
'분류 전체보기'에 해당되는 글 108건
- 2010.10.07 SQL) 세로를 가로의 데이터로 만들기
- 2010.10.07 sum(decode)참조
- 2010.08.30 Design Pattern 정리 (헤드퍼스트 디자인 패턴)
- 2010.08.30 javascript singleton (자바스크립트 싱글턴)
- 2010.08.30 네이버 OpenAPI 를 AJAX 방식으로 쓰기위한 JSP 프록시 만들기
- 2010.08.27 [펌][교통] 저렴한 일본일주,JAL 재팬 세이버
- 2010.07.13 윈도우에서 openssh를 이용하여 sftp와 ssh운영하기
- 2010.07.13 아파치 웹로그에서 아이피만 뽑아보기
- 2010.06.23 iframe안의 iframe 자바스크립트로 제어하려면..
- 2010.06.22 이미 사용중인 포트입니다. 에러해결 방법
- 2010.06.22 opensymphony oscache 설정
- 2010.06.22 [JAVA] iBATIS + OSCACHE 사용 시 Cache Model에 대한 이해
- 2010.05.17 java velocity 참조..
- 2010.01.29 ASP 에서의 삼항 연산자.
- 2010.01.21 오라클에서 not exists, not in, minus의 성능차이
/* Formatted on 2010/10/07 14:11 (Formatter Plus v4.8.8) */
WITH tmp AS
(SELECT '1' AS col1, 'A' AS col2
FROM DUAL
UNION ALL
SELECT '2' AS col1, '가' AS col2
FROM DUAL
UNION ALL
SELECT '1' AS col1, 'B' AS col2
FROM DUAL
UNION ALL
SELECT '1' AS col1, 'C' AS col2
FROM DUAL)
SELECT col1, LTRIM (SYS_CONNECT_BY_PATH (col2, ','), ',') AS col1
FROM (SELECT col1, col2,
ROW_NUMBER () OVER (PARTITION BY col1 ORDER BY col1) rn,
COUNT (*) OVER (PARTITION BY col1) cnt
FROM tmp)
WHERE LEVEL = cnt
START WITH rn = 1
CONNECT BY PRIOR col1 = col1 AND PRIOR rn = rn - 1;
2) 세로를 가로의 컬럼 데이터로 만들기
/* Formatted on 2010/10/07 16:07 (Formatter Plus v4.8.8) */
WITH tmp AS
(SELECT '1' AS col1, 'a' AS col2
FROM DUAL
UNION ALL
SELECT '2' AS col1, '가' AS col2
FROM DUAL
UNION ALL
SELECT '1' AS col1, 'b' AS col2
FROM DUAL
UNION ALL
SELECT '1' AS col1, 'c' AS col2
FROM DUAL)
SELECT col1, MIN (DECODE (r, 1, col2)), MIN (DECODE (r, 2, col2)),
MIN (DECODE (r, 2, col2))
FROM (SELECT col1, col2,
ROW_NUMBER () OVER (PARTITION BY col1 ORDER BY col2) r
FROM tmp)
GROUP BY col1
- 편리한 나머지 남용하는 사례가 늘고 있다;
가. NULL값의 처리
- 예의 널 공포증 문제
- 함부로 NVL함수를(특히 행 단위 처리 내에서) 사용하면 비효율이 발생한다.
- NULL 값은 애초에 비교 대상에서 제외되므로, NULL인 행을 선택하는 DECODE가 아니면 NVL을 사용할 필요가 없다.
- SUM(DECODE…) 연산에서는 NULL은 아예 연산에서 제외되므로 굳이 NVL(col, 0)을 사용할 필요가 없다. (NVL을 DECODE 안에 사용하면 쓸데없는 연산이 발생한다.)
- SUM(DECODE…)에서 DECODE로 추출된 행 전체의 값이 NULL이어서 결과가 NULL인 경우, 0으로 표시해주고 싶다면, SUM 바깥에 NVL을 사용해주면 된다.
- 두 개 이상의 열의 연산에 대한 SUM이 필요한 경우
: DECODE문 안에 NVL을 안 쓰면 한 열만 NULL인 행도 연산에서 제외되는 문제 발생
à 각 열의 SUM에 대한 연산으로 전개하면 굳이 NVL을 사용하지 않아도 된다.
- ELSE 부의 값이 0인 경우 SUM에서는 NULL인 경우와 결과가 달라지지 않으므로 굳이 ELSE부를 쓸 이유가 없다. (ELSE부 값이 없으면 NULL처리되므로 수행속도의 차이 발생)
- SUM(DECODE…)에서 가장 부하가 큰 부분은 DECODE 콤보; 부분이다.
- 특히 nested decode는 매우 부하가 크다.
- 수행속도를 위해 DECODE를 단순하게 만들어 줄 필요가 있다.
- 수행속도 절감 사례;
- 여러 열에 대해 계속 다중 DECODE를 쓰는 경우
: 각 열을 하나로 concatnation해서 DECODE하면 하나의 DECODE로 줄일 수 있다. (DECODE 안은 좀 길어지지만;)
- 범위 처리(a : SUM(DECODE(SIGN(b-x), 1, DECODE(SIGN(a-x), -1, y)))
à SUM(DECODE(ABS(a-x)+ABS(b-x), b-a, y))
- 열 조합에 의한 경우의 수가 매우 많은 경우
: 2진분류나 10진분류등 기수법 체계를 활용한다.
- 여러가지 수학함수를 이용해서 최대한 간단한 수학적 모델을 만들어낸다.
- SUM(DECODE…)를 이용해 추출할 열이 많은 경우의 부하를 줄이기 위해 GROUP BY를 사용할 수 있다.
SUM(DECODE(공통수식, 경우1, 값1)), SUM(DECODE(공통수식, 경우2, 값2)), SUM(DECODE(공통수식, 경우3, 값3)), ……
à SUM(DECODE(A, 경우1, 값1)), SUM(DECODE(A, 경우2, 값2)), SUM(DECODE(A, 경우3, 값3)), …... FROM (SELECT 공통수식 A, …… GROUP BY 공통수식)
è 결과값은 뒤의 SQL이 좀더 보기 흉해-_-지지만 수행속도는 훨씬 빠르다.
(GROUP BY를 한 번더 사용하는 성형수술은 부하가 크지 않다.)
- SUM(DECODE…)를 이용해 추출할 열이 많은 경우의 부하를 줄이기 위해 GROUP BY를 사용할 수 있다.
- 개수만 알아내는 데에는 SUM보다 COUNT가 수행속도면에서 훨씬 유리하다. (근데 대체 개수 알아내는데 SUM을 왜 쓰냐? -_-)
- COUNT(특정 열) 보다 COUNT(*)이 더 빠르다.
- *는 ‘모든 열’이 아니라 ‘조건을 만족하는 열에 대한 wild card’의 의미를 가진다.
- 일관성을 지키지 않은 못된-_- 테이블을 처리해야 하는 경우, GROUP BY 연산에서 해당 열이 NULL인 행과 NULL이 아닌 행에 대해 각각 새로운 행이 생성되는 경우가 있다.
à MIN을 이용해 해결한다.
- SUM, AVG등은 숫자에만 가능하지만, MIN, MAX등은 모든 형태에 다 사용 가능하다.
- 뻔한 얘기;
3.3.1. 확장 UPDATE문
- DECODE와 같이 조건 처리를 할 수 없는 DBMS에서는 효용이 적다.
- UPDATE에서 가장 중요한 것은 UPDATE할 대상 집합의 명확화이다.
- UPDATE 구문에서는 WHERE절이 선택하는 집합의 크기가 UPDATE의 작업량을 결정하므로 잘 관리해야 한다.
- WHERE절에 있는 서브쿼리가 먼저 수행되면, 결과물이 상수의 집합이 되므로 WHERE절의 처리 범위를 줄일 수 있다.
- 행을 FETCH해서 가공, 처리, 다시 UPDATE하는 절차적 PL/SQL 프로그래밍 루틴을, UPDATE와 SELECT를 이용해서 하나의 SQL로 만들 수 있다.
- 프로그램 루틴의 SQL화 작업 시 주의점
1. SQL이 매우 커지므로 큰 롤백 세그먼트가 필요하며, 롤백이나 커밋시에 매우 많은 행 이 수정되므로 다른 작업에 영향을 줄 수가 있다.
2. 처리 시에 발생하는 개별 행의 에러를 선별하기가 곤란하다.
3. 하나의 SELECT 가공 결과로 여러 테이블을 UPDATE할 수 없다.
4. 서브쿼리에 조건을 만족하는 값이 하나도 없어 선택된 행이 없는 경우, NULL이 업데 이트 될 수 있다. à 가장 critical한 문제점
è EXISTS루틴 등으로 해결
- Error와 Fail의 차이점 : Error는 SQL이 수행되지 않았을 때, Fail은 수행되었으나 결 과가 공집합일 때 발생한다.
- GROUP함수에서 SQL은 절대 실패하지 않는다. (최소 하나의 행이 생성된다.)
è 실패한 SQL에서는 NVL을 사용해도 NULL 값의 발생을 막을 수 없지만, GROUP 함수와 같이 실패하지 않은 SQL에서는 NVL을 사용해 NULL값을 가공할 수 있다.
5. UPDATE문은 항상 UPDATE되는 테이블이 선행해야 하고, SET 절 내의 서브쿼리는 항상 나중에 반복수행되므로, 서브쿼리에서 가공을 위해 추출해야 하는 행이 많을 때에 는 다중처리 방법을 이용해야 한다.
- 오라클 7.3 이상부터 적용
- 과거에 비해 비교적 자유롭게 조인 뷰에서 INSERT, DELETE, UPDATE를 할 수 있다. (그래도 여전히 제약이 많다.)
- 오라클 7.3부터 FROM절에 하나 이상의 테이블이나 뷰가 위치하는 조인이 된 뷰를 수정할 수 있게 됨
- 제약조건 : DISTINCT, 그룹함수(SUM, AVG등), 집합처리(UNION, INTERSECT등), GROUP BY와 HAVING처리, ROWNUM의 사용, 순환처리(CONNECT BY/START WITH 구문)을 사용한 뷰는 수정할 수 없다.
- 최종 뷰로 병합 가능한 뷰만 수정할 수 있다.
- 조인된 테이블 중에서 키보존 테이블만 수정할 수 있다.
- 조인으로 인해 변화가 일어난 집합의 논리적인 기본키가 자신의 기본키대로 유지되는 테이블 (조인을 했어도 자기 집합의 키 레벨은 변하지 않는 테이블)
- 1:M 조인의 경우 - 조인 결과의 키는 M측 테이블의 키 레벨이 되므로, M측 테이블은 키 레벨이 변하지 않지만, 1측 테이블은 조인 집합을 식별하는 기본키가 될 수 없다.
- M:M 조인의 경우 – 조인 결과는 둘의 Cartesian Product 만큼의 행이 생성 되므로, 두 테이블 모두 키보존 테이블이 될 수 없다. (M:M은 구현 단계에서 나와서는 안되는 구조이므로 별 걱정할 필요 없다-_-)
- 1:1 조인의 경우 – 조인 결과가 양쪽 테이블의 키 레벨과 같으므로, 두 테이블 모두 키보존 테이블이 될 수 있다.
- 키 레벨이 변경되지 않았어도 OUTER JOIN에 의해 생성된 집합에서는 최하위 테이블이 키보존 테이블이 될 수 없는 경우가 있다. (M측 테이블이 OUTER JOIN되는 경우 NULL 필드들이 양산되므로 더 이상 기본키의 역할을 할 수 없다.)
- 조인뷰의 UPDATE에서 WHERE절에는 아무거나 올 수 있지만, SET 절에는 키보존 테이블의 열만 올 수 있다.
- 조인뷰의 DELETE에서는 반드시 단 하나의 키보존 테이블만 가져야 한다.
- 조인뷰의 INSERT는 DELETE와 같이 하나의 키보존 테이블만 가져야 가능하며, 여기에 덧붙여 원 테이블의 제약조건(constraints)을 만족해야 한다. (당연한 얘기;)
좋은 정보 감사합니다.. ^^
--------------------------------------------------------------------------------------------------------------
문제:
독립적인 기능을 하는 자바스크립트 클래스를 하나 만들었다.
이 클래스를 싱글턴으로 사용하고 싶다.
또한, 일반적인 getInstance() 라는 스태틱 메서드를 사용하는 대신,
바로 생성자를 호출해서 객체를 만들도록(내부적으로 싱글턴 인스턴스를 리턴) 하려고 한다.
어떻게 하면 자바스크립트에서 생성자만으로 싱글턴을 구현할 수 있을까?
해결책:
한참을 고민해봤다.
이런 방법으로 구현해보면 어떨까?
클래스의 생성자에 대한 유효범위를 제한해두고,
그 유효범위 안에서 window 속성의 클래스 생성자(래퍼)를 다시 정의한다.
(일종의 프록시 패턴이라고 할 수도 있겠다)
window 속성의 클래스 생성자에서는 클래스의 유일한 인스턴스를 만들어 리턴하도록 싱글턴을 구현한다.
즉, 외부에서 클래스 생성자를 호출해서 객체를 만들 때에는,
window 속성의 생성자를 호출하게 되므로 생성자만으로 싱글턴을 구현할 수 있다.
아래 실제 구현 예제를 이해하기 위해 몇 가지 자바스크립트 언어에 대한 선수 지식이 필요하다.
javascript 언어 특징 보기
var test = 'aaa';
alert(window.test == test); // 전역 변수인 test 는 window.test 와 동일하다.
2. javascript 의 변수 유효 범위(scope)는 블럭 단위가 아니라 함수 단위이다.
function a() {
if (true) {
var x = 'aaa';
}
alert(x); // 일반적인 언어와 달리 javascript 의 유효범위는 if, for 등의 블럭단위가 아니라, 함수단위다.
// 그렇기 때문에 여기서도 x 는 정상적으로 aaa 를 출력한다.
}
alert(x); // 함수 밖에서는 x 가 정의되어 있기 때문에 에러를 발생한다.
3. 유효 범위를 제한하기 위해 익명함수를 정의할 수 있다.
익명함수 function() {} 를 사용하면 임의대로 유효범위를 제한할 수 있다.
2번의 예제에서 if 블럭 내에 익명함수를 정의해 아래와 같이 유효범위를 제한할 수 있다.
function a() {
if (true) {
// 스스로를 실행하는 익명함수를 정의한다. (function(){ })(); 와 같은 형태이다.
(function() {
var x = 'aaa'; // 이제 x 의 범위는 익명함수 내로 제한됐다.
})();
}
alert(x); // 여기서 x 에 접근할 수 없다.
}
4. 클로저를 통해 외부 함수에서 이미 종료된 함수 내의 변수에 접근할 수 있다.
javascript 의 클로저를 통해 이미 종료된 함수의 변수에 대한 참조를 가질 수 있다.
아래 예제를 보면 쉽게 이해할 수 있을 것이다.
function a() {
var x = 'aaa';
setTimeout(function() { // 이 함수는 a() 함수가 종료된 후, window scope 에서 실행된다.
alert(x); // a() 함수는 종료되었지만, 클로저를 통해 x 의 참조를 유지할 수 있다.
// 여기서는 aaa 가 정상적으로 출력된다.
}, 1000);
}
간단한 실제 구현 모습은 아래와 같다.
(function() { // (a) 익명함수로 유효범위를 제한한다.
// (b) window 속성의 생성자를 정의한다.
// 외부에서 생성자를 호출할 때에는 이 생성자가 호출된다.
window.Singleton = function(name) {
// (d) 객체가 생성되어 있지 않을 경우, 새 객체를 _instance 에 담는다.
if (_instance == null) {
_instance = new Singleton(name);
}
return _instance;
}
// (c) 유일한 싱글턴 인스턴스
var _instance = null;
// (e) 실제 객체 생성자
// 외부에서 이 생성자에 접근할 수 없다.
var Singleton = function(name) {
this.name = name;
}
})();
실제 객체의 생성자는 (e) 부분이다.
외부에서 이 객체의 생성자에 접근하지 못하도록 익명함수(anonymous function)로 생성자를 감싸준다.
이 부분이 (a) 부분이 되겠다.
(c) 와 같이 유일한 싱글턴 인스턴스를 담을 변수를 선언해준다. 전역변수와 같이 선언되어 있지만,
이 변수 역시 생성자와 같은 유효범위에 있기 때문에 외부에서는 접근하지 못한다.
이제 외부에서 이 객체를 생성할 수 있도록 (b)와 같이 window 속성에 같은 이름으로 생성자를 구현해준다.
window.Singleton 은 window 속성이기 때문에 외부에서도 호출이 가능하며,
window prefix 없이 바로 new Singleton() 과 같이 호출이 가능하다.
(외부에서 new Singleton(); 을 호출했을 때 (e) 부분의 실제 함수가 호출되는 게 아니다.)
또한, window.Singleton 객체가 유효범위 밖에서 _instance 를 참조할 수 있는 건, 클로저(closure) 때문이다.
window 속성의 객체 생성자(b)에서는 (d)에서와 같이 싱글턴 부분을 구현한다.
_instance 가 존재하지 않을 경우, 새 객체를 생성해 할당하고, 그렇지 않을 경우 이미 존재하는 객체를 리턴한다.
이와 같이 구현하면 외부에서 new Singleton() 을 호출했을 때,
(실제 객체의 wrapper 격인) window.Singleton() 생성자가 호출되며,
window.Singleton 생성자 내에서 싱글턴 객체를 리턴하게 된다.
아래와 같이 호출해보면, new Singleton() 을 통해 싱글턴 객체가 생성되는 것을 확인할 수 있다.
// 여기서 호출되는 Singleton 생성자는 window.Singleton 이다.
var s1 = new Singleton('aaa');
alert(s1.name); // aaa 출력
var s2 = new Singleton('bbb'); // 이미 생성된 객체가 리턴된다.
alert(s2.name); // aaa 출력
다소 번거롭긴 하지만, 이 방법을 통해 실제 생성자에 대한 접근을 제한할 수 있고,
new 키워드를 통해 싱글턴 객체를 리턴하도록 구현할 수 있다.
(굳이 패턴으로 나누어 생각하려고 한다면, 싱글턴 + 프록시 패턴 정도겠다. )
일반적인 패턴처럼, getInstance() 를 통해 싱글턴 객체를 생성하고 싶을 경우,
같은 방법으로 익명함수 내에서 window.Singleton 안에 getInstance() 를 정의해주면 되겠다.
기타 다른 방법들도 있지만,
기존 생성된 객체를 유지하는 한도 내에서 유용하게 사용할 수 있을 것이라 생각한다.
* 참고:
검색해보니 싱글턴을 구현하는 다른 방법들에 대한 좋은 자료들이 많다.
1. How to make a singleton in javascript
가장 알아보기 쉽고 기본적인 방법이니 참고해보도록 하자.
constructor 이름을 통해 이미 만들어진 객체를 싱글턴으로 만드는 전역 메서드 구현에 대한 방법도 있다.
좋은 내용이 많으니 꼭 읽어보자.
그 외,자바스크립트의 유효범위와 클로저에 대해 잘 이해가 안될 경우, 아래 포스트를 참고하자.
우선 글을 쓰기에 앞서 해당 구현방법은 철저히 개인적인 방법임을 밟히는 바이다.
(이방법이 최적의 방법 혹은 정석이 될수 없음을 미리 알리는 바이다.)
요즘 네이버나 다음과 같은 여러 포탈 사이트에서 오픈API를 제공하고 있다.
거의 모든 오픈API의 방식이 개인키를 부여하여 특정주소를 요청하면 XML로 결과를 리턴해주는 방식이다.
AJAX 에서의 자바스크립트는 기본적으로 XMLHttpRequest 객체의 open()메소드와 send()메소드를 이용해서 해당 uri의 xml을 요청할 수 있다.
하지만 자바스크립트의 보안제약사항에 따라 XMLHttpRequest 객체는 해당 페이지를 로딩한 서버 외에는 연결할 수 없게 되어있다.
그래서 오픈API요청을 자바스크립트에서 바로 사용할수가 없다.
이것을 해결하기 위해선 여러방법이 있겠지만 그중에서 나는 서버에서 해당 오픈API요청을 대신하고 결과를 보여주는 프록시페이지를 만들어 보기로 했다.
해당 구현방법을 알아보기위해 인터넷의 넓은 바다를 항해한 결과,
아파치 자카르타 프로젝트의 commons HttpClient API를 이용하여 구현하는 방법을 찾게 되었다.
모든 구현을 완료하고 페이지를 실행해보았지만 문제가 생겼다.
좀더 삽질을 하고난후 commons logging API 와 commons codec API도 필요하다는것을 알게되었다.
(logging, codec 이 왜 필요한지는 아직 알수없었다. 디버깅과정에서 ClassNotFound 가 뜨는 것들을 추가해주다가 알게되었다.)
(초보의 무식함이다 =..= 만약 아직도 안되고있었다면 계속 삽질을? ;;;)
proxy.jsp
<%@ page import="org.apache.commons.httpclient.HttpClient" %>
<%@ page import="org.apache.commons.httpclient.methods.GetMethod" %>
<%@ page import="org.apache.commons.httpclient.HttpStatus" %>
<%
request.setCharacterEncoding("utf-8");
String url = "오픈API요청URI";
HttpClient client = new HttpClient();
GetMethod method = new GetMethod(url);
try{
int statusCode = client.executeMethod(method);
out.clearBuffer();
response.reset();
response.setStatus(statusCode);
if(statusCode == HttpStatus.SC_OK){
String result = method.getResponseBodyAsString();
response.setContentType("text/xml; charset=utf-8");
out.println(result);
}
}finally{
if(method != null) method.releaseConnection();
}
%>
나는 네이버 실시간 음악 순위를 리턴받아 보았다.
(get방식으로 파라미터값을 받을수있도록 jsp를 구현한 상태이다.)
http://cyzest.cafe24.com/open/rank/proxy_rank.jsp?query=music
이제 자바스크립트의 XMLHttpRequest 객체에서의 open() 메소드에서는 오픈API주소가 아닌 proxy.jsp 의 주소를 요청하면 되는 것이다.
http://cyzest.cafe24.com/open/rank
이제 해당 오픈API의 결과를 유용하게 이용하도록 구현하는 것은 사용자의 몫이 될것이다. :)
갠적으로는... 1년마다 1~2개월정도의 휴가가 있음 좋겠다능... ^^
http://twalk.tistory.com/226
1.html
function chk(){
j = i1.document.body.innerHTML; // --> 2.html의 소스
k = i1.i2.document.body.innerHTML; // --> 3.html의 소스
}
1번 <a href="javascript:chk()">chk</a>
<iframe src="2.html" id="i1"></iframe>
2.html
2번
<iframe src="Noname3.html" id="i2"></iframe>
3.html
3번
JBoss를 실행하려고 하니... 1098 포트 에러가 발생했다.
JVM바인딩 하는 포트가 1098번 이라고 하면서 이미 사용중인 포트라고 말하는것 같은데..
-_-; 머냐 이거..아무런 문제 없던것이.. ( 해결하고 작성하는 거라..-_- 이미는 없다..)
다음은 해결책.
1. 이미 사용중인 포트 번호를 알아보자
[열기] cmd창 여는법
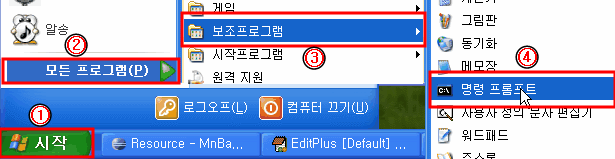
2. 시작 > 실행 > 'cmd' 입력 > 확인

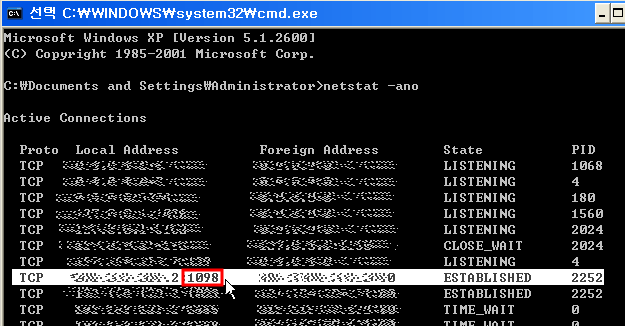
cmmand 창을 열고 c:\>netstate -ano 을 쳐보자 ( * netstat에 대한 설명 >netstat -help )
그러면 다음과 같이 사용중인 포트 정보를 보여준다.
그중에서 에러를 발생시는 녀석의 PID(우측)를 확인하자.
(이 캡쳐는 에러시에 확인한 포트리스트다.)
2. Window 작업 관리자'를 열고 해당 PID를 사용하는 프로세스를 확인하고 강제종료 한다.
( 본인은 웹마에서 사용중이었다..-_-;)
2.1. Window 작업 관리자 여는 법
- 우측의 트레이에 마우스를 가져간후 마우스 오른쪽을 클릭한후, '작업 관리자(K)' 선택
- 혹은 Ctrl 키 + Alt키 + Delete 키를 동시에 누른다.

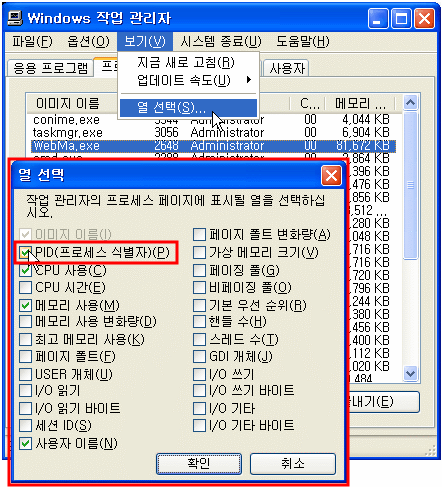
: 상단의 메뉴의 보기(V)에서 열선택(S)를 선택한후,
PID(프로세스 식별자)(p) 을 체크해줍니다.
(본인은 웹마가 1098을 사용중이었습니다. -_-; 아래 캡쳐는 해결한 후..)
http://dev.anyframejava.org/anyframe/doc/core/3.1.0/corefw/guide/cache.html
|
|
|
|
|
| cache.memory | 메모리 Cache를 사용할 것인지 정의한다. false로 설정되면 메모리로 캐싱될 수 없다. |
|
|
| cache.capacity | Cache에 저장할 수 있는 object의 최대 갯수를 지정한다. 음수로 설정되면 이 기능을 사용하지 않는다. 캐싱 가능한 object의 갯수를 제한하지 않는다. |
|
|
| cache.algorithm | caching algorithm의 classname을 지정한다. 이 클래스는 com.opensymphony.oscache.base.algorithm.AbstractConcurrentReadCache를 extend 해야한다. cache capacity가 양수로 설정되면 default algorithm으로 LRUCache가 사용되고, 음수로 설정되면 com.opensymphony.oscache.base.algorithm.UnlimitedCache가 사용된다. |
|
|
| cache.unlimited.disk | Persistence cache의 size를 제한할 것인지 또는 in-memory cache와 동일한 사이즈로 제한할 것인지를 나타낸다. 이 값이 true 로 설정되면 persistent cache는 제한없이 사용될 수 있다. |
|
|
| cache.blocking | 새로운 content를 캐싱하거나 이미 캐싱된 content를 검색할 때 block waiting 해야 하는지를 정의한다. |
|
|
| cache.persistence.class | Persistence cache를 사용하고자 할 때 Persistence cache를 구현한 classname을 정의한다. 이 클래스는 PersistenceListener를 extend 해야한다. |
|
|
| cache.persistence .overflow.only |
메모리 Cache가 overflow mode일때 Persistence Cache를 사용할지 지정한다. |
|
|
| cache.event.listeners | Cache에 적용한 event handler를 지정한다. event handler가 여러개 일 경우 각각의 classname을 콤마로 구분하여 정의한다. |
|
|
| cache.cluster.properties | JavaGroupsBroadcastingListener를 사용할때 이 property를 정의한다. JavaGroups channel properties를 사용한다. JavaGroups의 실행을 제어할 수 있다. |
|
|
| cache.cluster.multicast.ip | JavaGroupsBroadcastingListener를 사용할 때 이 property를 정의한다. broadcasting을 사용하기 위해 JavaGroups는 multicast IP를 사용해야 한다. |
|
|
| cache.cluster.jms.node.name | JMS10BroadcastingListener 또는 JMSBroadcastingListener를 사용할 때 이 property를 정의한다. JMS connection factory를 사용한다. |
|
|
| cache.cluster.jms.topic.name | JMS10BroadcastingListener 또는 JMSBroadcastingListener를 사용할때 이 property를 정의한다. 이것은 JMS topic name 이다. |
|
|
| cache.cluster.jms.topic.factory | JMS10BroadcastingListener 또는 JMSBroadcastingListener를 사용할때 이 property를 정의한다. 이 노드의 이름은 cluster에 존재하고, 각각의 node마다 unique한 값을 갖는다. |
|
|
| cache.path | DiskPersistenceListener를 사용할 때 이 property를 정의한다. 데이터를 캐싱하기 위한 path를 지정한다. |
|
|
| cache.persistence.disk .hash.algorithm |
disk의 filname으로 간단한 cache key를 생성하기 위한 hash algorithm이다. |
|
|
iBATIS는 공식적으로 캐시를 할때에 OSCache를 사용할 수 있도록 되어있습니다. 하지만 그 기능이 매우 자동적이며 제한적이고 세세한 설정을 개발자가 할수가 없습니다. 그래서 다음을 한번 알아 보기로 할까요. 다음의 예시는 [이곳]에 언급된 내용을 살짝 수정하였습니다.
<cacheModel type="OSCACHE" id="cacheModel" readOnly="true">
<flushInterval hours="24"/>
<flushOnExecute statement="flushCache"/>
</cacheModel>
<resultMap class="kr.pe.theeye.Cache" id="CacheResult">
...
</resultMap>
<insert id="flushCache" resultClass="string">
INSERT ...
</insert>
<select id="makeCache1" resultMap="CacheResult" cacheModel="cacheModel">
SELECT ...
</select>
<select id="makeCache2" resultMap="CacheResult" cacheModel="cacheModel">
SELECT ...
</select>
<select id="makeCache3" resultMap="CacheResult" parameterClass="int"
cacheModel="cacheModel">
SELECT ... WHERE PAGE = #value#
</select>위의 SQL맵 예제에서는 INSERT문 한개와 SELECT문 3개가 존재합니다. 모두 cacheModel이라는 id의 캐시모델과 연관되어집니다. 이것을 간단하게 그림으로 그려보면 다음과 같은 모양을 가지고 있습니다.

그려놓고 보니깐 좀 말이 안되는 그림 같아 보이네요;; 아무튼 하나의 캐시 모델에 3가지의 캐시를 생성할 수 있는 조건이 있고 2가지 캐시를 삭제할 수 있는 조건이 있다고 봐주시면 되겠습니다. 둥근 사각형은 개발자가 임의로 호출을 해야만 하는 기능들이고 위의 동그라미는 캐시 유지 시간 설정으로 봐주시면 되겠습니다.
이제 다음의 몇가지 예시 상황들에 대한 캐시의 처리 과정에 대해 알아보겠습니다.
1. 한개의 캐시 처리 (makeCache1 → flushCache)
makeCache1이 수행되면 cacheModel에 하나의 캐시가 생성됩니다. 앞으로 makeCache1이 호출될때마다 캐시가 존재하는한 DB에 접근없이 캐시결과값을 제공하게 됩니다. flushCache를 수행하면 캐시가 삭제됩니다. 다시 makeCache1을 호출하면 DB에서 결과를 가져와서 반환함과 동시에 캐시를 생성하게 됩니다. 캐시가 생성된 시점에서 flushInterval에 설정된 시간이 경과하도록 flushCache가 호출되지 않는다면 시간 만료로 자동 삭제됩니다.
2. 두개의 캐시 처리 (makeCache1 → makeCache2 → flushCache)
makeCache1이 호출되면 cacheModel에 하나의 캐시가 생성됩니다. makeCache2가 호출되면 마찬가지로 cacheModel에 또다른 하나의 캐시가 생성됩니다. 이 두개의 캐시는 엄연히 다르며 각각의 makeCacheX가 호출될때 해당하는 만들어진 캐시값을 반환하게 됩니다. 하지만 둘다 모두 동일하게 cacheModel안에 소속됩니다. 이어서 flushCache를 호출하게 되면 두 캐시가 모두 삭제됩니다. 정확히는 flush에 대한 설정을 해두면 해당 캐시모델의 모든 캐시를 소거한다고 보시면 됩니다. 그러므로 이런 부분에 주의하여 캐시모델을 함께 사용할지 따로 다른 캐시모델을 만들지를 결정하셔야 합니다.
3. 인자값의 차이에 따른 처리 (makeCache3[1] -> makeCache3[2] -> flushCache)
makeCache3에는 parameterClass를 사용하여 동적인 쿼리를 수행하도록 되어있습니다. 예시로 간단하게 int값을 받도록 하였는데요. 캐시를 생성할때의 키값에는 이 인자값들이 모두 포함되어 키를 이룹니다. 그러므로 paramterClass로 넘어오는 값이 1일때와 2일때는 다른 쿼리(키)가 됩니다. 그러므로 1이라는 값의 인자를 받아 실행되는 makeCache3의 캐시와 2라는 값을 받아 실행되는 makeCache3는 각각 별개의 캐시가 생성됩니다. 마찬가지로 하나의 cacheModel안에서 호출되지만요. flushCache를 호출하면 이 두캐시가 모두 삭제됩니다.
결론을 내보자면 위와 같은 iBATIS에서 제공하는 기본적인 캐시모델로는 같은 쿼리지만 다른 결과가 나올 수 있는 부분에는 사용할 수 없습니다. SNS 서비스에서 볼 수 있을 다음을 생각해 봅시다.
2. 사용자가 접속하여 친구들의 최근근황을 확인하였다. [캐시 생성됨]
3. 친구중 한명이 최근 근황을 업데이트 하였다.
4. 사용자가 다시한번 친구들의 최근근황을 확인하였다. [캐시값 반환됨]
위를 수행하였을 때 친구들의 정보가 바뀌어도 사용자는 계속 캐시된 값을 받게됨을 알 수 있습니다. 그러므로 친구들의 업데이트 된 정보를 적시에 얻기가 힘듭니다. 하지만 그렇다고 친구의 정보가 업데이트 될때 다른 사용자의 캐시를 삭제하는데도 무리가 있습니다. 왜냐하면 캐시 키 값을 모르기 때문이죠. 이부분을 해결하려면 iBATIS의 SQL맵 캐시 기능을 사용하지 말고 자체적인 알고리즘으로 구현을 해야 할 것 같습니다.
ASP 에서의 삼항 연산자.
Dim str = [비교조건식] ? [비교조건식이 true 일 경우 값] : [비교조건식이 false일 경우 값]
삼항 연산자는 다음과 같은 형태로 if~ then을 사용하지 않고 비교해서 값을 넣어 줄 수 있는
편리한 도구이다.
하지만 VBscript 에서는 작동하지 않고 Jscript 에서만 작동이 된다.
<%@ codepage="65001" language="VBScript" %> (X)
<%@ codepage="65001" language="JScript" %> (O)
language 부분을 JScript로 바꾸어 주어야 ASP 에서도 사용 할 수 있다
[출처] 각종 연산자.|작성자 마력의돌
이 문제는 오라클만의 문제가 아니고 거의 모든 RDBMS 제품들에 대해 공통적인 문제입니다.
일단 SQL 튜닝에서는 모든 상황에 항상 맞는 것은 없습니다.
즉, SQL 튜닝엔 왕도가 없다는 말입니다. 수학공식 외우듯이 외워서 튜닝을 하는 것은 아니며 그때 그때 데이터의 분포, 서버의 상태, 인덱스의 유무 및 SQL trace나 tkprof결과 등의 각종 참조가능한 수치들을 분석하여 튜닝방향을 정합니다.
상황에 따라 다른 모든 경우엔 가장 안 좋던 방법이 특정 경우엔 최적의 솔루션이 될 수 있습니다.
참고하세요...;
질문의 3가지 + @ 방법의 두드러진 특징만 구별할 수 있어도 판단에 많은 도움이 되겠지요.
A 집합에서 B집합의 데이터를 제외한 나머지만 구하는 방법은 질문의 3가지를 포함하여 상황에 따라 보통 크게 5가지정도를 주로 쓰게 됩니다. 하나씩 특징만 간단히 적겠습니다...자세한 내용은 직접 공부하세요...;
1. not in ...
SELECT * FROM A WHERE a.key not in (SELECT b.key FROM B)
형태의 구문이며, B쪽을 먼저 access하여 b.key로 a.key에 공급자역할을 하는 서브쿼리로 쓰고 싶을 때 주로 사용합니다.
2. not exists ...
SELECT * FROM A WHERE not exists (SELECT * FROM B WHERE b.key = a.key)
형태의 구문이며, A쪽을 먼저 access하고 나서 a의 각 row들을 not exists로 조사하여 filtering하는 처리를 할 때 주로 사용합니다. 즉, B를 access하기 전에 A쪽의 전체범위가 먼저 access됩니다.
이 때의 서브쿼리는 공급자가 아닌 확인자역할만 해 줄 수 있습니다.
3. minus ...
SELECT key, col1, col2 FROM A
MINUS
SELECT key, col1, col2 FROM B
형태의 구문이며, 테스트 해 보면 아시겠지만 MINUS는 특성 상 sort와 중복제거 수행을 동반합니다.
그러므로 가장 이해하기는 간단하나 대용량에서는 사용 시 주의해야 합니다.
A나 B집합의 access대상이 대량인 경우 대량의 sort와 중복제거가 발생하므로 이들 처리에 많은 시간이 소요될 수 있는 쿼리입니다.
4. Outer + Null Check ...
SELECT * FROM A, B WHERE A.key = B.Key(+) AND B.Key IS NULL
형태의 구문이며, 위의 not in이나 not exists가 주로 Nested Loop Join 또는 Nested Loop Anti Join 방법을 수행하는데 비해 대용량의 경우 Hash Join이나 Merge Join을 유도하여 성능을 보장받을 수 있는 방법입니다.
단, 각 DBMS 마다 A LEFT OUTER JOIN B ON ~ , (*)등으로 아우터조인에 대한 표현은 약간 씩 다릅니다.
5. UNION ALL + Group count 또는 count() over() 분석함수 이용등 ...
SELECT *
FROM(
SELECT a.*
, COUNT(DISTINCT gbn) OVER(PARTITION BY key) AS cnt
, COUNT(DISTINCT DECODE(gbn, 'A', 1)) OVER(PARTITION BY key) AS a_cnt
FROM(
SELECT 'A' AS gbn, key, col1, col2 FROM A UNION ALL
SELECT 'B' AS gbn, key, col1, col2 FROM B
) a
)
WHERE cnt < 2 AND a_cnt = 1
형태의 구문이며, UNION ALL은 MINUS와 달리 sort나 중복제거를 하지 않고 별다른 조인도 없기 때문에 양쪽집합에 scan할 마땅한 인덱스가 없거나 하는 상황에서 위력을 발휘할 수 있는 솔루션입니다.
GROUP BY와 COUNT 함수로도 위의 의미를 그대로 만들 수 있습니다...분석함수나 통계함수를 지원하지 않는 DBMS들은 COUNT() OVER() 대신 GROUP BY / COUNT로 변경해야겠지요...;
이외에도 구현할 수 있는 방법들이야 더 있겠지만, 대부분의 상황들에서 위의 예시들이 주로 많이 쓰인다는 것을 거듭 밝힙니다.


