이블(힙)에는 빈 페이지가 많이 남게 됩니다. 인덱스의 경우도 삭제 작업 후에 빈 페이지가 남을 수 있지만 이러한 페이지는 백그라운드 정리 프로세스에 의해 신속하게 할당 취소됩니다.
TRUNCATE TABLE은 테이블에서 모든 행을 제거하지만 테이블 구조와 테이블의 열, 제약 조건, 인덱스 등은 그대로 남습니다. 테이블 정의 및 테이블의 데이터를 제거하려면 DROP TABLE 문을 사용하십시오.
테이블에 ID 열이 포함되어 있으면 해당 열의 카운터는 열에 대한 초기값으로 다시 설정됩니다. 초기값이 정의되어 있지 않으면 기본값인 1이 사용됩니다. ID 카운터를 보존하려면 DELETE를 대신 사용하십시오.
친절하게도 MSDN에 자세하게 설명이 되어있군요 글을 읽어보면 금방 이해가 될것이라 생각이 듭니다.
여기서 마지막 내용으로 예제를 만들어 보도록 하겠습니다.
먼저 테이블을 생성하도록 하겠습니다.
CREATE TABLE TABLENAME
( A INT IDENTITY ,B INT )
자동증가값을 가지는 A 컬럼, 정수형의 B 컬럼이 있는 TABLENAME이라는 테이블을 생성하였습니다.
INSERT INTO TABLENAME VALUES(1)
INSERT INTO TABLENAME VALUES(2)
INSERT INTO TABLENAME VALUES(3)
입력 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
1 1
2 2
3 3
DELETE문을 이용해서 전체를 삭제후 다시 입력을 해보겠습니다.
DELETE FROM TABLENAME
INSERT INTO TABLENAME VALUES(4)
INSERT INTO TABLENAME VALUES(5)
INSERT INTO TABLENAME VALUES(6)
처리된 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
4 4
5 5
6 6
(3개 행 적용됨)
전체 삭제후 새롭게 입력을 했을때 자동증값은 삭제된 항목의 최대값 다음의 증가값으로 입력된걸 확인할 수 있습니다.
이번엔 TRUNCATE문을 이용해서 삭제후 다시 입력을 해보겠습니다.
TRUNCATE TABLE TABLENAME
INSERT INTO TABLENAME VALUES(7)
INSERT INTO TABLENAME VALUES(8)
INSERT INTO TABLENAME VALUES(9)
처리된 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
1 7
2 8
3 9
(3개 행 적용됨)
자동증가값이 초기값이 되고나서 증가되었음을 확인할 수 있습니다.
이제 이해가 좀 쉽게되시죠? ^^
하지만 TRUNCATE문의 단점도 있습니다.
DELETE문은 WHERE절을 이용하여 조건을 사용할 수 있지만 TRUNCATE는 조건을 사용할 수 없습니다.
그리고 DDL이기 때문에 사용권한 문제도 있습니다.(아래는 MSDN에 있는 사용권한 내용입니다.)
최소한 table_name에 대한 ALTER 권한이 필요합니다. TRUNCATE TABLE 권한은 테이블 소유자, sysadmin 고정 서버 역할 및 db_owner 및 db_ddladmin 고정 데이터베이스 역할의 기본 권한이며 위임할 수 없습니다. 하지만 저장 프로시저와 같은 모듈 내에 TRUNCATE TABLE 문을 통합한 뒤 EXECUTE AS 절을 사용하여 적절한 권한을 모듈에 허용할 수 있습니다. 자세한 내용은 EXECUTE AS를 사용하여 사용자 지정 권한 집합 만들기를 참조하십시오
TRUNCATE를 사용하기위한 제한 사항들도 있습니다.(아래는 MSDN에 있는 제한사항 내용입니다.)
다음과 같은 테이블에서는 TRUNCATE TABLE 문을 사용할 수 없습니다.
- FOREIGN KEY 제약 조건에 의해 참조됩니다. 자신을 참조하는 외래 키가 있는 테이블을 잘라낼 수 있습니다.
- 인덱싱된 뷰에 참여합니다.
- 트랜잭션 복제 또는 병합 복제에 의해 게시됩니다.
이런 특징을 한 개 이상 갖고 있는 테이블의 경우 DELETE 문을 대신 사용하십시오.
TRUNCATE TABLE은 개별 행 삭제를 기록하지 않기 때문에 트리거를 실행할 수 없습니다. 자세한 내용은 CREATE TRIGGER(Transact-SQL)를 참조하십시오.
어느게 좋다 나쁘다 이런문제가 아닙니다. 사용목적에 따라 적절하게 사용하시는게 최선이라고 생각합니다.
MSDN참조 경로 : (http://msdn.microsoft.com/ko-kr/library/ms177570.aspx)
목 차
1. 개요 6
1.1 목적 6
1.2 범위 6
2. SQL 가이드 라인 7
2.1 SQL TEXT 표준 7
2.1.1 SQL TEXT 7
2.1.2 FROM CLAUSE 8
2.1.3 WHERE CLAUSE 9
2.1.4 SELECT CLAUSE (SELECT LIST) 10
2.2 기타 SQL 구문 11
2.2.1 UPDATE문 11
2.2.2 DELETE문 11
2.2.3 INSERT문 11
2.3 데이터 타입 비교 12
2.3.1 CHAR 타입 12
2.3.2 VARCHAR2 타입 12
2.3.3 NUMBER 타입 12
2.3.4 DATE 타입 13
2.4 인덱스 선정 기준 14
2.4.1 인덱스 선정 기준 14
2.4.2 인덱스 컬럼 선정 기준 14
2.4.3 인덱스 활용 시 주의 사항 (인덱스가 사용되지 않는 경우) 14
2.5 PL/SQL 및 기타 함수 15
2.5.1 PL/SQL의 특징 및 장점 15
2.5.2 PL/SQL 사용 기준 및 유의사항 15
2.5.3 대용량 데이터 처리 기능 16
2.5.4 기타 함수의 사용 19
2.6 SQL TIP 22
2.7 기타 오라클 오브젝트 정책 23
3. 데이터 표준 24
3.1 DB 환경 구성 24
3.1.1 DB 사용자 24
3.1.2 테이블 업무 영역 분류 25
3.1.3 테이블스페이스 25
3.2 NAMING RULE 25
3.2.1 사용자 25
3.2.2 업무영역 26
3.2.3 테이블스페이스 26
3.2.4 테이블 26
3.2.5 임시 테이블 26
3.2.6 컬럼 명 27
3.2.7 주 키 (Primary Key) 27
3.2.8 외래 키 (Foreign Key) 27
3.2.9 인덱스 27
3.2.10 프로시저 28
3.2.11 Function 28
3.2.12 Package 28
1. 개요
본 문서는 @@@ 구축에 필요한 데이터베이스의 표준에 대한 지침을 분석하는 문서입니다.
1.1 목적
본 문서는 개발자들에게 SQL가이드라인을 제시하며 공통된 작성 규칙을 제공함으로써 시스템 성능의 향상 및 개발자들의 업무 수행 능력을 향상을 목적으로 하는 개발자를 위한 문서입니다.
1.2 범위
본 문서에서는 @@@의 SQL 가이드 및 표준에 대한 내용을 정리한 것이다.
본 문서의 구체적인 범위는 아래와 같다.
SQL 가이드
데이터 표준 지침
…..
2. SQL 가이드 라인
2.1 SQL TEXT 표준
2.1.1 SQL TEXT
1) SQL문중 table, column,변수는 소문자로 작성하고 그 이외의 내역은 대문자로 통일하여 작성한다.
2) /* TEST.JAVA */
SELECT aa
FROM table1
WHERE col1 = 'a' 로 SQL구문의 세로줄을 맞추어서 (왼쪽에 맞춘다)
BLOCK 단위로 쉽게 이해할 수 있도록 한다.(탭보다는 스페이스를 이용)
또한 column이나 변수도 KEYWORD 이후 왼쪽 정렬을 하여 맞춘다.
SELECT a
INTO hc_a
FROM test
WHERE aaa = 100;
3) Host 변수는 일반 COLUMN명과 구분하기 위해 아래와 같은 Prefix를 사용한다.
이때 컬럼명은 한글명과 매핑되는 영문명을 사용한다.
SELECT a.col1
변수 명
VARCHAR2 hv_컬럼명
CHAR hc_컬럼명
NUMBER hn_컬럼명
DATE hd_컬럼명
,b.col2
INTO ,hc_col1
,hn_col2
,hd_col3
FROM tab1 a
,tab2 b
WHERE a.col1 = b.col1 [그림 1,1 HOST 변수 예]
AND a.col1 = '1'
GROUP BY a.col1
,b.col2
ORDER BY a.col1
4) 지역변수는 소문자로 전역변수는 첫 글자를 대문자로 한다. (예hc_col1, Hc_col1)
5) SQL구문에 공백 라인이 없도록 작성하며 컬럼과 컬럼 사이,
테이블과 테이블 사이에는 하나의 개행(New Line)을 두어 구분한다. (긴 구문 제외)
SELECT a.col1
,col2
,col3
FROM tab1 a
,tab2 b
WHERE a.col1 = b.col1
6) SQL구문은 가로 최대 길이가 80컬럼 이하가 되도록 작성하여 SQL 튜닝시 또는 유지 보수를 할 때 쉽게 이해할 수 있도록 한다.
8) 긴 구문의 SQL 코딩이 필요하지 않을 경우 6번)을 준수하여 주고 부득이하게 구문이 길 경우에는 8번)의 최대 80라인을 준수하며 단어와 단어 사이에는 한 칸을 띄우고 COMMA(,) 다음에 한 칸을 띄운다
9) 연산자(+,-,*,/,||) 다음에 한 칸을 띄운다.
10) 비교연산자(=,!=,<,>,<=,>=,<>) 다음에 한 칸을 띄운다.
11) 조인의 연결고리가 되는 컬럼의 데이터 타입을 같게 한다.
12) OR절을 가급적 제한해서 사용한다.
13) WHERE 절에 가급적 부정형 조건보다는 긍정적 조건을 사용한다.(<>,NOT BETWEEN, NOT LIKE, NOT IN => =, BETWEEN, LIKE, IN)
14) 불필요한 NVL 함수는 사용하지 않도록 한다.
15) 결과값에 상관없이 OUTER JOIN을 사용하지 않도록 한다.
16) 개발시점에는 튜닝 이전까지는 기본 인덱스(Primary Key)만 유지한다.
17) 개발과정에서 업무 Logic 구현상 최대 일련번호를 구하여야 하는 경우에 한해서 INDEX_DESC 힌트의 사용을 고려하고 그 이외에는 개발과정 중에는 튜닝 이전까지 힌트 사용을 하지 않는 것을 원칙으로 한다.
18) SQL 튜닝의 편의를 위해서 모든 SQL문앞에 주석(REMARK)을 추가한다.
/* 프로그램 소스 ID, 작성자, 작성일자, 프로그램 내 SQL 일련번호 */
예) SELECT /* src1110 홍길동 2007.04.03 1 */ * FROM DUAL;
INSERT /* src1110 홍길동 2007.04.03 2 */ INTO TAB VALUES (1);
2.1.2 FROM CLAUSE
1) DRIVING 순서대로 TABLE을 기술한다.
- 쿼리상에서 기준이 되는 테이블을 좌측에 위치
- CHILD 테이블을 좌측에, PARENT테이블을 우측에 위치
- ROW수가 많은 테이블을 좌측에, ROW수가 적은 테이블을 우측에 위치
2) ALIAS 명칭은 최대한 간단히 a, b, c 등으로 설정하고 (최대 2자리 이니셜)
가장 먼저 DRIVING 되는 TABLE을 a로 설정하고 이후 순차적으로 기술하여 DRIVING 되려는 TABLE의 의도를 쉽게 이해할 수 있도록 한다.
한 SQL 문장에서 같은 ALIAS 명칭을 사용하지 않는다.
테이블이 하나일 경우에는 ALIAS를 지정하지 않는다.
SELECT col1
FROM tab
WHERE col1 = ‘0888’;
3) 하나의 라인에 하나의 TABLE을 나열한다.
4) INLINE VIEW가 있는 경우에는 다음과 같이 "(" 를 맞추어서 기술한다.
SELECT a.col1
,a.col2
,b.col3
,b.col4
FROM (SELECT col1
,col2
FROM tab2
WHERE col3 = '101') a
,tab2 b
WHERE a.col1 = b.col1
AND a.col3 = 'A1101';
(*) INLINE VIEW의 SQL 구문은 표준을 준수한다.
2.1.3 WHERE CLAUSE
1) 기술 요령
ㄱ) ALIAS 명을 기준으로 한 라인에 하나씩 조건절을 기술하고
다음 라인에는 AND부터 기술한다.
쉽게 읽고 이해할 수 있도록 최대한 컬럼을 맞추어서 기술한다.
WHERE a.col2 = b.col2
AND a.col3 = b.col3
AND a.col1 = '101';
ㄴ) 만약 SUB-QUERY가 있는 경우에는 다음과 같이 "(" 를 MAIN-QUERY의
컬럼에 맞춰서 기술한다.
WHERE a.col1 = (SELECT col1
FROM tab2
WHERE col2 = '101')
2) 기술 순서
ㄱ) 조인 문장을 먼저 기술한다. ( 조인되는 순서대로 기술한다. )
ㄴ) 조건 및 범위를 조인 다음에 기술한다.
( 먼저 처리되는 처리 범위부터 순서대로 기술한다. )
ㄷ) ORDER BY 나 GROUP BY 는 WHERE 조건이 아닌 별도 라인에 기술한다.
WHERE a.col2 = b.col2
AND a.col1 = '101‘
GROUP BY a.col2
ORDER BY a.col3
2.1.4 SELECT CLAUSE (SELECT LIST)
1) SELECT-LIST 라인은 다음과 같이 COLUMN명과 ALIAS명을 기술하고, 한 라인에 하나의 컬럼을 기술을 기술하며 세로줄을 맞추어 작성한다.
SELECT a.col1
,a.col2 + a.col3 col2
,b.col4
,b.col5
FROM tab2 a
,b
WHERE a.col2 = b.col2
AND a.col1 = '101'
ORDER BY a.col3
2) ALIAS의 지정은 COLUMN명과 상이한 경우에만 사용하며 “ COLUNM명 ALIAS명 ”으로 기술한다.
SELECT SUM (a.col1) + SUM (a.col2) tot_amt
3) 함수 사용으로 인해 기술 내용이 길어질 경우에는 “(”와 “)” 로 시작과 끝이 쉽게 이해되도록 하고 별도의 ALIAS를 지정한다.
SELECT a.col1
,DECODE (SUBSTR (a.col2
,1
,3
)
,'111', b.col5
,'112', c.col5
,d.col5
) col_sum
FROM tab2 a
,b
WHERE a.col2 = b.col2
AND a.col1 = '101'
ORDER BY a.col3;
4) HINT를 사용하지 않는다.
인덱스 구성이 완료되고 튜닝 시점에 힌트 사용을 허용한다.
5) NOT NULL, PK컬럼에 대해 NVL을 사용하는 등의 불필요한 함수를 사용하지 않도록 한다.
6) SELECT * 구문은 작성하지 않는다.
컬럼 추가, 삭제시 모델의 변경에 대한 대처를 하기 위하여 필요한 컬럼은 모두 기재하도록 한다.
SELECT * ( X : 허용안됨)
FROM TAB
2.2 기타 SQL 구문
2.2.1 UPDATE문
1) 변경 컬럼이 두개 이상일 경우는 ",” 로 나열하며 한 라인에 하나씩 기술한다.
/* AAA001 */
UPDATE tab1
SET col1 = '111'
,col2 = '222'
WHERE col3 = '101'
2) SUB-QUERY와 연결하여 처리될 경우에는 TABLE명에 ALIAS명을 기술하여 컬럼의
모호성(AMBIGOUS)이 발생하지 않도록 한다.
UPDATE tab1 a
SET a.col3 = (SELECT SUM (b.col3)
FROM tab2 b
WHERE a.col1 = b.col1
AND a.col2 = b.col2)
WHERE a.col3 = '101'
3) WHERE 조건 컬럼에 인덱스가 있는지 확인한다.
만약 없으면 TABLE FULL SCAN을 하므로 속도가 저하될 수 있다.
2.2.2 DELETE문
1) 다음과 같이 기술한다.
/* AAA001 */
DELETE FROM tab1
WHERE col1 = '101’
2) WHERE 절에 SUB QUERY도 가능하다.
2.2.3 INSERT문
1) 향후 컬럼 순서 변경이나 추가 시 유연성을 갖고자 INSERT되는 컬럼명을 필히 기술한다. 컬럼과 입력되는 값의 개수를 맞추어 가지런히 정렬한다.
/* AAA001 TEST */
INSERT INTO tab1
(col1
,col2
,col3
)
VALUES (‘101’
,’202’
,SYSDATE
);
잘못된 예)
INSERT INTO TAB1 VALUES (‘A’, 1,2,3);
2.3 데이터 타입 비교
2.3.1 CHAR 타입
1) 고정길이 문자 타입으로 최대 2000 Bytes 까지 입력 가능 (Oracle8 이상)
2) 모든 데이터가 고정길이를 가지는 경우
3) 모든 데이터가 일정한 길이 이상을 가지며 컬럼 길이가 짧은 경우 사용을 고려
4) 컬럼의 길이가 한자리인 경우
5) 가변길이로 지정할 경우 많은 체인(Chain)이 발생이 우려되는 경우 사용을 고려
6) 데이터 길이의 편차가 심한 경우 사용하면 저장공간 낭비와 불필요한 공백까지 네트워크를 타고 이동 등 수행속도가 저하될 수 있음
7) ROW INSERT 시에는 컬럼이 채워지지 않으나 곧 이어 반드시 데이터가 입력되는 경우 사용 고려. CHAR 타입을 사용하더라도 저장공간을 확보해 두려면 테이블 CREATE 시 DEFAULT CONSTRAINT를
‘ .‘ (BLANK)로 지정해 두어야 한다.
2.3.2 VARCHAR2 타입
1) 가변길이 문자 타입으로 최대 4000 Bytes 까지 입력 가능 (Oracle8 이상)
2) 데이터가 가변길이를 가지는 경우
3) 데이터 길이의 편차가 심한 경우
4) NULL로 입력되는 경우
5) 적절한 PCTFREE를 부여하지 않으면 체인(Chain) 발생 가능성이 높음
6) 체인을 감소하기 위해 저장공간을 확보해 두려면 테이블 CREATE 시 DEFAUTL
CONSTRAINT를 원하는 만큼의 ‘ ‘(BLANK)로 지정
7) 체인 감소를 위한 모니터링이나 Re-Org 등에 대한 비용이 CHAR TYPE의 사용보다 비용대비 효과가 크다고 볼 수 있다. (체인 현상 보다 공간 감소 및 성능에 VARCAHR2 TYPE이 효과적)
8) 전체 데이터 용량 감소 효과 지대
8) 가능한 CHAR 타입 보다 VARCHAR2 타입 사용
2.3.3 NUMBER 타입
1) NUMBER(p,s)에서 PRECISION 의 범위는 1 ~ 38, SCALE의 범위는 –84 ~127 까지이며, p 는 s 의 자리수를 포함한 전체 데이터의 길이이고 소수점이하의 값은 반올림되어 저장됨
2)연산이 필요한 컬럼에 사용
3) NUMBER 타입의 컬럼이 문자 값과 비교되면 문자를 숫자로 바꾸어 비교하므로 인덱스를 사용하지 않게 되므로 인덱스로 생성할 컬럼은 가능한 문자타입을 사용
4) NUMBER 타입으로 지정된 컬럼을 LIKE ‘char%’ 로 비교하면 인덱스를 사용할 수 없음 (내부적 변형이 발생)
5) 가변길이 이므로 충분하게 지정하여 사용한다. (Default 22 Byte)
6)기본키(PK)에 포함되는 일련번호는 NUMBER 타입 사용하되 LIKE로 사용되지 않을 경우에만 사용함
2.3.4 DATE 타입
1) YYYYMMDDHH24MISS 일시 [시분초까지 표현]
컬럼명 : INPUT_TIME
입력시 : SYSDATE로 입력한다.
è 컬럼의 변형을 하지 말아야 한다. TO_CHAR(~~,’YYYYMMDD’)
예 (잘못 사용된 경우).
SELECT aa
,bb
,cc
FROM test
WHERE TO_CHAR (aa, 'YYYYMMDD') BETWEEN '20050413‘
AND '20050413’
예 (표준)
SELECT aa
,bb
,cc
FROM test
WHERE aa >= TO_DATE ('20050413')
AND aa < TO_DATE ('20050413') + 1
아래는 위와 동일한 결과를 나타내는 SQL문장이지만 가급적 위 문장을 사용한다.
(1) WHERE AA BETWEEN TO_DATE('20050413')
AND TO_DATE('20050413') + 0.99999
(2) WHERE AA BETWEEN TO_DATE('20050413')
AND TO_DATE('20050413' || '235959','YYYYMMDDHH24MISS')
2) YYYYMMDD 일자 [일자만 표현]
컬럼명 : INPUT_DATE
입력시 : TO_CHAR(SYSDATE,’YYYYMMDD’)로 입력한다.
일자만 있는 타입에서는 아래 SQL이 가능하지만 통일된 SQL문장을 위하여 위와 같이 사용하도록 한다.
SELECT aa
FROM TEST
WHERE aa BETWEEN TO_DATE ('20050413') AND TO_DATE ('20050413')
3) TIMESTAMP 타입 사용
컬럼명 : REGIST_TIME, UPDATE_TIME
입력시 : SYSTIMESTAMP로 입력한다.
입력시
INSERT INTO test
VALUES (SYSTIMESTAMP
)
Select시
SELECT TO_CHAR (a, ' YYYYMMDDHH24MISSFF ')
FROM a
(1) WHERE REGIST_TIME >= TO_DATE('20050413')
AND REGIST_TIME < TO_DATE('20050413') + 1
(2) WHERE UPDATE_TIME = TO_TIMESTAMP(‘20060407150000123456’
, ‘YYYYMMDDHH24MISSFF’)
2.4 인덱스 선정 기준
2.4.1 인덱스 선정 기준
1) 6 블록 이상의 테이블에 적용 (6 블록이하는 연결고리만)
2) 컬럼의 분포도가 10~15% 이내인 경우 적용
3) 분포도가 범위 이내더라도 절대량이 많은 경우에는 단일 테이블 클러스터링 검토
4) 분포도가 범위 이상이더라도 부분범위처리를 목적으로 하는 경우에는 인덱스 적용
5) 인덱스만을 사용하여 요구를 해결하고자 하는 경우는 분포도가 나쁘더라도 적용할 수 있음 (손익분기점)
6) 손익분기점이란 분포도가 10~15%인 경우와 Full Scan 이 같은 경우 Full Scan 과 비교해서 낫다는 것이지 10~15%가 목표는 아님. 데이터가 아주 많은 경우 분포도가1%일지라도 Full Scan 이 더 나을 수 있다
2.4.2 인덱스 컬럼 선정 기준
1) 해당 테이블을 액세스하는 가능한 모든 액세스 형태를 수집
2) 대상 컬럼의 선정 및 분포도 조사
I. 액세스 유형에 자주 등장하는 컬럼
II. 인덱스의 첫번째 컬럼으로 지정해야 할 컬럼
III. 수행속도에 영향을 미칠 것으로 예상되는 컬럼
3) 반복 수행되는 액세스 경로(Critical access path)의 해결
I. 항상 ‘=’로 사용되는 컬럼이 여러 개 있다면 유일성(분포도)이 좋은 컬럼을 먼저 오도록 한다.
4) 클러스터링 검토
5) 매우 좋은 분포도를 가진 컬럼을 독립적인 인덱스로 생성
6) 인덱스 컬럼의 조합 및 순서의 결정
2.4.3 인덱스 활용 시 주의 사항 (인덱스가 사용되지 않는 경우)
1) 비교되기 전에 인덱스 컬럼의 내부적인 변형, 외부적인 변형이 일어나는 경우 -> 비교되는 상대 컬럼(혹은 상수)의 변형하여 인덱스를 사용하게 함
2) 부정형(NOT, <>)으로 조건을 기술한 경우
3) 긍정형으로 바꾸어 인덱스를 사용하게 한다.
4) 인덱스 컬럼이 NULL로 비교되는 경우
5) 컬럼의 값이 NULL 인 로우는 인덱스에 저장되지 않기 때문, 결합 인덱스의 첫번째 컬럼이 아닌 값을 NULL로 비교하는 경우에는 인덱스 사용
6) 옵티마이저가 필요에 따라 상기 적용원칙을 준수했음에도 불구하고 특정 인덱스의 사용을 취사 선택하는 경우
2.5 PL/SQL 및 기타 함수
2.5.1 PL/SQL의 특징 및 장점
1) 프로그래밍 언어 유형과 데이터베이스 유형이 동일하기 때문에 이들 사이에는 변환이 필요 없다.
언어와 데이터베이스 사이의 밀접한 결합에 대한 특성은 다음과 같다.
- 컴파일러가 언어의 변수에 대한 정의 없이 묵시적으로 레코드 유형을 처리
- 쿼리의 열기와 닫기 같은 것들을 자동으로 처리하므로 수행 불필요
- 데이터베이스 오브젝트 변경에 종속되지 않으므로 프로시저 관리에 신경 쓸 필요 없음 (JAVA등 AP는 데이터베이스 오브젝트 변경에 대해서 별도로 수정 작업 수행)
2) PL/SQL 작성은 모든 AP에서 호출하여 사용할 수 있다는 장점이 있다. (JAVA등의 Dynamic SQL 보다 재사용 성 우수)
3) 다른 AP와 다르게 Network I/O의 발생 부담이 적다
4) PL/SQL의 New Feature의 추가 기능에 의하여 부분범위 처리 및 Context Switch등의 획기적인 성능 개선 효과
5) Array Processing 효과 (8i이후 Bulk Collect, Forall 등)로 성능 효과 극대화
2.5.2 PL/SQL 사용 기준 및 유의사항
1) SQL로 처리할 수 있는 부분은 SQL로 처리를 하고 처리가 불가능(Logic이 필요한 경우) 한 부분에 대해서만 코딩 하라.
- JAVA와 같은 Application 프로그램에서의 Logic 처리 보다는 성능의 우월성이 있으나 PL/SQL의 사용은 SQL엔진과 PL/SQL엔진간의 PL/SQL BLOCK에 대한 Context Switch가 발생 (구문 해석을 SQL엔진과 PL/SQL엔진에서 별도로 처리하며 결과값에 대한 Return등에 대한 오버헤드 존재)
- SQL로 처리할 수 있는 경우에는 SQL로 처리하고 SQL로 처리할 수 없는 경우에만 PL/SQL을 사용하는
것을 목표로 한다.
2) 중복 LOOP등 지나치게 절차적인 Logic 처리를 삼가 한다. (단일 행 Fetch, 중첩된 LOOP문 사용 등 , Analytic Function등으로 유도)
3) 코드를 Module 방식으로 작성하라. (각 각의 Module 방식은 가독성을 높이고 구조적인 코딩을 가능하게 한다)
4) Package를 사용하라.
- Package의 사용은 중첩되는 프로시저 (프로시저가 다른 프로시저를 Call하여 사용하는 경우)나 오브젝트의 변경 시에 변경에 대한 영향을 최소화한다. (데이터 베이스 종속성 체인 제거 효과)
- 유사한 기능을 업무단위로 함께 관리하기가 용이하다.
- 세션 지속형 변수를 지원한다.
5) 정적 SQL을 사용할 수 있다면 정적 SQL을 사용하라
6) 대용량 데이터 처리에 대한 효과가 클 때에는 대량처리(Bulk Insert, Bulk Collect, Forall문 등)를 사용하라. 단 메모리의 사용 부담을 고려하여 적은 데이터의 처리시에는 사용을 자제하고 일반 단일 행 처리 PL/SQL을 사용하라. 대량처리 기능은 Context Switch(문맥전환을)를 줄여 주는 조인 효과가 있다.
7) 공통으로 사용하는 부분은 PL/SQL(STORED PROCEDURE/ FUNCTION)을 활용하여 Parsing을 줄여서 메모리의 성능을 최대화 한다.
8) 단일 SQL문으로 처리되는 경우에는 SQL문으로 처리한다.
9) 패키지의 활용을 통해서 프로시저의 종속성을 제거한다. (하위 오브젝트가 INVALID라도 VALID 상태 유지)
10) PL/SQL의 CURSOR 사용시 OPEN과 CLOSE는 반드시 일치 되어야 한다. (OPEN_CURSOR 초과시
신규 프로시저 OPEN 불가)
11) EXCEPTION 처리에 대해서 발생 가능한 모든 EXCEPTION에 대한 정의를 하여야 한다.
12) COMMIT은 가급적 트랜잭션이 완료된 이후에 수행한다.
13) PL/SQL 작성 시 LOOP안에서 CURSOR OPEN/CLOSE를 반복하지 않도록 한다. 불가피하게 LOOP 안에서 CUSRO OPEN를 반복적으로 수행하더라도 해당 CURSOR의 CLOSE는 LOOP 밖에서 한번만 수행되게 함으로써 OPEN시의 반복적인 PARSING을 줄일 수 있다. (PL/SQL 유의 사항 예제)
예) LOOP안에 LOOP를 반복적으로 사용하는 것보다 CURSOR 선언으로 FETCH만 LOOP를 사용할 수 있도록 하는 예
14) %TYPE, %ROWTYPE, REF CURSOR등을 사용하여 테이블의 데이터 타입의 변경에 대비한다. (PL/SQL 블록에서 지정 시 타입이 불일치 하는 경우 발생 가능성 존재)
LOOP
FETCH c1 INTO :v1 :v2
LOOP
FETCH c2 INTO :v21 :v22
LOOP
SELECT xx
FROM tab3 <-------- (1)
WHERE col1 = :v21
AND col2 = :v22;
. . . .
END LOOP;
END LOOP;
END LOOP;
LOOP 내에 (1)처럼 SELECT 문장을 반복 수행하는 것보다는 아래와 같이 커서를 선언하여 사용한다.
DECLARE
CURSOR C1 IS
SELECT .,
.,
FROM tab1 a,
tab2 b,
tab3 c
WHERE a.col1 = b.col2
BEGIN
OPEN c1
LOOP
FETCH c1 INTO :xx
END LOOP;
COMMIT;
END;
2.5.3 대용량 데이터 처리 기능 (PL/SQL New Feature)
8i이전 버전에서 PL/SQL의 기능이 단일 행 처리 (Cursor, Fetch)에 대한 수행만 가능할 때는 대량의 데이터를 처리
하는 것은 성능 악화의 결정적인 요소였던 적이 있었으며, 이에 대한 해결책으로 SQL의 처리로 유도하는 것이 해결책인 적이
있었다.
하지만 PL/SQL에서 대용량 처리를 위한 새로운 기능들이 추가 되었으며 이를 통해서 SQL의 처리와 같은
효과를 보게 되었다.
1) PL/SQL의 성능 저하 요인
PL/SQL 블록에서 SQL문은 SQL엔진으로 넘겨진 후 처리 결과를 다시 PL/SQL 엔진으로 넘겨준다. 이 과정에서 문맥전환 (CONTEXT SWITCH)이 발생한다. 이의 오버헤드는 자원 낭비를 가져온다. 이 경우 BULK BIND으로 변환하여 한 번의 처리에 많은 ROWS를 처리한다면 이런 오버헤드를 최소화 할 수 있다.
따라서 FORALL문을 이용하여 문맥 전환을 줄인다. 이를 통해서 BULK DML (UPDATE, DELETE, INSERT)를 처리를 하면 CONTEXT SWITCH를 줄일 수 있다.
또 한 PL/SQL블록의 성능저하의 주 원인 이였던 FETCH 기능도 BULK CONTEXT를 이용하여 한번에 처리를 하여 CONTEXT SWITCH를 줄여줄 수 있다. 이는 테이블과 테이블의 조인 처리와 같은 효과가 있으며 이런 기능들을 적절하게 활용하면 성능 개선 효과가 크다고 할 수 있다.
2) Bulk Collect
예전 PL/SQL의 단점 중의 하나였던 결과값에 대한 INTO 절의 처리가 단일 행에 대한 처리에 한한다는 한계가 있었으며 이는 PL/SQL의 성능 저하의 요인 이였던 PL/SQL의 Context Switch를 가중시키는 결과가 되어 성능저하의 원인 이였다. 이에 대한 INTO절의 처리를 단일 행이 아닌 배열(Arrary)기능의 BULK Collect라는 기능을 사용하여 INTO문에 대한 배열처리를 가능하게 하였으며 이에 대한 성능 개선 효과는 탁월하다.
예) BULK COLLECT 문 예제
bulk_collect_bind.sql
DECLARE
TYPE Numlist IS TABLE OF emp.empno%TYPE;
Id Numlist;
BEGIN
SELECT empno
BULK COLLECT INTO Id
FROM emp
WHERE sal < 2000
FORALL i IN Id.FIRST ..Id.LAST
UPDATE emp SET sal= 1.1*sal
Where mgr(Id(i);
END;
Numlist라는 type을 empno type으로 선언하고 Numlist를 이용하여 ID라는 변수를 선언하여 Bulk Collect문으로 id 변수에 배열 처리 (SQL구문에서 BULK COLLECT INTO 절에서 사용)
예) BULK COLLECT의 다른 예제
DECLARE
CURSOR all_depts IS
SELECT deptno, dname
FROM dept
ORDER BY dname;
TYPE dept_id IS TABLE OF dept.deptno%TYPE;
TYPE dept_name IS TABLE OF dept.dname%TYPE;
dept_ids dept_id;
dept_names dept_name;
inx1 PLS_INTEGER;
v_InsertStmt VARCHAR2(2000);
BEGIN
OPEN all_depts;
FETCH all_depts BULK COLLECT INTO dept_ids, dept_names;
CLOSE all_depts;
CURSOR문을 이용하여 데이터를 처리하고 테이블의 데이터 타입을 이용하여 TYPE선언을 한 후에 그 TYPE으로 변수를
선언하고 정의된 CURSOR를 열고 선언된 변수에 BULK COLLECT INTO를 이용하여 FETCH작업의 대량 데이터 처리
예 제와 같이 Bulk Collect는 데이터 타입을 지정하고 지정된 데이터 타입으로 변수를 선언하고 그 선언된 변수에 데이터를 Array 처리를 하는 것을 의미하며, 8i이전 버전에서 SELECT INTO 절, FETCH INTO 절에서 단일 행에 대한 처리의 한계를 극복하여 CONTEXT SWITCH문을 줄여서 성능 향상 효과가 있다.
3) Forall
예 전에 FOR문을 이용하여 LOOP를 순환 시키는 형태의 PL/SQL도 Context Switch를 유발하는 유형인데 이에 대해서는 Forall이라는 세 기능을 이용하면 FOR LOOP문 없이 처리가 가능하다. (For Loop문을 한번에 처리하므로 PL/SQL블록의 FOR문을 다시 수행하여 SQL엔진과 Context Switch를 줄여 주어서 한번의 처리로 테이블 조인과 같은 효과를 갖는다)
이는 테이블간의 조인 처리 효과를 갖는다.
/** Load한 데이터의 변형 **/
DECLARE
TYPE Numlist IS TABLE OF emp.empno%TYPE;
Id Numlist;
BEGIN
SELECT empno BULK COLLECT INTO Id
FROM emp
WHERE sal < 2000;
FORALL i IN Id.FIRST..Id.LAST
UPDATE emp SET Sal = 1.1 * Sal
WHERE mgr = Id(i);
END;
위의 구문을 비교해 보면 FORALL문을 이용해서 FOR LOOP문의 처리를 한번에 수행한 예제이며, emp.empno의 데이터
타입을 지정하고 그 데이터 타입으로 변수를 선언하고 선언된 변수의 Array의 첫 번째 row부터 마지막 row까지 FORALL문을
이용하여 한번에 UPDATE문을 처리한다. (테이블 조인 효과, 여러 번의 FOR LOOP을 대체하였다)
4) REF CURSOR
데이터를 CLIENT에 반환하는 것은 REF CURSOR를 이용하면 효율적이다.
REF CURSOR는 PL/SQL로 반환 집합만 정의하면 쉽게 사용할 수 있으며 ARRY SIZE를 적절하게 설정할 수 있으며, 또한
ARRAY SIZE 설정에 따라 데이터 처리에 대한 대기 없이 ARRAY SIZE에 의해 즉사 데이터 값을 반환 받을 수 있는 이점이
있다 (Partial Range Scan 효과)
또한 NETWORK I/O의 감소 효과도 있다. (여러 행의 SQL 대신 한줄의 PROCEDURE만 호출하면 된다)
예) REF CURSOR의 예제
variable a refcursor
variable b refcursor
variable c refcursor
begin
open :a for select empno form emp q1 where ename = 'blake';
open :b for select empno form emp q1 where ename = 'smith';
open :c for select empno form emp q1 where ename = 'james';
end;
예) REF CURSOR의 프로시저 활용 예제
CREATE OR REPLACE PACKAGE CURSOR_PKG AS
TYPE T_CURSOR IS REF CURSOR;
PROCEDURE OPEN_ONE_CURSOR (N_EMPNO IN NUMBER, IO_CURSOR IN OUT T_CURSOR);
PROCEDURE OPEN_TWO_CURSORS (EMPCURSOR OUT T_CURSOR, DEPTCURSOR OUT T_CURSOR);
END CURSPKG;
CREATE OR REPLACE PACKAGE BODY CURSOR_PKG AS
PROCEDURE OPEN_ONE_CURSOR (N_EMPNO IN NUMBER, IO_CURSOR IN OUT T_CURSOR)
IS
V_CURSOR T_CURSOR;
BEGIN
IF N_EMPNO <> 0
THEN
OPEN V_CURSOR FOR
SELECT EMP.EMPNO, EMP.ENAME, DEPT.DEPTNO, DEPT.DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
AND EMP.EMPNO = N_EMPNO;
ELSE
OPEN V_CURSOR FOR
SELECT EMP.EMPNO, EMP.ENAME, DEPT.DEPTNO, DEPT.DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO;
END IF;
IO_CURSOR := V_CURSOR;
END OPEN_ONE_CURSOR;
PROCEDURE OPEN_TWO_CURSORS (EMPCURSOR OUT T_CURSOR, DEPTCURSOR OUT T_CURSOR)
IS
V_CURSOR1 T_CURSOR;
V_CURSOR2 T_CURSOR;
BEGIN
OPEN V_CURSOR1 FOR SELECT * FROM EMP;
OPEN V_CURSOR2 FOR SELECT * FROM DEPT;
EMPCURSOR := V_CURSOR1;
DEPTCURSOR := V_CURSOR2;
END OPEN_TWO_CURSORS;
END CURSPKG;
/
REF CURSOR 로 T_CURSOR TYPE을 선언하고 CURSOR_PKG, OPEN_TWO_CURSORS 프로시저에서 CUSROR
타입을 지정하여 변수 V_CURSOR를 지정하여 REF CURSOR를 사용하도록 하여 V_CURSOR를 OPEN하여 SQL을 실행
하고 실행된 결과를 다시 프로시저에 결과값을 OUT (IO_CURSOR ARGUMENT, T_CURSOR TYPE지정으로 REF
CURSOR TYPE이므로 ARRAY로 처리 가능)
2.5.4 기타 함수의 사용
1) 복잡한 로직으로 수행되는 SQL은 Analytic Function을 활용하여 Logic을 간단하게 처리한다.
아래의 결과의 값은 같지만 처리 비용은 많은 차이가 있으며 데이터의 크기가 커질수록 그 차이는 비례한다.
예) 월별 매출금액과 매출누계를 구하는 예문
SELECT a.월, a.매출금액,
SUM(b.매출금액) AS 매출누계
FROM TEST1 a, TEST1 b
WHERE a.월 >= b.월
GROUP BY a.월, a.매출금액;
Analytic Fuction 변환 예문
SELECT 월, 매출금액,
SUM(매출금액) OVER (PARTITION BY a.월) 매출누계
FROM TEST1 a;
2) DECODE나 CASE문의 적절한 사용은 바람직하지만 과도한 사용은 자제한다.
특히 OR문의 경우를 DECODE문을 이용하여 효율적으로 처리할 수 있는 경우가 있으므로 적절하게 사용한다면 효과적일 수
있다.
OR문을 UNION ALL로 처리할 수 있으며 UNION ALL문을 DECODE문으로 처리할 수 있다.
3) SCALAR QUERY의 활용은 데이터의 범위를 줄여 주고 성능상의 이점이 있으므로 적극적으로 활용하는
좋으나 다음과 같은 경우에는 절대 SCALAR QUERY의 사용을 자제한다.
I. GROUP BY 함수에 의하여 GROUP 함수가 사용되는 경우 (MIN,MAX)
II. SCALAR QUERY내의 데이터 건수가 많은 경우
III. MAIN QUERY의 데이터 건수가 어느 정도 이상일 경우
이 세 가지 (특히 I,II)를 만족하는 경우에는 MAIN QUERY의 데이터가 범위를 줄여 주더라도 SCALAR QUERY 자체가 효과적이지 못하며 해당 GROUP BY 처리 (즉 전체 처리를 MAIN QUERY의 데이터 건수 만큼 처리가 되어서 역효과 발생)
4) MERGE문을 이용하여 UPDATE, INSERT 구문을 효율적으로 처리한다.
(PL/SQL에서 데이터가 있는지 COUNT하여 처리 여부를 결정할 필요가 없으므로 성능 향상 효과가 있다)
예) MERGE 문
merge into bonus D
using (select id,salary from emp) S
on (D.id = S.id)
when matched
then update
set D.bonus=D.bonus + S.salary*0.01
when not matched
then insert(D.id, D.bonus)
values(S.id,S.salary*0.01);
5) SQL 처리시에 많은 부분 중복되는 처리를 하여야 하는 경우가 발생하는데 이에 대한 처리는 기존에는 IN-LINE-VIEW나 VIEW를 생성하여 처리하거나 임시적인 TEMP 테이블을 생성하여 처리하였는데 이를 대신하여 편하게 사용할 수 있는 WITH문을 사용한다.
I. SQL구문 어디서든 지정하면 쉽게 사용할 수 있다.
II. SCALAR QUERY에서 중첩 처리를 가능하게 한다.
III. IN-LINE-VIEW와 다르게 한번 지정하면 반복 사용 가능하다.
WITH V_TARGET
AS(SELECT * FROM T_V_TARGET)
SELECT * FROM V_TARGET
UNION ALL
SELECT * FROM V_TARGET
WHERE ROWNUM = 1;
2.6 SQL TIP
1) 전체자료의 15% 미만인 경우 인덱스를 사용하도록 유도한다.
예)통계 및 현황을 제외하고는 인덱스 사용하도록 한다.
2) WHERE절에서 컬럼을 변형시키지 말아야 한다. 컬럼의 변형이 일어난 경우 인덱스를 사용할 수 없다.(단 Function Based Index인 경우는 제외)
3) 가능하면 Subquery 혹은 Join을 사용하여 하나의 SQL로 작성하도록 한다
4) 조인 후 GROUP BY를 수행하는 것 보다는 GROUP BY를 수행한 후 조인을 실시한다.
5) 결합인덱스와 PK의 순서를 지켜가면서 SQL을 작성하도록 한다. (인덱스 LEADING부문이 가능하면 포함되게 작성)
6) Execution Plan 확인 후 ‘FULL SCAN’이 나타나면 인덱스의 사용 여부와 적절성을 검토하여야 하며, 적절성의 판단이 안 되면 DBA와 상의한다.
(단 FULL SCAN, HASH JOIN이 발생되었다고 모두 잘못된 것은 아니다.)
7) SQL작성 후 PLAN을 항상 확인해 보는 습관을 갖도록 한다.
8) UNION 보다는 UNION ALL을 사용하도록 한다.
9) 가급적이면 SQL상에서 ORDER BY를 사용하지 않는다. Order by를 사용하여야 한다면 인덱스 생성이 필요한지 검토한다 (특히 대용량 테이블인 경우)
10) INSERT, UPDATE, DELETE를 실행후에는 즉시 COMMIT 이나 ROLLBACK을 실행시켜서LOCK을 유발시키지 않도록 한다.
11) 프로그램상에서 DISTINCT 구문의 사용은 자제한다.
12) DML(Insert,Update,Delete)문 처리 후 항상 ROW 컬럼을 확인한다.
13) 컬럼의 변형이 일어나지 않도록 컬럼TYPE에 맞는 형태로 자료를 입력한다.
예) WHERE COL_VAR2 = 123 è WHERE TO_NUMBER(COL_VAR2) = 123
묵시적 변형이 일어난다.
묵시적 변형 우선순위 1) NUMBER > CHAR,VARCHAR2
묵시적 변형 우선순위 2) DATE > CHAR, VARCHAR2
14) SQL구문의 연관성과 업무 Logic을 잘 파악한다. (특히 Subquery에서 EXISTS, IN, NOT IN, NOT EXISTS)
의 특성을 고려하여 적절한 Logic을 구현한다. 가급적이면 긍정문인 IN, EXISTS로 유도한다.
15) REMARK는 반드시 달아 주는 습관이 필요하다. (개발보
2.7 기타 오라클 오브젝트 정책
1) 오라클 함수 (FUNCTION)
- 공통코드명, 품목명, 업체명등 대량의 조인을 회피하기 위하여 사용한다.
- 프로그램에서 처리해야 될 공통 모듈은 Application 프로그램을 이용한다. (계산식)
2) 오라클 프로시져
- 업무와 무관한 일반적인 로직 처리를 위한 프로시져는 사용하지 않는다. (단순 INSERT, UPDATE, DELETE)
- 배치 혹은 대량의 데이터 처리시에 프로시져를 사용하도록 한다.
3) 뷰
- 뷰 대신에 인라인 뷰를 사용하도록 한다.
- 반복적으로 사용되는 SQL이나, 복잡한 SQL을 단순화 시키고자 할 때만 사용한다.
- WITH문으로 대체가 가능한지 고려하여 잘 활용하도록 한다.
4) 시퀀스
- 시퀀스는 성능의 문제나 LOCK의 문제 소지가 있는 곳에서만 사용한다
5) 트리거
- 트리거의 사용은 가급적 사용하지 않는다.
- 여러 테이블의 동시적인 DML작업은 Application 프로그램에서 제어를 하는 것을 원칙으로 한다.
6) 인덱스
- PK인덱스의 순서는 매우 중요하며, 개발 시 필히 염두에 두어야 한다
- Foreign Key(FK)에 대한 인덱스는 자동으로 생성하지 않는다. 프로그래밍시 포린키 인덱스가 필요하다면 추후에 추가하도록 한다.
7) 제약사항
- 포린키(FK) 설정시 제약사항은 물리적으로 반영하도록 한다.(데이터 무결성)
(자식테이블 입력시 부모가 항상 존재하여야 한다)
- 부모-자식간의 삭제 로직은 프로그램에서 직접 제어 하도록 한다
- 컬럼의 Validation 체크는 프로그램에서 제어함을 원칙으로 하되, 확정적인 값에 대해서는 테이블 컬럼에서 valid check를 지원하도록 한다.
- 필수적으로 데이터가 입력되어야 하는 컬럼은 NOT NULL을 지정하고, 프로그램상에서 가능한 NVL()를 사용하지 않도록 한다.
3. 데이터 표준
3.1 DB 환경 구성
3.1.1 DB 사용자
t-MALL DB 계정은 상품, 회원, 거래, 마케팅 등 여러 업무 영역을 하나로 공유할 수 있는 사용자 계정이 필요하며 이에 대해서는 전체의 의미를 파악할 수 있도록 @@@이라는 사용자 계정을 생성한다.
테이블 등에서는 업무 영역 분류를 TM이리고 한다. (이후 추가되는 업무 영역과 구분하기 위함)
계정 계정명 (영문) 설명
@@@ 계정 @@@ @@@의 전체 업무를 하나로 가져 가야 한다는 업무 분석에 따라서 공통 계정 생성
입력, 갱신, 삭제등의 DML 처리
@@@ 관리자 계정 TADMIN @@@의 모든 테이블 생성 및 DROP 권한을 소유한 관리자 계정
@@@ 계정에는 DML 처리 외
테이블의 DDL에 대한 권한은
관리자 계정인 TADMIN에서 수행
3.1.2 테이블 업무 영역 분류
DB 사용자 계정의 업무 영역 분류는 @@@ 공통 계정으로 구성하고 이에 대해서는 약어 명으로 TM이라고
분류한다.
업무 영역 영문명 약어 설명
거래 TRADE TR 거래 업무 영역
마케팅 MARKETING MT 마케팅 업무 영역
상품 PRODUCT PD 상품 업무 영역
커뮤니티 COMMUNITY CM 커뮤니티 업무 영역
회원 MEMBER MB 회원 업무 영역
정산 STALLEMENT ST 정산 업무 영역
TNS TNS TNS TNS 업무 영역
통계 STATISTICS ST 통계 업무 영역
3.1.3 테이블스페이스
@@@ 테이블스페이스는 상품,회원,거래,마케팅 등의 업무를 공통으로 처리할 테이블스페이스와 각 각의 테이블에 대한 파티션 정책에 따른 테이블스페이스를 사용한다.
테이블스페이스 명 구분 테이블스페이스 용도
TSD_@@@ @@@의 공통 데이터 전체 업무처리를 위한 Tablespace
(단 , 코드 성격의 테이블과 대용량
테이블은 제외)
TSI_@@@ @@@의 공통 데이터 인덱스 @@@ 데이터의 인덱스용 테이블스페이스
TSD_TCODE @@@의 코드 성격 테이블 @@@의 코드 성격 테이블스페이스 (DML 데이터와 코드 성격 테이블 분리)
TSI-TCODE @@@ 코드 성격 테이블 인덱스 @@@의 코드 성격 데이터에 대한 인덱스용 테이블스페이스
UNDOTBS1 UNDO 테이블스페이스 UNDO 테이블스페이스
TS_TEMP USER용 Temporary Tablespace 가공 및 Sort를 위해서 할당되는
User용 Temp 테이블스페이스
업무용도에 따라서 통계 업무 및
OLTP 용 TEMP 분리 (성능 측면)
관리 및 공간의 효율성 측면에서는
단일 테이블스페이스 권장
3.2 Naming Rule
3.2.1 사용자
• 사용자는 사용자명을 잘 표현할 수 있는 의미 있는 단어(또는 약어)를 사용한다.
• 사용자는 가급적 1개의 단어(또는 약어)를 사용한다.
• 사용자명은 가급적이면 최대 8자를 넘기지 않도록 한다.
• 사용자명은 테이블스페이스 및 테이블 분류어와 연관이 있는 것을 원칙으로 한다.
예) 상품 : PROD, 마켓 : MARKET, 고객 : CUST
3.2.2 업무영역
업무영역 영문명 약어명
거래 TRADE TR
마케팅 MARKETING MT
상품 PRODUCT PD
커뮤니티 COMMUNITY CM
회원 MEMBER MB
정산 STALLEMENT ST
TNS TNS TNS
통계 STATISTICS ST
3.2.3 테이블스페이스
• 테이블스페이스는 접두사 + ‘_’ 테이블스페이스명 으로 사용한다.
• 테이블스페이스명의 접두사는 ‘TSD_’,’TSI_’로 시작하여야 한다.
• ‘TSD_’는 테이블용 테이블스페이스를 ‘TSI_’는 인덱스용 테이블스페이스를 나타낸다.
• 해당 테이블스페이스 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 30 자를 넘지 않도록 지정한다.
• 테이블스페이스명은 대문자로 표기한다.
• 가급적이면 사용자명을 기준으로 테이블스페이스명을 정하도록 한다.
예) 공통 테이블스페이스 : TSD_COMM
3.2.4 테이블
• 테이블명은 접두사 + ‘_’ + 업무 영역 분류 ‘_’ + 단어 + 단어 형태로 사용한다.
• 테이블명의 접두사는 ‘TB_’를 사용한다.
• VIEW인 경우에는 접미사 ‘_V’를 사용한다.
• 분류는 사용자별 또는 주제별로 적절한 단어를 사용한다.
• 업무 영역 분류 는 의미의 중복이 없는한 가급적 2자 이내의 약어를 사용한다.
• 테이블명은 논리적 의미를 갖는 영문 단어를 이용하여 정의하며, 대문자로 표기 한다.
• 해당 테이블 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 26자를 넘지 않도록 지정한다.
예) 회원정보 마스터 : TB_MB_INFO_MST (MB는 MEMBER의 약어, 회원 업무 분류어 )
상품 View : TB_PD_INFO_MST_V (PD는 PRODUCT의 약어, 상품 업무 분류어 )
3.2.5 임시 테이블
• 테이블명은 [접두사] + ‘_’ + [업무 영역 분류] ‘_’ + 테이블 + 접미사 형태로 사용한다.
• 테이블명의 접미사는 ‘_TMP’를 사용한다.
• 모든 것은 테이블과 동일하며 가급적이면 접두사와 분류의 형식을 지킨다.
• 테이블명은 논리적 의미를 갖는 영문 단어를 이용하여 정의하며, 대문자로 표기 한다.
• 최대 30자를 넘지 않도록 지정한다.
예) 회원정보 마스터 임시 테이블 : TB_MB_INFO_MST_TMP
3.2.6 컬럼 명
• 컬럼명을 잘 표현할 수 있는 단어 또는 약어를 사용한다.
• 논리적 의미를 갖는 영문 단어를 이용하여 정의하며, 컬럼명 모두를 대문자로 한다.
• 컬럼명은 1개 이상의 단어로 구성하며 단어와 단어 사이에는 ‘_’를 사용한다.
• 단어 + ‘_’ + [단어] 형태로 사용한다.
예) ID번호 : IDNO, 등록일자 : RG_DT
3.2.7 주 키 (Primary Key)
• 주 키는 PK + ‘-‘ + 테이블명 로 정의한다.
• 주 키는 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 마스터 : TB_CT_INFO_MST
Primary Key : PK_CT_INFO_MST
3.2.8 외래 키 (Foreign Key)
• 외래 키는 FK + ‘-‘ + 테이블명 로 정의한다.
• 외래 키는 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 마스터 : TB_CT_INFO_MST
Foreign Key : FK_TB_CT_INFO_MST
3.2.9 인덱스
• 인덱스는 IX + ‘일련번호’ + ‘_’ + 테이블 명으로 한다.
• 인덱스는 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 마스터 : TB_CT_INFO_MST
인덱스 : IX1_ CT_INFO_MST, IX2_ TB_CT_INFO_MST
3.2.10 프로시저
• 프로시저명은 접두사 + ‘_’ + 업무 영역 분류 + ‘_’ + 프로시저명 형태로 사용한다.
• 프로시저명의 접두사는 ‘SP_’를 사용한다.
• 업무 영역 분류는 사용자 계정의 약어를 사용한다,
• 프로시저명은 의미를 갖는 영문 단어를 이용하여 정의하며, 대문자로 표기 한다.
• 같은 프로그램 내에서 같은 의미로 프로시저명을 부여하고 싶다면 세 자리 수 일련번호 사용
• 가급적이면 같은 프로그램 내에서도 처리 루틴에 대한 의미 있는 이름을 사용한다.
• 해당 프로시저 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 입력 처리 : SP_MB_INFO_MST_INS
상품 판매 집계 처리 : SP_PD_SALE_RESULT_001, SP_PD_SALE_RESULT_002
SP_MT_SALE_RESULT_TMP, SP_MT_SALE_RESULT_SUM
3.2.11 Function
• Function 접두사 + ‘_’ + 업무 영역 분류 + ‘-‘ + 프로시저명 형태로 사용한다.
• 테이블명의 접두사는 ‘FN_’를 사용한다.
• 모든 것은 프로시저와 동일하다.
예) 회원 최종 접속일자 호출 : FN_MB_LT_CONN_DT
3.2.12 Package
• 패키지 명은 접두사 + ‘_’ + 업무 영역 분류 + ‘_’ + 패키지 명 형태로 사용한다.
• 패키지명의 접두사는 ‘PKG_’를 사용한다.
• 분류는 사용자 계정의 약어를 사용한다,
• 해당 패키지 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 30자를 넘지 않도록 사용한다.
예) 회원 접속 Package : PKG_MB_CONN
[출처] [SQL] SQL 작성을 위한 표준 지침 (사이버 비즈니스 크로스) |작성자 개발팀장
PURPOSE
WHERE조건의 동적구성에 따른 OR 또는 UNION ALL 활용(실행계획분리) 방안 이해
SCOPE & APPLICATION
실무에서는 프로그램 변수 값에 따라서 SQL WHERE 조건을 달리 가지고 가는 경우를 흔히 볼 수 있다. 예를 들어,
if (sw = 0) strSQL = “SELECT EMPNAME, SAL FROM EMP WHERE SAL > 2000000
else strSQL = “SELECT EMPNAME, SAL FROM EMP WHERE SAL > 2000000 AND DEPTNO = 1
와 같이 sw 값에 따라 SQL이 동적으로 구성되는 경우이다. 이러한 프로그램 방식은 dynamic SQL을 이용하는 방식으로서 변수 값에 따라 최적의 SQL을 만들어 낼 수 있는 장점이 있는 반면, 변수 값이 바뀜에 따라서 계속적인 SQL 파싱이 일어나 메모리 overhead가 많을 뿐 아니라 수행속도도 떨어진다는 것이다.
그래서, 본 topic에서는 OR이나 UNION ALL을 이용하여 dynamic SQL의 장점을 취하면서 단점을 보완할 수 있는 방법을 실무예제를 통해서 알아본다.
KEY IDEA
논리합연산자, OR, UNION ALL, 실행계획분리, dynamic SQL
SUPPOSITION
다음은 모 통신회사에서 고객에 대한 개통 회선정보를 보고자 하는 perl 프로그램의 일부이다.
if($link eq '0') { $query_link = "";
} else { $query_link = "AND publlink=$link"; }
………
$query1 = "
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,lineband
FROM publ,line
WHERE publnumb > 1000 $query_link
AND publnumb=linenumb AND to_char(linelast,'yyyymm')=?";
$cursor1 = $dbh->prepare("$query1");
$cursor1->execute;
- 인덱스 : PUBL_PK = publnumb, LINE_PK = linenumb+lineused+lineband
- publlink : 회선지역을 나타내는 코드성 컬럼
위 프로그램에서는 변수 $link 값에 따라서 SQL 구성이 달라진다. 즉, dynamic SQL을 사용한다. 이것을 static SQL로 고쳐서 parsing overhead도 줄이면서 수행속도도 보장 받을 수 있는 방안은 무엇인가?
DESCRIPTION
위 SQL의 내용을 살펴보면, $link 값이 0이면 “AND publlink=$link” 조건을 체크하지 말고, 0가 아니면 “AND publlink=$link” 조건을 체크하여 질의결과를 구하라는 의미의 dynamic SQL이다. 이것을 static SQL로 바꾸기 위한 방법은 대체로 3가지 정도의 방법이 있다.
1. OR 이용
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND (? = 0 OR (? != 0 AND publlink = ?))
2. UNION ALL 이용
SELECT *
FROM ( SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND ? = 0
UNION ALL
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND ? != 0 AND publlink = ? )
3. DECODE() 함수 이용
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,lineband
FROM publ,line
WHERE publnumb > 1000 AND nvl(publlink,0) = decode(?,0,nvl(publlink,0),?)
AND publnumb = linenumb AND to_char(linelast,'yyyymm') = ?
이 3가지 방법 중 어떤 방법을 선택하느냐?에 있어서 반드시 고려해야 할 사항이 있다. 그것은 dynamic WHERE 조건이 주관조건(driving condition)이 되느냐의 여부이다. 위 SQL에서는 dynamic WHERE 조건을 구성하는 컬럼인 publlink가 분포도가 안 좋은 코드성 컬럼이기 때문에 publ 테이블의 PK인 publnumb의 조건이나 line 테이블의 linelast의 조건이 주관조건이 되고 dynamic WHERE 조건은 체크조건으로 활용될 것이다. 그러므로, 1,2,3 중 어떤 방법을 이용하더라도 수행속도에 큰 차이는 없다.
그러나, publlink가 분포도가 좋은 컬럼으로 인덱스가 잡혀 있어 주관조건으로 사용된다면 1번과 3번 방법은 사용하지 않는 것이 좋다. 1번(OR이용) 방법의 경우, ‘(? = 0 OR (? != 0 AND publlink = ?))’ 조건에서 ‘(? != 0 AND publlink = ?)’ 조건은 publlink 인덱스를 사용하겠지만 ‘? = 0’ 조건은 publlink 인덱스를 사용하지 않으므로 full scan 방식을 택할 수 밖에 없다. (Index scan OR full scan)은 full scan 이므로 1번 방법은 변수 $link 값에 무엇이 들어오든 full scan 실행계획이 수립되어 전체 SQL 수행속도를 떨어뜨릴 것이다. 3번(DECODE()사용) 방법의 경우, ‘nvl(publlink,0) = decode(?,0,nvl(publlink,0),?)’ 조건은 좌변이 가공되어 있으므로 publlink 인덱스를 원척적으로 사용할 수 없다. 또한, $link 조건이 보다 복잡하게 들어올 경우는 DECODE()문이 복잡해져서 구현하기도 쉽지 않다. 그러므로, 2번(UNION ALL사용) 방법을 사용해야 한다. 이러한 방법을 ‘분리실행계획’을 세운다고 하는데, 문제에서 $link 값에 0이 들어오면 full scan을 하고 0이외의 값이 들어오면 index scan을 하므로 각각의 경우에 따라 최적의 실행계획을 보장받을 수 있다.
이와 같이, dynamic SQL을 bind variable을 사용하는 static SQL로 바꾸는 방법은 다양하게 존재하나 dynamic WHERE 조건이 전체 SQL에 어떤 성격의 조건으로 활용되느냐에 따라서 신중하게 생각해서 선택해야 한다.
MSSQL에서 시퀀스 트랜젝션 생성 하는 방법이 3가지
(@@IDENTITY ,IDENT_CURRENT,SCOPE_IDENTITY)
Returns the last identity value generated for a specified table in any session and any scope.
Syntax
IDENT_CURRENT('table_name')
Arguments
table_name
Is the name of the table whose identity value will be returned. table_name is varchar, with no default.
Return Types
sql_variant
Remarks
IDENT_CURRENT is similar to the Microsoft® SQL Server™ 2000 identity functions SCOPE_IDENTITY and @@IDENTITY.
All three functions return last-generated identity values.
However, the scope and session on which 'last' is defined in each of these functions differ
IDENT_CURRENT returns the last identity value generated for a specific table in any session and any scope.
@@IDENTITY returns the last identity value generated for any table in the current session, across all scopes.
SCOPE_IDENTITY returns the last identity value generated for any table in the current session and the current scope
2. 종류
SELECT IDENT_CURRENT('table_name')
/* Returns value inserted into t6, which was the INSERT statement 4 stmts before this query.*/
SELECT @@IDENTITY
/* Returns NULL since there has been no INSERT action so far in this session.*/
SELECT SCOPE_IDENTITY()
/* Returns NULL since there has been no INSERT action so far in this scope in this session.*/
3. IDENT_CURRENT('T1') 과 @@IDENTITY 의 차이점
@@IDENTITY는 반드시 입력(INSERT)을 한 후에 정확한 값을 알수 있습니다.
IDENT_CURRENT('T1') 는 입력 하기 전에 알수 가 있습니다.
따라서 @@IDENTITY 는 입력을 한후에 다른 테이블에 똑같은 값을 입력 하기 위해서 사용 하면 됩니다.
트랜 젝션이 많은 서비스에서 이용 가능 하다고 봅니다.
IDENT_CURRENT('T1') 는 전세션에서 접근이 가능 합니다.
그러나 문제는 입력을 하기전에 알수 있기는 하지만 입력을 하기전에 값을 읽어 오고
그값으로 테이블에 입력을 하는경우 문제가 있습니다.
읽고 나서 입력을 하는 사이의 시간에 다른 트렌 젝션이 들어오면 중첩될 확률이 높다는 것입니다.
따라서 트랜 젝션이 많은 서비스에서 이용이 불가능 하다고 봅니다.
4. 결론
@@IDENTITY 나 SCOPE_IDENTITY() 를 이용하며 입력을 먼저 하고 그 값으로 다른 작업을 하는 것이 적절합니다.
오라클도 마찬 가지고 MYSQL도 마찬가지 가 되겠지요 .
오라클은 returning
INSERT INTO emp (empno, ename) VALUES (:empno,:ename)
RETURNING ROWID INTO :rid
mysql은
INSERT INTO person VALUES (NULL, 'Antonio Paz');
INSERT INTO shirt VALUES
(NULL, 'polo', 'blue', LAST_INSERT_ID()), (NULL, 'dress', 'white', LAST_INSERT_ID());
% 사용 용례 ( 두개의 세션을 열고 아래와 같이 작업 해보았다)



