
'분류 전체보기'에 해당되는 글 108건
- 2009.03.31 서브쿼리, 테이블 생성
- 2009.03.30 ROME을 활용해서 Feed 생성하기
- 2009.03.29 Struts2 에서 확장자 제거하기
- 2009.03.29 특수문자(&, + 등)를 get방식 변수로 넘기기
- 2009.03.28 jQuery로 Ajax 개발을 단순화 하기
- 2009.03.28 jQuery 1
- 2009.03.26 <bean /> 선언시 주의할 점
- 2009.03.26 [DB] 트리거(trigger)로 로그테이블 만들기
- 2009.03.24 struts2 커스텀태그 개발자가이드
- 2009.03.23 struts2 Result Types
- 2009.03.20 .net+ajax
- 2009.03.19 DELETE 와 TRUNCATE
- 2009.03.19 [SQL] SQL 작성을 위한 표준 지침
- 2009.03.19 논리합연산자 - WHERE 조건의 동적구성시 OR/UNION ALL을 통한 해결
- 2009.03.15 좋은 자료인듯..
SUBQUERY
- SUBQUERY의 사용방법과 SUBQUERY에 의해
검색된 데이터 정렬에 대해 알아보자!
-SUBQUERY를 사용할 수 있는 절
. WHERE, HAVING, UPDATE
. INSERT구문의 INTO
. UPDATE구문의 SET
. SELECT나 DELETE의 FROM절
-단일 행 SUBQUERY
단일 행 SUBQUERY는 내부 SELECT문장으로 부터
하나의 행을 검색하는 질의이다.
예문) emp테이블에서 SCOTT의 급여보다 많은
사원의 정보를 사번, 이름, 담당업무, 급여를 출력해 보자
우리가 SCOTT이라는 사람의 급여를 알지 못하므로
두번의 SQL문이 필요하다.
SELECT sal FROM emp WHERE name='SCOTT';
위의 결과를 가지고 다시 조건에 사용 되는
SQL문이 있어야 한다.
SELECT empno,ename,job,sal
FROM emp
WHERE sal > 3000;
위의 경우를 SUBQUERY로 구현을 한다면 다음과 같다.
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal > (SELECT sal
4 FROM emp
5 WHERE ename = 'SCOTT');
문제) emp테이블에서 사번이 7521인 사람의 업무와
같고 급여가 7934보다 많은 사원의 정보를
사번, 이름, 업무, 입사일, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, hiredate, sal
2 FROM emp
3 WHERE job = (SELECT job
4 FROM emp
5 WHERE empno = 7521)
6 AND
7 sal > (SELECT sal
8 FROM emp
9 WHERE empno = 7934);
:: SUBQUERY에서 그룹함수 사용
예문) emp테이블에서 급여의 평균보다 적은 사원의
정보를 사번, 이름, 업무, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal < (SELECT AVG(sal)
4 FROM emp);
:: SUBQUERY에서 HAVING절 사용
예문) emp테이블에서 20번 부서의 최소 급여보다
많은 모든 부서를 출력해보자!
SQL> SELECT deptno, MIN(sal)
2 FROM emp
3 GROUP BY deptno
4 HAVING MIN(sal) > (SELECT MIN(sal)
5 FROM emp
6 WHERE deptno = 20);
문제) emp테이블에서 업무별로 가장 적은 급여의 평균을
출력해 보자! (업무명, 급여의 평균값 순으로 출력)
SQL> SELECT JOB,AVG(sal)
2 FROM emp
3 GROUP BY job
4 HAVING AVG(sal) = (SELECT MIN(AVG(sal))
5 FROM emp
6 GROUP BY job);
:: 다중 행 SUBQUERY연산자
- IN연산자
- ANY연산자
- ALL연산자
- EXISTS연산자
1) IN 연산자
2개 이상의 행을 결과로 받는 SUBQUERY에 대하여
비교 연산자(=,>=...)를 기술하면 ERROR가 발생한다.
이런 경우 SUBQUERY에서 반환되는 모든 행의 값들을
비교하여 QUERY를 수행하는 연산자가 IN이다.
예문) emp테이블에서 업무별로 최소 급여를 받는
사원의 사번, 이름, 업무, 급여 순으로 출력해 보자!
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal = (SELECT MIN(sal)
4 FROM emp
5 GROUP BY job);
위는 서브쿼리에서 넘겨지는 결과가 하나의 결과가 아니라
여러개의 결과 이므로 =이라는 연산을 수행하지 못한다.
SQL> SELECT empno, ename, job, sal
2 FROM emp
3 WHERE sal IN (SELECT MIN(sal)
4 FROM emp
5 GROUP BY job);
2) ANY 연산자
2개 이상의 결과를 반화하는 SUBQUERY에 대하여
어떻게 사용하는가를 지정해 두어야 한다.
비교 연산자(=,>=...)와 SUBQUERY 사이에
ANY연산자를 기술하여 반환된 결과 값 모두를 비교한다.
예문) emp테이블에서 30번 부서의 최소 급여를 받는
사원보다 급여를 더 많이 받는 사원의 정보를
사번,이름,업무, 입사일, 급여, 부서번호를 출력 해보자
(단, 30번 부서는 제외)
SQL> SELECT empno,ename,job,hiredate,sal,deptno
2 FROM emp
3 WHERE deptno != 30 AND
4 sal > ANY (SELECT MIN(sal)
5 FROM emp
6 WHERE deptno = 30);
테이블 생성
CREATE TABLE 문장을 실행하여 테이블을 생성한다.
이 문장은 DDL문장으로 오라클 DataBase 구조를 생성,
수정, 삭제 하는데 사용되는 SQL문장이다. 이러한 문장은
DataBase에 즉각 영향을 미치며 DataBase 사전(DATA
DICTIONARY)에 정보를 기록 한다.
문법:
CREATE TABLE [테이블명]
(컬럼명 자료형,...);
이름 규칙
1) 문자로 시작
2) 문자의 길이는 1~30 이내로 사용
3) 오직 A~Z, 0~9, _, $, #만을 사용 가능하다.
4) 동일한 사용자가 소유한 객체 이름은 중복될 수 없다.
5) 예약어를 사용 불가
자료형
1) VARCHAR2(n) :
가변 길이 문자 데이터 (1~4000byte)
2) CHAR(n) :
고정 길이 문자 데이터(1_2000byte)
3) NUMBER(p.s)
전체 p자리 중 소수점 이하 s자리(p: 1~38, s: -84~127)
4) DATE
7byte를 차지하는 세기,년,월,일,시,분,초를 기억하는
날짜 데이터
5) LONG
가변 길이 문자 데이터(1~2Gbyte)
6) CLOB
단일 바이트 가변 길이 문자 데이터(1~4Gbyte)
7) BLOB
가변 길이 이진 데이터(1~4Gbyte)
8) BFILE
가변 길이 외부 파일에 저장된 이진 데이터(1~4Gbyte)
9) RAW(n)
n byte의 원시 이진 데이터(1~2000)
10) LONG RAW
가변 길이 원시 이진 데이터(1~2Gbyte)
예문)
SQL> CREATE TABLE test_T(
2 name VARCHAR2(10),
3 age NUMBER(3),
4 phone VARCHAR2(15),
5 idNum CHAR(14)
6 addr1 VARCHAR2(10)
:: 제약 조건
오라클 서버는 부적절한 자료가 입력되는 것을
방지하기 위하여 constraint를 사용한다.
- 제약 조건은 테이블 LEVEL에서 규칙을 적용한다.
- 제약 조건은 종속성이 존재할 경우
테이블 삭제를 방지 한다.
- 테이블에서 행이 삽입, 갱신, 삭제 될 때마다
테이블에서 규칙을 적용한다.
:: 제약 조건 정의 방법
1) 컬럼 레벨
열(Column)별로 제약 조건을 정의한다.
- 무결성 제약 조건 5가지를 모두 적용 가능 하다.
1. PRIMARY KEY(PK) :
유일하게 테이블의 각 행을 구별한다.(NOT NULL
과 UNIQUE-중복 불가능 조건을 만족 한다.)
2. FOREIGN KEY(FK) :
열과 참조된 열 사이의 외래키 관계를 적용한다.
3. UNIQUE KEY(UK) :
테이블의 모든 행을 유일하게 하는 값을 가진 열
(NULL을 허용)
4. NOT NULL(NN) :
열은 NULL값을 포함할 수 없다.
5. CHECK(CK) :
참(TRUE)이어야 하는 조건을 지정함
(업무 규칙 설정 시)
- NOT NULL제약 조건은 컬럼 LEVEL에서만 가능하다
특정한 열(Column)에 대입되는 값이 절대로
NULL값을 허용해서는 안될때 사용한다.
idNum CHAR(14) CONSTRAINT NOT NULL
2) 테이블 레벨
테이블의 컬럼 정의와는 개별적으로 정의한다.
하나 이상의 열을 참조할 경우에 사용
NOT NULL을 제외한 나머지 제약 조건만 정의 가능하다
:: 테이블 생성 연습 SQL문
SQL> CREATE TABLE test_T(
2 id VARCHAR2(10) CONSTRAINT test_T_pk PRIMARY KEY,
3 name VARCHAR2(10),
4 pwd VARCHAR2(10));
SQL> CREATE TABLE test2_T(
2 hiredate date,
3 license VARCHAR2(20),
4 id VARCHAR2(10) CONSTRAINT test2_t_fk
REFERENCES test_T (id));
위의 내용을 달리 한다면
SQL> CREATE TABLE test2_T(
2 hiredate date,
3 license VARCHAR2(20),
4 id VARCHAR2(10),
5 CONSTRAINT test2_fk FOREIGN KEY (id)
REFERENCES test_T (id));
주의)
FOREIGN KEY값은 MASTER TABLE에서 존재하는
값과 일치해야 하거나 NULL이 되어야 한다.
예문) 다음 테이블 생성 코드를 보고 설명해 보자!
SQL> CREATE TABLE post(
2 post1 CHAR(3),
3 post2 CHAR(3),
4 addr VARCHAR2(60) CONSTRAINT
post_addr_nn NOT NULL,
5 CONSTRAINT post_post12_pk
PRIMARY KEY (post1, post2));
SQL> insert into post values('100','121','서울');
SQL> CREATE TABLE member_T(
2 id VARCHAR2(10) CONSTRAINT
member_T_pk PRIMARY KEY,
3 name VARCHAR2(10) CONSTRAINT
member_T_name_nn NOT NULL,
4 sex CHAR(1) CONSTRAINT
member_T_sex_ck
CHECK (sex IN ('1','2','3','4')),
5 jumin1 CHAR(6),
6 jumin2 CHAR(7),
7 tel VARCHAR2(15),
8 post1 CHAR(3),
9 post2 CHAR(3),
10 addr VARCHAR2(60),
11 CONSTRAINT member_jumin12_uk
UNIQUE (jumin1, jumin2),
12 CONSTRAINT member_post12_fk
FOREIGN KEY (post1, post2)
REFERENCES post (post1, post2));
위와 같이 제약 조건을 걸고 다음과 같이 데이터를
넣게 되면 오류가 발생 한다. 이유는?
SQL> INSERT INTO MEMBER_T VALUES(
'abc','마루치','1','123456','1234567',
'011','100','200','서울');
:: 테이블 생성시 유익한 Tip
emp테이블에서 사번, 이름, 업무, 입사일, 부서번호만
포함하여 emp_temp라는 테이블을 생성해보자
자료들은 포함하지 않고 구조만 생성하자!!
SQL> CREATE TABLE emp_temp
2 AS SELECT empno,ename,job,hiredate,deptno
3 FROM emp
4 WHERE 1 = 2;
확인
SQL> SELECT * FROM emp_temp;
SQL> desc emp_temp;
테이블 수정
:: 새로운 열(Column) 추가
SQL> ALTER TABLE emp_temp
2 ADD (etc VARCHAR2(20));
:: 열(Column) 수정
SQL> ALTER TABLE emp_temp
2 MODIFY (etc CHAR(30));
:: 열(Column)에 제약 조건 추가
SQL> ALTER TABLE emp_temp
2 ADD CONSTRAINT emp_temp_etc_nn
NOT NULL (etc);
주의)
NOT NULL제약 조건은 컬럼 정의 시에만 가능하다.
그러므로 위의 제약 조건 추가 문은 오류가 발생한다.
SQL> ALTER TABLE emp_temp
2 ADD CONSTRAINT emp_temp_etc_uk
UNIQUE (etc);
:: 열(Column)에 제약 조건 삭제
SQL> ALTER TABLE emp_temp
2 DROP CONSTRAINT emp_temp_etc_uk;
:: 사용되는 계정에 따른 제약 조건을 확인하기 위해
다음과 같은 DATA DICTIONARY를 통해 확인한다.
SQL> SELECT constraint_name,table_name,status
2 FROM user_constraints;
:: 테이블 삭제
SQL> DROP TABLE emp_temp;
아래는 테이블 삭제가 아니라 테이블에 있는 데이터 모두를
삭제하는 문장이다.
SQL> DELETE FROM emp_temp;
[출처] 서브쿼리, 테이블 생성|작성자 자바강지
ROME이 여러모로 좋은 오픈소스로 활용되는 것 같네요. 좀더 분석해서 필요한 기능들을 공유할께요.
필요한 라이브러리는 ROME 1.0, JDOM 1.0이 필요합니다.
1. Feed 생성 소스
package client;2. Servlet 소스
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.mimul.DataFacade;
import com.mimul.domain.Category;
import com.mimul.domain.Entry;
import com.mimul.domain.SiteConfig;
import com.sun.syndication.feed.synd.SyndCategory;
import com.sun.syndication.feed.synd.SyndCategoryImpl;
import com.sun.syndication.feed.synd.SyndContent;
import com.sun.syndication.feed.synd.SyndContentImpl;
import com.sun.syndication.feed.synd.SyndEntry;
import com.sun.syndication.feed.synd.SyndEntryImpl;
import com.sun.syndication.feed.synd.SyndFeed;
import com.sun.syndication.feed.synd.SyndFeedImpl;
public class CreateFeed
{
private final Log log = LogFactory.getLog(this.getClass());
private DataFacade dataFacade;
public void setDataFacade(DataFacade dataFacade) {
this.dataFacade = dataFacade;
}
public SyndFeed getFeed(String type)
{
SyndFeed feed = null;
Entry post = null;
List<Entry> recentEntries = null;
List<SyndEntry> entries = null;
List<SyndCategory> categories = null;
StringBuilder sb = null;
try {
feed = new SyndFeedImpl();
feed.setFeedType(type); //rss_2.0
feed.setTitle("Mimul's Developer World");
feed.setLink("http://www.mimul.com/");
feed.setDescription("Java Ecxamples Code");
entries = new ArrayList<SyndEntry>();
post = new Entry();
post.setType("post");
post.setEntryStatus("publish");
// 데이터 베이스에 저장된 엔트리를 가져온다
recentEntries = dataFacade.getEntryPage(post,
10, 0, null, null).getItems();
for (Entry entry:recentEntries) {
SyndEntry syndEntry = new SyndEntryImpl();
syndEntry.setTitle(entry.getTitle());
String link = null;
if(StringUtils.isNotBlank(entry.getName())) {
link = "http://www.mimul.com" + "/post/" +
entry.getName() + ".html";
}else{
link = "http://www.mimul.com" + "/post/id/" +
entry.getId() + ".html";
}
syndEntry.setLink(link);
syndEntry.setAuthor(entry.getAuthor().getNickname());
syndEntry.setPublishedDate(entry.getPostTime());
categories = new ArrayList<SyndCategory>();
// 카테고리 정보를 가져온다
for(Category category:entry.getCategories()) {
SyndCategory syndCategory = new SyndCategoryImpl();
syndCategory.setName(category.getName());
syndCategory.setTaxonomyUri("http://www.mimul.com" +
"/category/" + category.getName() + "/");
}
syndEntry.setCategories(categories);
SyndContent content = new SyndContentImpl();
content.setType("text/html");
sb = new StringBuilder();
sb.append(entry.getSummary())
.append("<p>").append("<a href=\"").append(link)
.append("\">[more..]</a></p>");
content.setValue(sb.toString());
syndEntry.setDescription(content);
entries.add(syndEntry);
}
feed.setEntries(entries);
} catch (Exception e) {
log.error(e);
}
return feed;
}
}
public void doPost(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException {
SyndFeedOutput output = null;
try {
SyndFeed feed = getCreateFeed().getFeed("rss_2.0");
feed.setFeedType("rss_2.0");
response.setContentType("application/xml; charset=UTF-8");
response.setHeader("Pragma","No-Cache");
response.setHeader("Cache-Control","No-Cache");
response.setDateHeader("Expires",0);
output = new SyndFeedOutput();
output.output(feed, response.getWriter());
} catch (FeedException e) {
log.error(e);
response.sendError(
HttpServletResponse.SC_INTERNAL_SERVER_ERROR,
"FEED 생성 오류");
}
}
private CreateFeed getCreateFeed() {
return (CreateFeed) WebApplicationContextUtils.
getWebApplicationContext(getServletConfig()
.getServletContext()).getBean("createFeed");
}
Struts2에서 Action의 기본확장자는 action이다.
REST의 관점에서 보면 URL은 Resource를 가리키고 있을 뿐이어서 action이란 접미어가 붙는 것은 restful 하지 않아 보인다.
그래서 struts.properties의 struts.action.extension에 아무것도 할당하지 않으면 간단히 확장자를 제거 할 수 있다.
struts.action.extension=
struts.properties
하지만, 이렇게 하면 welcome-file을 사용할 수 없고, *.jsp, *.gif, *.jpg등 struts action이 아닌 resource들은 접근 할 수도 없다. 그래서 다음과 같이 간단한 필터를 만들어 보았다.
- package filters;
- import java.io.IOException;
- import javax.servlet.Filter;
- import javax.servlet.FilterChain;
- import javax.servlet.FilterConfig;
- import javax.servlet.ServletException;
- import javax.servlet.ServletRequest;
- import javax.servlet.ServletResponse;
- import javax.servlet.http.HttpServletRequest;
- import org.apache.struts2.dispatcher.FilterDispatcher;
- public class StrutsRedirectFilter implements Filter {
- FilterDispatcher dispatcher = new FilterDispatcher();
- @Override
- public void doFilter(ServletRequest req, ServletResponse res,
- FilterChain chain) throws IOException, ServletException {
- HttpServletRequest request = (HttpServletRequest) req;
- String uri = request.getRequestURI();
- // 확장자가 있는 경우
- if (uri != null
- && (uri.equals(request.getContextPath().concat("/")) || uri
- .substring(uri.indexOf("/")).indexOf(".") > -1)) {
- chain.doFilter(req, res);
- // 아닌 경우 struts로 넘긴다.
- } else {
- dispatcher.doFilter(req, res, chain);
- }
- }
- @Override
- public void destroy() {
- dispatcher.destroy();
- }
- @Override
- public void init(FilterConfig config) throws ServletException {
- dispatcher.init(config);
- }
- }
StrutsRedirectFilter.java
이 필터를 org.apache.struts2.dispatcher.FilterDispatcher 대신 web.xml 에 넣어주면 된다.
- <?xml version="1.0"?>
- <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
- "http://java.sun.com/dtd/web-app_2_3.dtd">
- <web-app>
- <display-name>My Application</display-name>
- <filter>
- <filter-name>struts2</filter-name>
- <filter-class>filters.StrutsRedirectFilter</filter-class>
- </filter>
- <filter-mapping>
- <filter-name>struts2</filter-name>
- <url-pattern>/*</url-pattern>
- </filter-mapping>
- </web-app>
script에서 get방식으로 변수를 넘길 때, &, +, ? 등 특수문자를 그대로
변수로 넘길 때 사용하는 tip
변수를 escape()로 처리한다.
location.href="list.jsp?no=1&title=red&blue"
이런경우 title의 red&blue의 경우 &로 인해 변수로 넘길때 짤리게 된다.
이럴때,
location.href="list.jsp?no=1&title="+escape("red&blue");
이렇게 하면 변수가 짤리지 않고 넘길 수 있따.
[출처] 특수문자(&, + 등)를 get방식 변수로 넘기기|작성자 레인루카
2006 년 초, John Resig가 만든 jQuery는 JavaScript 코드로 작업하는 사람들에게는 훌륭한 라이브러리이다. 여러분이 JavaScript 언어 초보자라서 라이브러리가 Document Object Model (DOM) 스크립팅과 Ajax의 복잡성을 다루어주기를 원하든지, 숙련된 JavaScript 구루로서 DOM 스크립팅과 Ajax의 반복성에 지루해졌다면, jQuery가 제격이다.
jQuery는 코드를 단순하고 간결하게 유지한다. 많은 반복 루프와 DOM 스크립팅 라이브러리 호출을 작성할 필요가 없다. jQuery를 사용하면 매우 적은 문자로 표현할 수 있다.
jQuery 철학은 매우 독특하다. 무엇이든 단순하고 재사용 가능한 것으로 유지하기 위해 디자인 되었다. 여러분이 이러한 철학을 이해하고 여기에 편안함을 느낀다면, jQuery가 여러분의 프로그래밍 방식을 충분히 향상시킬 수 있다.
|
다 음은 jQuery가 여러분의 코드에 어떤 영향을 미치는지를 보여주는 예제이다. 페이지의 모든 링크에 클릭 이벤트를 붙이는 것 같이 단순하고 일반적인 것을 수행하려면, 플레인 JavaScript 코드와 DOM 스크립팅을 사용하는 것이 낫다. (Listing 1)
Listing 1. jQuery 없는 DOM 스크립팅
var external_links = document.getElementById('external_links');
var links = external_links.getElementsByTagName('a');
for (var i=0;i < links.length;i++) {
var link = links.item(i);
link.onclick = function() {
return confirm('You are going to visit: ' + this.href);
};
}
|
Listing 2는 같은 기능에 jQuery를 사용한 모습이다.
Listing 2. jQuery를 사용한 DOM 스크립팅
$('#external_links a').click(function() {
return confirm('You are going to visit: ' + this.href);
});
|
놀랍지 않은가? jQuery를 사용하면 복잡하지 않게 코드로 표현하고자 하는 것만 나타낼 수 있다. 엘리먼트를 반복할 필요가 없다. click() 함수가 이 모든 것을 관리한다. 또한, 다중 DOM 스크립팅 호출도 필요 없다. 여기에서 필요한 것은 엘리먼트가 어떻게 작동하는지를 설명하는 짧은 스트링이다.
이 코드로 어떻게 작업이 수행되는지를 이해하기는 조금 어렵다. 우선, $() 함수가 있어야 한다. 이것은 jQuery에서 가장 강력한 함수이다. 대게, 이 함수를 사용하여 문서에서 엘리먼트를 선택한다. 이 예제에서, 이 함수는 Cascading Style Sheets (CSS) 신택스를 포함하고 있는 스트링으로 전달되고, jQuery는 효율적으로 이 엘리먼트를 찾는다.
CSS 셀렉터의 기본을 이해하고 있다면, 이 신택스가 익숙할 것이다. Listing 2에서, #external_links는 external_links의 id를 가진 엘리먼트를 찾는다. a 앞에 있는 공간은 jQuery에게 external_links 엘리먼트 내의 모든 <a> 엘리먼트를 찾도록 명령한다. 영어와 DOM은 장황하지만, CSS에서는 매우 간단하다.
$() 함수는 CSS 셀렉터와 매치하는 모든 엘리먼트를 포함하고 있는 jQuery 객체를 리턴한다. jQuery 객체는 어레이와 비슷하지만, 수 많은 특별한 jQuery 함수들이 포함된다. 예를 들어, click 함수를 호출함으로써 클릭 핸들러 함수를 jQuery 객체의 각 엘리먼트에 할당할 수 있다.
또한, 엘리먼트나 엘리먼트의 어레이를 $() 함수로 전달하면, 이것은 엘리먼트 주위에 jQuery 객체를 래핑할 것이다. 이 기능을 사용하여 window 객체 같은 것에 jQuery 함수를 적용하고 싶을 것이다. 일반적으로 이 함수를 다음과 같이 로드 이벤트에 할당한다.
window.onload = function() {
// do this stuff when the page is done loading
};
|
jQuery를 사용하면, 같은 코드도 다음과 같이 된다.
$(window).load(function() {
// run this when the whole page has been downloaded
});
|
이미 알고 있었겠지만, 윈도우가 로딩하기를 기다리는 일은 매우 지루한 일이다. 전체 페이지가 로딩을 끝마쳐야 하기 때문이다. 여기에는 페이지의 모든 이미지들도 포함된다. 가끔, 이미지 로딩을 먼저 끝내고 싶지만, 대부분의 경우 Hypertext Markup Language (HTML)만 로딩해야 한다. jQuery는 문서에 특별한 ready 이벤트를 만듦으로써 이 문제를 해결한다.
$(document).ready(function() {
// do this stuff when the HTML is all ready
});
|
이 코드는 document 엘리먼트 주위에 jQuery 객체를 만들고, HTML DOM 문서가 준비될 때 함수를 설정하여 인스턴스를 호출한다. 이 함수를 필요한 만큼 호출할 수 있다. 진정한 jQuery 스타일에서, 지름길은 이 함수를 호출하는 것이다. 함수를 $() 함수로 전달한다.
$(function() {
// run this when the HTML is done downloading
});
|
지금까지, $() 함수를 사용하는 세 가지 방법을 설명했다. 네 번째 방법은, 스트링을 사용하여 엘리먼트를 만드는 것이다. 결과는, 그 엘리먼트를 포함하고 있는 jQuery 객체가 된다. Listing 3은 문단을 페이지에 추가하는 예제이다.
Listing 3. 간단한 문단을 생성하여 붙이기
$('<p></p>')
.html('Hey World!')
.css('background', 'yellow')
.appendTo("body");
|
$('#message').css('background', 'yellow').html('Hello!').show();
|
|
Ajax는 jQuery를 사용하면 더 단순해 질 수 있다. jQuery에는 쉬운 것도 쉽게 복잡한 것도 가능한 단순하게 만드는 유용한 함수들이 많이 있다.
Ajax에서 사용되는 방식은 HTML 청크를 페이지 영역에 로딩하는 것이다. 여러분이 필요로 하는 엘리먼트를 선택하고 load() 함수를 사용하는 것이다. 다음은 통계를 업데이트 하는 예제이다.
$('#stats').load('stats.html');
|
일부 매개변수들을 서버 상의 페이지로 전달해야 할 경우가 종종 있다. jQuery를 사용하면 이는 매우 간단하다. 필요한 메소드가 어떤 것인지에 따라서 $.post()와 $.get() 중 선택한다. 선택적 데이터 객체와 콜백 함수를 전달할 수도 있다. Listing 4는 데이터를 보내고 콜백을 사용하는 예제이다.
Listing 4. Ajax를 사용하여 데이터를 페이지로 보내기
$.post('save.cgi', {
text: 'my string',
number: 23
}, function() {
alert('Your data has been saved.');
});
|
복잡한 Ajax 스크립팅을 해야 한다면, $.ajax() 함수가 필요하다. xml, html, script, json을 지정할 수 있고, 여러분이 바로 사용할 수 있도록 jQuery가 자동으로 콜백 함수에 대한 결과를 준비한다. 또한, beforeSend, error, success, complete 콜백을 지정하여 사용자에게 Ajax에 대한 더 많은 피드백을 제공할 수 있다. 게다가, Ajax 요청의 타임아웃이나 페이지의 "최종 변경" 상태를 설정하는 매개변수들도 있다. Listing 5는 필자가 언급했던 매개변수를 사용하여 XML 문서를 검색하는 예제이다.
Listing 5. $.ajax()를 사용하여 복잡한 Ajax를 단순하게
$.ajax({
url: 'document.xml',
type: 'GET',
dataType: 'xml',
timeout: 1000,
error: function(){
alert('Error loading XML document');
},
success: function(xml){
// do something with xml
}
});
|
콜백 성공으로 XML을 받으면, jQuery를 사용하여 HTML에서 했던 것과 같은 방식으로 XML을 볼 수 있다. 이는 XML 문서 작업을 쉽게 하며 콘텐트와 데이터를 웹 사이트로 쉽게 통합시킨다. Listing 6은 리스트 아이템을 XML의 <item> 엘리먼트용 웹 페이지에 추가하는 success 함수에 대한 확장 모습이다.
Listing 6. jQuery를 사용하여 XML 작업하기
success: function(xml){
$(xml).find('item').each(function(){
var item_text = $(this).text();
$('<li></li>')
.html(item_text)
.appendTo('ol');
});
}
|
|
jQuery를 사용하여 기본적인 애니메이션과 효과를 다룰 수 있다. 애니메이션 코드의 중심에는 animate() 함수가 있는데, 이는 숫자로 된 CSS 스타일 값을 바꾼다. 예를 들어, 높이, 넓이, 폭, 위치를 움직일 수 있다. 또한, 애니메이션의 속도를 밀리초 또는 사전 정의된 속도(느림, 보통, 빠름)로 지정할 수 있다.
다음은, 엘리먼트의 높이와 넓이를 동시에 움직이게 하는 예제이다. 시작 값은 없고 종료 값만 있다. 시작 값은 엘리먼트의 현재 크기에서 가져온다. 여기에도 콜백 함수를 첨부했다.
$('#grow').animate({ height: 500, width: 500 }, "slow", function(){
alert('The element is done growing!');
});
|
jQuery는 빌트인 함수를 사용하여 일반적인 애니메이션도 더욱 쉽게 만든다. show()와 hide() 엘리먼트를 즉각적으로 또는 지정된 속도로 사용할 수 있다. fadeIn()과 fadeOut() 또는 slideDown()과 slideUp()을 사용하여 엘리먼트를 나타나게 하거나 사라지게 할 수 있다. 다음은 네비게이션의 slidedown 예제이다.
$('#nav').slideDown('slow');
|
|
jQuery는 DOM 스크립팅과 이벤트 핸들링을 단순화하는데 제격이다. DOM의 트래버스와 조작이 쉽고, 이벤트의 첨부, 제거, 호출은 매우 자연스러운 일이며, 직접 수행하는 것보다 에러도 적게 발생한다.
기본적으로 jQuery는 DOM 스크립팅으로 수행하는 일들을 더욱 쉽게 수행할 수 있도록 해준다. 엘리먼트를 생성하고 append() 함수를 사용하여 이들을 다른 엘리먼트로 연결할 수 있고, clone()을 사용하여 엘리먼트를 중복시키고, 콘텐트를 html()로 설정하고, empty() 함수로 콘텐트를 삭제하고, remove() 함수로 엘리먼트를 삭제하고, wrap() 함수를 사용하여 또 다른 엘리먼트로 엘리먼트를 래핑한다.
DOM을 트래버스 함으로써 jQuery 객체의 콘텐트를 변경할 때 여러 함수들을 사용할 수 있다. 엘리먼트의 siblings(), parents(), children()을 사용할 수 있다. 또한, next() 또는 prev() sibling 엘리먼트도 선택할 수 있다. 아마도 가장 강력한 것은 find() 함수일 것이다. jQuery 셀렉터를 사용하여 jQuery 객체의 엘리먼트 종속 관계들을 통해 검색할 수 있다.
이 함수는 end() 함수와 사용될 때 더욱 강력해진다. 이 함수는 실행 취소 함수와 비슷하고, find() 또는 parents() 또는 다른 트래버싱 함수들을 호출하기 전에 가졌던 jQuery 객체로 돌아간다.
메소드 체인과 함께 사용되면, 복잡한 연산도 단순하게 보이게 할 수 있다. Listing 7은 로그인 폼을 찾고 이와 관련한 여러 엘리먼트를 조작하는 예제이다.
Listing 7. DOM의 트래버스와 조작
$('form#login')
// hide all the labels inside the form with the 'optional' class
.find('label.optional').hide().end()
// add a red border to any password fields in the form
.find('input:password').css('border', '1px solid red').end()
// add a submit handler to the form
.submit(function(){
return confirm('Are you sure you want to submit?');
});
|
믿을 수 있는지 모르겠지만, 이 예제는, 공백을 사용한 하나의 연결된 코드 라인일 뿐이다. 우선, 로그인 폼을 선택했다. 그리고 나서, 이 안에 선택 레이블을 찾고, 이들을 숨긴 다음, end()를 호출하여 폼으로 돌아가게 하였다. 패스워드 필드를 찾았고, 보더를 빨간색으로 한 다음, 다시 end()를 호출하여 폼으로 돌아갔다. 마지막으로, 제출 이벤트 핸들러를 폼에 추가했다. 여기에서 특히 재미있는 부분은 jQuery가 모든 쿼리 연산들을 최적화 하기 때문에, 여러분은 모든 것이 서로 잘 연결될 때 엘리먼트를 두 번 찾을 필요가 없다.
공통 이벤트 핸들링은 click(), submit(), mouseover() 같은 함수를 호출하고 여기에 이벤트 핸들러 함수를 전달하는 것만큼 단순하다. 게다가, bind('eventname', function(){})을 사용하여 커스텀 이벤트 핸들러를 할당하는 옵션도 있다. unbind('eventname')를 사용하여 특정 이벤트를 제거하거나, unbind()를 사용하여 모든 이벤트를 제거할 수 있다. 이것과 기타 함수들을 사용하는 다른 방법들은, jQuery 애플리케이션 프로그램 인터페이스(API) 문서를 참조하라. (참고자료)
|
#myid 같은 아이디 또는 div.myclass 같은 클래스 이름으로 엘리먼트를 선택한다. 하지만, jQuery는 하나의 셀렉터에서 거의 모든 엘리먼트 조합을 선택할 수 있도록 하는 복잡하고도 완벽한 셀렉터 신택스를 갖고 있다.
jQuery의 셀렉터 신택스는 CSS3과 XPath에 기반하고 있다. CSS3과 XPath 신택스를 더욱 잘 안다면, jQuery 사용이 더욱 수월해진다. CSS와 XPath를 포함하여 jQuery 셀렉터의 전체 리스트를 보려면 참고자료 섹션을 참조하라.
CSS3 에는 모든 브라우저가 지원하지 않는 신택스가 포함되어 있기 때문에, 이를 자주 볼 수 없다. 하지만, jQuery에서 CSS3을 사용하여 엘리먼트를 선택한다. jQuery는 고유의 커스텀 셀렉터 엔진을 갖고 있다. 예를 들어, 테이블의 모든 빈 컬럼 안에 대시(dash)를 추가하려면, :empty pseudo-selector를 사용한다.
$('td:empty').html('-');
|
특정 클래스를 갖고 있지 않은 모든 엘리먼트를 찾는다면? CSS3은 이를 위한 신택스도 있다. :not pseudo-selector를 사용하는 것이다. 다음은 required의 클래스를 갖고 있지 않은 모든 인풋을 숨기는 방법이다.
$('input:not(.required)').hide();
|
또한, CSS에서처럼 다중 셀렉터를 콤마를 사용하여 하나로 연결시킬 수 있다. 다음은 이 페이지에서 모든 리스트 유형들을 동시에 숨기는 예제이다.
$('ul, ol, dl').hide();
|
XPath는 하나의 문서에서 엘리먼트를 찾는 강력한 신택스이다. CSS와는 다르며, CSS로 수행할 수 없는 몇 가지 일을 수행할 수 있다. 보더를 모든 체크 박스의 부모 엘리먼트에 추가하려면, XPath의 /.. 신택스를 사용할 수 있다.
$("input:checkbox/..").css('border', '1px solid #777');
|
가독성 있는 테이블을 만들려면, 다른 클래스 이름을 테이블의 모든 짝수 또는 홀수 행에 붙인다. 이를 다른 말로 테이블의 스트라이핑(striping)이라고 한다. jQuery를 사용하면 :odd pseudo-selector 덕택에 쉽게 수행할 수 있다. 아래 예제는 테이블의 모든 홀수 행의 백그라운드를 striped 클래스를 사용하여 변경한다.
$('table.striped > tr:odd').css('background', '#999999');
|
jQuery 셀렉터로 코드를 어느 정도 단순화 할 수 있는지를 보았다. 어떤 엘리먼트를 선택하든지 간에, 하나의 jQuery 셀렉터를 사용하여 이를 정의하는 방법도 찾을 수 있다.
|
대 부분의 소프트웨어와는 달리, jQuery용 플러그인 작성은 복잡한 API를 사용해야 하는 힘든 일이 아니다. 사실, jQuery 플러그인은 작성하기가 쉬워서 몇 가지만 작성하면 코드를 더욱 단순하게 유지할 수 있다. 다음은 여러분이 작성할 수 있는 가장 기본적인 jQuery 플러그인이다.
$.fn.donothing = function(){
return this;
};
|
단순하지만, 이 플러그인은 약간의 설명이 필요하다. 우선, 함수를 모든 jQuery 객체에 추가하려면, 여기에 $.fn을 할당하고, 이 함수는 this (jQuery 객체)를 리턴하여 이것이 메소드 체인을 깨트리지 않도록 해야 한다.
이 예제를 기반으로 쉽게 구현할 수 있다. css('background')를 사용하는 대신 플러그인을 작성하여 백그라운드를 바꾸려면, 다음을 사용한다.
$.fn.background = function(bg){
return this.css('background', bg);
};
|
css()에서 값을 리턴할 뿐이다. 이것은 이미 jQuery 객체를 리턴하기 때문이다. 따라서, 메소드 체인은 여전이 잘 작동한다.
여러분은 반복 작업이 있을 경우에 jQuery 플러그인을 사용하기 바란다. 예를 들어, 같은 일을 여러 번 수행하기 위해 each() 함수를 사용하고 있다면 플러그인을 사용해도 된다.
jQuery 플러그인을 작성이 쉽기 때문에, 여러분이 사용할 수 있는 것도 수백 가지나 존재한다. jQuery는 탭, 곡선형 코너, 슬라이드 쇼, 툴 팁, 날짜 셀렉터, 기타 여러분이 상상하고 있는 모든 것을 위한 플러그인이 있다. 플러그인 리스트는 참고자료 섹션을 참조하기 바란다.
가 장 복잡하고 광범위하게 사용되는 플러그인은 Interface이다. 이것은 정렬, 드래그&드롭 기능, 복합 효과, 기타 복잡한 사용자 인터페이스(UI)를 핸들하는 애니메이션 플러그인이다. Interface가 jQuery를 위한 것이라면 Prototype에는 Scriptaculous가 있다.
또한 Form 플러그인도 대중적이고 유용하다. 이것으로 Ajax를 사용하여 백그라운드에서 폼을 쉽게 제출할 수 있다. 이 플러그인은 폼의 제출 이벤트를 하이재킹 하고, 다른 인풋 필드를 찾고, 이들을 사용하여 Ajax 호출을 구현하는 상황에 사용된다.
|
jQuery 를 사용하여 할 수 있는 것의 표면적인 부분만 다루었다. jQuery는 기분 좋게 사용할 수 있고 새로운 트릭이나 기능도 자연스럽다. jQuery는 JavaScript와 Ajax 프로그래밍을 매우 단순화 시킬 수 있다. 새로운 것을 배울 때마다 코드는 더욱 단순해 진다.
jQuery를 배운 후에, 필자는 JavaScript 언어로 하는 프로그래밍에 재미를 발견했다. 지루한 부분은 알아서 처리되기 때문에, 필자는 중요한 코딩 부분에만 집중하면 된다. jQuery를 사용하게 되면서 지난날 for 루프를 작성하던 때는 거의 기억이 나지 않는다. 심지어, 다른 JavaScript 라이브러리를 사용할 생각도 거의 하지 않는다. jQuery는 JavaScript 프로그래밍 방식을 진정으로 바꿔 놓았다.
교육
- 한국 developerWorks XML 존: 한국 developerWorks XML 존에서 XML 관련 자료를 더 볼 수 있다.
- jQuery API 문서
- jQuery 튜토리얼
- Visual jQuery: jQuery API 레퍼런스.
- IBM XML 인증: XML 분야의 IBM 인증 개발자에 도전하십시오.
- XML 기술 자료: 한국 developerWorks XML 존에서 다양한 기술 자료, 팁, 튜토리얼, 표준, IBM Redbook 참고하기.
제품 및 기술 얻기
- jQuery: jQuery 메인 사이트를 방문해 소프코드 다운로드 하기.
- Selectors: CSS3과 XPath 셀렉터를 포함하여 jQuery에 사용되는 모든 셀렉터들.
- jQuery 플러그인
- Interface
- Form 플러그인
토론
- jQuery 블로그: : 공식 jQuery 블로그에서 정규 뉴스와 업데이트 확인하기.
- XML 존 토론 포럼
|
|
Jesse Skinner는 JavaScript와 CSS 전문 프리랜스 웹 개발자이다. 캐나다와 독일이 주 활동 무대이며, CSS 브라우저 호환성 미스터리를 풀고 있다. Jesse에 대해 더욱 알고 싶거나 웹 개발에 대한 글을 더 읽고 싶다면, 블로그 The Future of the Web를 방문해 보라. | |

jQuery는
AJAX와 같은 Javascript의 기능을 사용하기 쉽도록 만들어주는 일종의 Library 입니다.
protype과 같이 잘 알려진 몇가지가 있지만
jQuery는 19KB의 소형이지만 다양한 plugin과 함께 아주 강력한 기능을 제공해 줍니다.
(※ 자세한 정보는 다음 링크 페이지를 참조하세요. ▤)
다음 예제는
jQuery, JSP와 MySQL을 이용한 아주 간단한 채팅 예제 입니다.
앞의 DynamicUpdate 페이지에서 보인
AJAX 기능을 jQuery를 이용하여 간단히 사용자와의 interaction을 강화한 버전이라 할 수 있습니다.
예제는 두 개의 파일로 구성됩니다.
(1) 클라이언트측 AjaxChat.html 파일은 주기적으로 서버에 최근 대화내용을 요청해서 지정된 화면 영역에 추가한다. 또한 사용자의 대화를 서버에 요청하여 저장하도록 합니다.
<html>
<head>
<title>Chat Example in AJAX with jQuery</title>
<meta http-equiv="content-type" content="text/html; charset=euc-kr"><script type="text/javascript" src="/your/path/jquery-1.1.2.js"></script>
<script type="text/javascript">
$(document).ready(function(){
timestamp = 0;
updateMsg();
$("form#chatform").submit(function(){
$.post("/your/path/AjaxChatServer.jsp",{
message: $("#msg").val(),
name: $("#author").val(),
action: "postmsg",
time: timestamp
}, function(xml) {
$("#msg").empty();
addMessages(xml);
});
return false;
});
});
function addMessages(xml) {
if($("status",xml).text() == "2") return;
timestamp = $("time",xml).text();
$("message",xml).each(function(id) {
message = $("message",xml).get(id);
$("#messagewindow").prepend("<b>"+$("author",message).text()+
"</b>: "+$("text",message).text()+
"<br />");
});
}
function updateMsg() {
$.post("/your/path/AjaxChatServer.jsp",{ time: timestamp }, function(xml) {
$("#loading").remove();
addMessages(xml);
});
setTimeout('updateMsg()', 4000);
}
</script>
<style type="text/css">
#messagewindow {
height: 250px;
border: 1px solid;
padding: 5px;
overflow: auto;
}
#wrapper {
margin: auto;
width: 550px;
}
</style>
</head>
<body>
<div id="wrapper">
<p id="messagewindow"><span id="loading">Loading...</span></p>
<form id="chatform">
이름: <input type="text" size="8" id="author" />
메시지: <input type="text" size="45" id="msg" />
<input type="submit" value=" OK " /><br />
</form>
</div>
</body>
</html>
(2) 서버측 AjaxChatServer.jsp 파일은 클라이언트의 대화내용을 건네받아 저장하고 최근 대화내용을 요청한 클라이언트에게 xml 형식으로 저장합니다.
<%@ page contentType="text/html; charset=utf-8" pageEncoding="euc-kr" %>
<%!
/**
* @(#) AjaxChatServer.jsp
*
* Copyright ⓒ 1999-2007 by (c) CheckersLab.com
* All rights reserved.
*
* NOTICE : Refer our copy and redistribution policy guide.
*
* @author Hoyal Kim, hoyal.kim@gmail.com
*
* ---------------------------------------
*
* Script of Creating Table in mySQL
*
CREATE TABLE ajaxchat (
id int NOT NULL auto_increment,
user varchar(255) NOT NULL,
msg text NOT NULL,
time int NOT NULL,
PRIMARY KEY (id)
);
*
*/
%><%@ page import="java.io.*" %>
<%@ page import="java.net.*" %>
<%@ page import="java.sql.*" %>
<%@ page import="java.util.*" %>
<%@ page import="java.text.MessageFormat" %><%
String action = request.getParameter("action");
if(action == null) action = "";
String timestamp = request.getParameter("time");
if(timestamp == null) timestamp = "0";
String name = request.getParameter("name");
if(name == null) name = "No Name";
String message = request.getParameter("message");
if(message == null) message = "No Message";// Append the message --------------------
if (action.equals("postmsg")) {
String msg_ins = putMessage(name, message);
}// Fetch the recent message ----------------
Vector msgList = getMessage(timestamp);
int status_code = 1;
if(msgList.size() == 0) status_code = 2;// Output the messages -------------------
response.setContentType("text/xml; charset=utf-8");
response.setHeader("Pragma","no-cache");
response.setDateHeader("Expires",0);
response.setHeader("Cache-Control","no-store");
if (request.getProtocol().equals("HTTP/1.1"))
response.setHeader("Cache-Control", "no-cache");out.println("<?xml version=\"1.0\"?>");
out.println("<response>");
out.println("\t<status>" + status_code + "</status>");
out.println("\t<time>" + System.currentTimeMillis() + "</time>");if(status_code == 1) {
for (int idx = 0; idx < msgList.size(); idx++) {
String msgs[] = split((String) msgList.elementAt(idx), CHAR_DELIM);
out.println("\t<message>");
out.println("\t\t<author>" + msgs[0] + "</author>");
out.println("\t\t<text>" + msgs[1] + "</text>");
out.println("\t</message>");
}
}
out.println("</response>");
%><%!
private final static int NUM_STORE = 10;
private final static int NUM_DISPLAY = 10;
private final static String CHAR_DELIM = "|";private final static String DB_DRIVER = "org.gjt.mm.mysql.Driver";
private final static String DB_URL = "jdbc:mysql://yourhost/dbname";
private final static String DB_USER = "user_id";
private final static String DB_PSWD= "password";private final static String QRY_GET = "SELECT user, msg FROM ajaxchat WHERE time > {0} ORDER BY id ASC";
private final static String QRY_INS = "INSERT INTO ajaxchat (user, msg, time) VALUES (\"{0}\", \"{1}\", {2})";
/**
* 주어진 시간 이후의 메시지를 가져온다.
*/
private Vector getMessage(String timestamp)
{
Vector list = new Vector();
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Class.forName(DB_DRIVER);
conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PSWD);
stmt = conn.createStatement();
stmt.setMaxRows(NUM_DISPLAY);String msg_data[] = { timestamp };
MessageFormat mf = new MessageFormat(QRY_GET);
String query = mf.format(msg_data);
rs = stmt.executeQuery(query);
while (rs.next()) {
StringBuffer article = new StringBuffer();
article.append(rs.getString("user"));
article.append(CHAR_DELIM);
article.append(rs.getString("msg"));
list.addElement(article.toString());
}
}
catch(Exception ex) {
list.addElement("error|" + ex.toString());
}
finally {
if (rs != null) try { rs.close(); }catch(Exception e){}
if (stmt != null) {
try { stmt.setMaxRows(0); stmt.close(); } catch(Exception e){}
}
if (conn != null) try { conn.close(); } catch(Exception e){}
}
return list;
}/**
* 하나의 문자열을 주어진 구분문자를 기준으로 나누어 문자열의 배열로 변환한다.
*/
public static synchronized String[] split(String str, String delim)
{
Vector v = new Vector();
StringTokenizer tokenizer = new StringTokenizer(str, delim);
while (tokenizer.hasMoreTokens()) {
v.addElement(tokenizer.nextToken());
}
String[] ret = new String[v.size()];
for (int i = 0; i < ret.length; i++) {
ret[i] = (String) v.elementAt(i);
}
return ret;
}/**
* 특정 문자(열)를 지정한 문자(열)로 바꾸어준다.
*/
public static synchronized String replace(String dataStr, String oldStr, String newStr)
{
int index = 0;
StringBuffer sb = new StringBuffer(dataStr);
String buf = sb.toString();
while ( (index = buf.indexOf(oldStr, index) ) >= 0)
{
sb = new StringBuffer(buf.substring(0, index)); // Left
sb.append(newStr); // Replaced String
sb.append(buf.substring(index + oldStr.length())); // Right
buf = sb.toString();
index += newStr.length(); // Next Position
}
return buf;
}/**
* 새로운 행을 추가한다.
*/
private String putMessage(String name, String message)
{
String msg = "";Connection conn = null;
Statement stmt = null;
String query_ins = "";
try {
Class.forName(DB_DRIVER);
conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PSWD);
stmt = conn.createStatement();message = replace(message, "<", "<");
message = replace(message, ">", ">");
String timestamp = System.currentTimeMillis()+"";String msg_data[] = { name, message, timestamp };
MessageFormat mf = new MessageFormat(QRY_INS);
//String
query_ins = mf.format(msg_data);
stmt.executeUpdate(query_ins);
}
catch(Exception ex) {
msg = query_ins; //ex.toString();
}
finally {
if (stmt != null) try { stmt.close(); } catch(Exception e){}
if (conn != null) try { conn.close(); } catch(Exception e){}
}
return msg;
}%>
Struts2는 WebWork와 통합되어 있다는 사실은 누구나 알고 있습니다.
WebWork는 XWork를 기반으로한 Web MVC 프레임워크 라는 사실 또한 누구나 알고 있을 것 입니다.
여기서 XWork는 IoC 컨테이너 입니다. 스프링2.5에서 @Autowire 애노테이션으로 의존성을 주입하듯이
XWork에서는 @Inject 라는 애노테이션으로 의존성을 주입합니다.
Struts2는 WebWork와 적절히 통합되어 있습니다.
Struts2의 API 대부분의 setter 메서드에서는 @Inject 애노테이션이 사용 되어지고 있습니다.
@Inject 애노테이션의 속성은 value 와 required 두 가지 입니다.
value는 XWork Container에 존재하는 인스턴스의 이름을 지정하는 속성이며 기본 값은 "default" 라는 문자열 입니다. required 속성은 필수여부인데 true일 경우 Contanier내에 반드시 존재해야 합니다. 만약 존재하지 않으면
예외를 뿜어냅니다.
여기까지가 기본적으로 알고 있어야 하는 간단한 지식이고 이제 본론으로 들어가서...
struts-default.xml 에 보면 Struts2 에서 사용되는 객체들을 <bean /> 요소로 아주 많이 선언해 두었습니다.
모든 핵심 클래스들이 선언되어 있죠... 그리고 위에서 밝혔듯이 Struts2 API는 @Inejct 애노테이션이 마구마구
사용되어 지고 있는 상태 입니다. Struts2가 구동시 <bean /> 요소로 선언된 클래스들을 생성하고 필요한 곳에
주입 됩니다. 아래 몇 가지 예가 있습니다.
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="composite" class="org.apache.struts2.dispatcher.mapper.CompositeActionMapper" />
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="restful" class="org.apache.struts2.dispatcher.mapper.RestfulActionMapper" />
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="restful2" class="org.apache.struts2.dispatcher.mapper.Restful2ActionMapper" />
그 밖에도 다른 <bean /> 요소로 선언된 것 중에서 역시 name 속성이 "struts" 인 것만 사용 됩니다.
그래서 저는 추측 했습니다.
개발자가 별도로 <bean /> 요소로 선언할 때 name 속성을 "struts"로 줘야 하는구나...
그리고 ActionEventListener를 당장 만들어서 선언한 뒤 name 값을 "struts"로 주었습니다.
하지만 이 객체는 DefaultActionProxy 에 주입되지 않았습니다.
당연한 결과 였습니다. DefaultActionProxy에는 단지 @Ineject(required=false) 로만 선언되어 있었기 때문에
name 속성이 "struts"로 되어있는 ActionEventListener 객체를 찾지 못하는 것 이었습니다.
(@Inject() 애노테이션의 value 속성의 기본값은 "default" 이기 때문에 "default" 로 찾습니다.)
그런데 뭔가 이상 합니다.
분명 struts-default.xml 에 수많은 <bean /> 요소들의 name 속성은 "struts"로 되어 있고
그 객체들을 필요로 하는 곳에서는 단지 @Inejct() 로만 요청하고 있는데 name 값이 틀림에도 불구하고
어떻게 정상적으로 의존성 주입이 되는 것일까...
처음에 디버깅 할 때는 객체를 찾아오는 부분에서 시작했습니다. 여기서 대부분의 시간을 보냈지만 답을 찾을 수 없었습니다. 그래서 초심으로 돌아가서 FilterDispatcher의 init() 메서드부터 차근차근 보았습니다.
디버깅을 하면서 XWork의 초기화 과정을 발견 했는데 Struts2에서 XWork를 초기화 할 때
XWork의 생명주기 관련 인터페이스인 ConfigurationProvider 의 구현체들을 등록하는 것을 발견 했습니다.
그 중에서 BeanSelectionProvider 가 있는데 이 클래스가 해답 이었습니다.
XWork의 초기화 과정에서 BeanSelectionProvider.register() 메서드가 호출 되는데 이 메서드에서
특정 타입이면서 name 값이 "struts"인 객체들의 name 값을 "default" 로 바꿔 주는 것 입니다.
그래서 정상적으로 의존성 주입이 되고 있었던 것 입니다.
특정 타입의 목록은 다음과 같습니다.
XWorkConverter.class
TextProvider.class
ActionProxyFactory.class
ObjectTypeDeterminer.class
ActionMapper.class
MultiPartRequest.class
FreemarkerManager.class
VelocityManager.class
위 타입 이외에 것들은 (UnknownHandler, ActionEventListener)
<bean /> 요소로 선언 할 때 name 속성은 무턱대고 "struts" 로 지정할 경우 정상적으로 작동 되지 않습니다.
그냥 name 속성을 생략 하거나 동일한 타입이 여러개일 경우 주입하고자 하는 <bean /> 요소에 name 속성을
"default" 로 설정 하면 됩니다.
특정 테이블(DATA_TBL)에 대해서 트리거를 걸고,
해당 이벤트를 기록하는 테이블(LOG_TBL) 이 존재한다고 할때, 테이블당 하나씩
트리거를 걸면 되므로 심플하게 되는데...
종종 이런로그를 쌓을때, 특정 자료들을 가공해서 써야 할때가 있습니다.
| 게시판코드 | 게시판번호 | 제목 | 본문 |
| BBS_001 | 0001 | 테스트제목1 | 본문입니다 |
| BBS_001 | 0002 | 테스트제목2~ | 본문2 |
| BBS_004 | 001 | 어때..이힝 | 정민철 메롱 |
다수의 게시판이 아니라,
하나의 게시판에 게시판 코드로 구분되어 만들어 지는 경우...
게시판 코드가 아니라...
BBS_001 , BBS_002, BBS_003 게시판은 ===> 멀티미디어게시판
BBS_004 , BBS_005, BBS_006 게시판은 ===> 텍스트게시판
나머지 ===> 기타게시판
뭐 묶음으로 로그를 남긴다고 해야하나??
아니면 분류를 새로 해서 로그를 남긴거나 아무튼 이런겁니다.
[샘플예제]
오라클기준으로 작성하였답니다
> KONAN_TEST (트리거가 걸릴 테이블)
| BBS_CODE | TITLE | BODY |
> KONAN_TEST_LOG (KONAN_TEST의 로그가 쌓일곳)
| LOGID (로그고유번호 rowid로함) | TABLENAME (해당 테이블명) | EVENT (업데이트, 삽입, 삭제) |
> kw_logtest
TRIGGER kw_logtest
AFTER INSERT OR DELETE OR UPDATE ON KONAN_TEST
FOR EACH ROW
DECLARE
tbl_name VARCHAR2(30) := ''; --테이블명
BEGIN
-- 테이블코드 가져오기
IF INSERTING THEN
IF (UPPER(:new.BBS_CODE) in ('BBS_01', 'BBS_02', 'BBS_03')) THEN
tbl_name := '게시판1-3';
ELSIF (UPPER(:new.BBS_CODE) in ('BBS_04', 'BBS_05', 'BBS_06')) THEN
tbl_name := '게시판4-6'
ELSE
tbl_name := '기타게시판';
END IF;
ELSE
IF (UPPER(:old.BBS_CODE) in ('BBS_01', 'BBS_02', 'BBS_03')) THEN
tbl_name := '멀티미디어게시판';
ELSIF (UPPER(:old.BBS_CODE) in ('BBS_04', 'BBS_05', 'BBS_06')) THEN
tbl_name := '게시판1-3';
ELSE
tbl_name := '게시판4-6'
END IF;
END IF;
--실제로그쌓기
IF INSERTING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:new.rowid, tbl_name ,'I');
ELSIF DELETING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:old.rowid, tbl_name, 'D');
ELSIF UPDATING THEN
INSERT INTO KONAN_TEST_LOG(LOGID,TABLENAME, event)
VALUES(:old.rowid,tbl_name, 'U');
END IF;
END;
[테스트결과]
| 단계1. 삽입(Insert) | 단계2. 수정(Update) | 단계3. 삭제(Delete) |
|
|
|
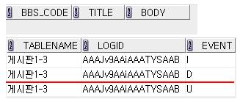 |
이런식으로 로그테이블에 해당 이벤트와 BBS_CODE가 아닌
재정의한 게시판 1-3 같은내용이 들어가는것!
 struts2_커스텀태그_개발자가이드.doc
struts2_커스텀태그_개발자가이드.doc가장 사용이 많은 경우는 두가지 구문으로 분할된다. 첫번째, application's 상태를 변경하거나 query한다. 그리고 application의 view를 갱신하여 표현하기를 필요로한다. Action class는 application의 상태를 관리하고, Result type은 view를 관리한다.
미리 정의된 Result Types
framework은 자신의 application을 개발할 준비가 된 com.opensymphony.xwork2.Result interface의 몇몇 implementation들을 제공한다.
| Chain Result | Action Chaining을 위해 사용된다. |
| Dispatcher Result |
JSP통합을 포함한 web resource통합 을 위해 사용된다. |
| FreeMarker Result |
FreeMarker 통합을 위해 사용된다. |
| HttpHeader Result |
특정 HTTP가동을 제어하기 위해 사용된다. |
| Redirect Result |
다른 URL(web resouece)에 redirect하기 위해 사용된다. |
| Redirect Action Result |
다른 action mapping에 redirect하기 위해 사용된다. |
| Stream Result |
browser로 Inputstream을 stream하기 위해 사용된다.(일반적으로 파일 다운로드를 위해) |
| Velocity Result |
Velocity통합을 위해 사용된다. |
| XSL Result |
XML/XSLT 통합을 위해 사용된다. |
| PlainText Result |
특정 page(i.e , jsp , HTML) 에 raw content를 display하기 위해 사용된다. |
| Tiles Result |
Tiles통합을 위해 사용된다. |
Optional
JasperReports Plugin은 Third-party plugin인 JasperReports Tutorial 을 선택적으로 통합하기 위해 사용된다. 추가적인 Result type은 생성 할 수 있으며, com.opensymphony.xwork2.Result interface를 implement하여 application에 plug될 수 있다.
Custom Result Type들은 email , JMS message, image 생성, 기타 등등 들을 포함한다.
Default Parameters
최소한의 설정으로는 , Result는 parameter안에 변환된 single value로 설정 할 수 있고, 각 Result는 어떤parameter가 값으로 설정되는지 묘사한다.
예를 들어, 다음 예제는 Default parameter를 사용하여 XML안에 정의된 결과 이다:
<result type="freemarker">foo.fm</result>
That is the equivalent to this:
<result type="freemarker"><param name="location">foo.vm</param></result>
대 개 application 의 95% 여러 parameter들을 포함한 결과를 필요로 하지 않기 때문에 이 간단한 중요한 많은 양의 작업 비용을 줄여준다. 또한 Default parameter를 열거할 경우 특별한 이름의 paremeter를 위해 동일 parameter들을 설정할 필요가 없다.
Registering Result Types
모든 Result Type들은 Result Configuration을 통해 plug된다.
Open Framework의 대중화를 위해 : jsHan
[출처] struts2 Result Types (한양IT Education) |작성자 오키도키
하지만 같은기능을 두개의 명령어로 사용할 필요는 없겠죠?
그래서 두 명령어의 차이점에 대해 알아보겠습니다.
TRUNCATE는 DDL, DELETE 는 DML 입니다.
DDL(Data Definition Language)은 데이터를 정의하는 언어로서 개체를 만들고 변경, 삭제하는 CREATE, ALTER, DROP문과 같은 것들을 말합니다.
DML(Data Manipulation Language)은 데이터 조작 언어로서 데이터를 가공하는 SELECT, INSERT, UPDATE, DELETE문과 같은 것들을 말합니다
구문은 다음과 같습니다.
[TRUNCATE 구문]
[DELETE 구문]
[ WITH <common_table_expression> [ ,...n ] ]
DELETE [ TOP ( expression ) [ PERCENT ] ] [ FROM ] { <object> | rowset_function_limited [ WITH ( <table_hint_limited> [ ...n ] ) ] }
[ <OUTPUT Clause> ]
[ FROM <table_source> [ ,...n ] ]
[ WHERE { <search_condition> | { [ CURRENT OF { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ]
[ OPTION ( <Query Hint> [ ,...n ] ) ] [; ]
<object> ::=
{ [ server_name.database_name.schema_name. | database_name. [ schema_name ] . | schema_name. ] table_or_view_name }
구문만 보더라도 TRUNCATE는 DELETE보다 간단한걸 볼 수 있습니다.
간단하다는 말은 TRUNCATE는 단순한 조건일 것이고 DELETE는 다양한 조건이 가능하다고 추측할 수 있습니다.
그럼 MSDN에서 두 명령어에 대해 비교해놓은 내용을 참고로 보겠습니다.
DELETE 문과 비교하여 TRUNCATE TABLE에는 다음과 같은 이점이 있습니다.
- 트랜잭션 로그 공간을 덜 사용합니다.
DELETE 문은 행을 한번에 하나씩 제거하고 삭제된 각 행에 대해 트랜잭션 로그에 항목을 기록합니다. 반면 TRUNCATE TABLE은 테이블의 데이터를 저장하는 데 사용되는 데이터 페이지의 할당을 취소하는 방식으로 데이터를 제거하며 페이지 할당 취소만을 트랜잭션 로그에 기록합니다.
- 일반적으로 적은 수의 잠금이 사용됩니다.
행 잠금을 사용하여 DELETE 문을 실행하면 삭제를 위해 테이블의 각 행이 잠깁니다. TRUNCATE TABLE은 항상 테이블과 페이지를 잠그지만 각 행은 잠그지 않습니다.
- 빈 페이지는 예외 없이 테이블에 남습니다.
DELETE 문이 실행된 후에도 테이블은 계속 빈 페이지를 포함할 수 있습니다. 예를 들어 힙의 빈 페이지는 최소한 배타적인(LCK_M_X) 테이블 잠금이 있어야만 할당 취소할 수 있으므로 삭제를 위해 테이블 잠금을 사용하지 않는 경우 테이블(힙)에는 빈 페이지가 많이 남게 됩니다. 인덱스의 경우도 삭제 작업 후에 빈 페이지가 남을 수 있지만 이러한 페이지는 백그라운드 정리 프로세스에 의해 신속하게 할당 취소됩니다.
TRUNCATE TABLE은 테이블에서 모든 행을 제거하지만 테이블 구조와 테이블의 열, 제약 조건, 인덱스 등은 그대로 남습니다. 테이블 정의 및 테이블의 데이터를 제거하려면 DROP TABLE 문을 사용하십시오.
테이블에 ID 열이 포함되어 있으면 해당 열의 카운터는 열에 대한 초기값으로 다시 설정됩니다. 초기값이 정의되어 있지 않으면 기본값인 1이 사용됩니다. ID 카운터를 보존하려면 DELETE를 대신 사용하십시오.
친절하게도 MSDN에 자세하게 설명이 되어있군요 글을 읽어보면 금방 이해가 될것이라 생각이 듭니다.
여기서 마지막 내용으로 예제를 만들어 보도록 하겠습니다.
먼저 테이블을 생성하도록 하겠습니다.
CREATE TABLE TABLENAME
( A INT IDENTITY ,B INT )
자동증가값을 가지는 A 컬럼, 정수형의 B 컬럼이 있는 TABLENAME이라는 테이블을 생성하였습니다.
INSERT INTO TABLENAME VALUES(1)
INSERT INTO TABLENAME VALUES(2)
INSERT INTO TABLENAME VALUES(3)
입력 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
1 1
2 2
3 3
DELETE문을 이용해서 전체를 삭제후 다시 입력을 해보겠습니다.
DELETE FROM TABLENAME
INSERT INTO TABLENAME VALUES(4)
INSERT INTO TABLENAME VALUES(5)
INSERT INTO TABLENAME VALUES(6)
처리된 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
4 4
5 5
6 6
(3개 행 적용됨)
전체 삭제후 새롭게 입력을 했을때 자동증값은 삭제된 항목의 최대값 다음의 증가값으로 입력된걸 확인할 수 있습니다.
이번엔 TRUNCATE문을 이용해서 삭제후 다시 입력을 해보겠습니다.
TRUNCATE TABLE TABLENAME
INSERT INTO TABLENAME VALUES(7)
INSERT INTO TABLENAME VALUES(8)
INSERT INTO TABLENAME VALUES(9)
처리된 결과를 확인해 보겠습니다.
SELECT * FROM TABLENAME
A B
----------- -----------
1 7
2 8
3 9
(3개 행 적용됨)
자동증가값이 초기값이 되고나서 증가되었음을 확인할 수 있습니다.
이제 이해가 좀 쉽게되시죠? ^^
하지만 TRUNCATE문의 단점도 있습니다.
DELETE문은 WHERE절을 이용하여 조건을 사용할 수 있지만 TRUNCATE는 조건을 사용할 수 없습니다.
그리고 DDL이기 때문에 사용권한 문제도 있습니다.(아래는 MSDN에 있는 사용권한 내용입니다.)
최소한 table_name에 대한 ALTER 권한이 필요합니다. TRUNCATE TABLE 권한은 테이블 소유자, sysadmin 고정 서버 역할 및 db_owner 및 db_ddladmin 고정 데이터베이스 역할의 기본 권한이며 위임할 수 없습니다. 하지만 저장 프로시저와 같은 모듈 내에 TRUNCATE TABLE 문을 통합한 뒤 EXECUTE AS 절을 사용하여 적절한 권한을 모듈에 허용할 수 있습니다. 자세한 내용은 EXECUTE AS를 사용하여 사용자 지정 권한 집합 만들기를 참조하십시오
TRUNCATE를 사용하기위한 제한 사항들도 있습니다.(아래는 MSDN에 있는 제한사항 내용입니다.)
다음과 같은 테이블에서는 TRUNCATE TABLE 문을 사용할 수 없습니다.
- FOREIGN KEY 제약 조건에 의해 참조됩니다. 자신을 참조하는 외래 키가 있는 테이블을 잘라낼 수 있습니다.
- 인덱싱된 뷰에 참여합니다.
- 트랜잭션 복제 또는 병합 복제에 의해 게시됩니다.
이런 특징을 한 개 이상 갖고 있는 테이블의 경우 DELETE 문을 대신 사용하십시오.
TRUNCATE TABLE은 개별 행 삭제를 기록하지 않기 때문에 트리거를 실행할 수 없습니다. 자세한 내용은 CREATE TRIGGER(Transact-SQL)를 참조하십시오.
어느게 좋다 나쁘다 이런문제가 아닙니다. 사용목적에 따라 적절하게 사용하시는게 최선이라고 생각합니다.
MSDN참조 경로 : (http://msdn.microsoft.com/ko-kr/library/ms177570.aspx)
목 차
1. 개요 6
1.1 목적 6
1.2 범위 6
2. SQL 가이드 라인 7
2.1 SQL TEXT 표준 7
2.1.1 SQL TEXT 7
2.1.2 FROM CLAUSE 8
2.1.3 WHERE CLAUSE 9
2.1.4 SELECT CLAUSE (SELECT LIST) 10
2.2 기타 SQL 구문 11
2.2.1 UPDATE문 11
2.2.2 DELETE문 11
2.2.3 INSERT문 11
2.3 데이터 타입 비교 12
2.3.1 CHAR 타입 12
2.3.2 VARCHAR2 타입 12
2.3.3 NUMBER 타입 12
2.3.4 DATE 타입 13
2.4 인덱스 선정 기준 14
2.4.1 인덱스 선정 기준 14
2.4.2 인덱스 컬럼 선정 기준 14
2.4.3 인덱스 활용 시 주의 사항 (인덱스가 사용되지 않는 경우) 14
2.5 PL/SQL 및 기타 함수 15
2.5.1 PL/SQL의 특징 및 장점 15
2.5.2 PL/SQL 사용 기준 및 유의사항 15
2.5.3 대용량 데이터 처리 기능 16
2.5.4 기타 함수의 사용 19
2.6 SQL TIP 22
2.7 기타 오라클 오브젝트 정책 23
3. 데이터 표준 24
3.1 DB 환경 구성 24
3.1.1 DB 사용자 24
3.1.2 테이블 업무 영역 분류 25
3.1.3 테이블스페이스 25
3.2 NAMING RULE 25
3.2.1 사용자 25
3.2.2 업무영역 26
3.2.3 테이블스페이스 26
3.2.4 테이블 26
3.2.5 임시 테이블 26
3.2.6 컬럼 명 27
3.2.7 주 키 (Primary Key) 27
3.2.8 외래 키 (Foreign Key) 27
3.2.9 인덱스 27
3.2.10 프로시저 28
3.2.11 Function 28
3.2.12 Package 28
1. 개요
본 문서는 @@@ 구축에 필요한 데이터베이스의 표준에 대한 지침을 분석하는 문서입니다.
1.1 목적
본 문서는 개발자들에게 SQL가이드라인을 제시하며 공통된 작성 규칙을 제공함으로써 시스템 성능의 향상 및 개발자들의 업무 수행 능력을 향상을 목적으로 하는 개발자를 위한 문서입니다.
1.2 범위
본 문서에서는 @@@의 SQL 가이드 및 표준에 대한 내용을 정리한 것이다.
본 문서의 구체적인 범위는 아래와 같다.
SQL 가이드
데이터 표준 지침
…..
2. SQL 가이드 라인
2.1 SQL TEXT 표준
2.1.1 SQL TEXT
1) SQL문중 table, column,변수는 소문자로 작성하고 그 이외의 내역은 대문자로 통일하여 작성한다.
2) /* TEST.JAVA */
SELECT aa
FROM table1
WHERE col1 = 'a' 로 SQL구문의 세로줄을 맞추어서 (왼쪽에 맞춘다)
BLOCK 단위로 쉽게 이해할 수 있도록 한다.(탭보다는 스페이스를 이용)
또한 column이나 변수도 KEYWORD 이후 왼쪽 정렬을 하여 맞춘다.
SELECT a
INTO hc_a
FROM test
WHERE aaa = 100;
3) Host 변수는 일반 COLUMN명과 구분하기 위해 아래와 같은 Prefix를 사용한다.
이때 컬럼명은 한글명과 매핑되는 영문명을 사용한다.
SELECT a.col1
변수 명
VARCHAR2 hv_컬럼명
CHAR hc_컬럼명
NUMBER hn_컬럼명
DATE hd_컬럼명
,b.col2
INTO ,hc_col1
,hn_col2
,hd_col3
FROM tab1 a
,tab2 b
WHERE a.col1 = b.col1 [그림 1,1 HOST 변수 예]
AND a.col1 = '1'
GROUP BY a.col1
,b.col2
ORDER BY a.col1
4) 지역변수는 소문자로 전역변수는 첫 글자를 대문자로 한다. (예hc_col1, Hc_col1)
5) SQL구문에 공백 라인이 없도록 작성하며 컬럼과 컬럼 사이,
테이블과 테이블 사이에는 하나의 개행(New Line)을 두어 구분한다. (긴 구문 제외)
SELECT a.col1
,col2
,col3
FROM tab1 a
,tab2 b
WHERE a.col1 = b.col1
6) SQL구문은 가로 최대 길이가 80컬럼 이하가 되도록 작성하여 SQL 튜닝시 또는 유지 보수를 할 때 쉽게 이해할 수 있도록 한다.
8) 긴 구문의 SQL 코딩이 필요하지 않을 경우 6번)을 준수하여 주고 부득이하게 구문이 길 경우에는 8번)의 최대 80라인을 준수하며 단어와 단어 사이에는 한 칸을 띄우고 COMMA(,) 다음에 한 칸을 띄운다
9) 연산자(+,-,*,/,||) 다음에 한 칸을 띄운다.
10) 비교연산자(=,!=,<,>,<=,>=,<>) 다음에 한 칸을 띄운다.
11) 조인의 연결고리가 되는 컬럼의 데이터 타입을 같게 한다.
12) OR절을 가급적 제한해서 사용한다.
13) WHERE 절에 가급적 부정형 조건보다는 긍정적 조건을 사용한다.(<>,NOT BETWEEN, NOT LIKE, NOT IN => =, BETWEEN, LIKE, IN)
14) 불필요한 NVL 함수는 사용하지 않도록 한다.
15) 결과값에 상관없이 OUTER JOIN을 사용하지 않도록 한다.
16) 개발시점에는 튜닝 이전까지는 기본 인덱스(Primary Key)만 유지한다.
17) 개발과정에서 업무 Logic 구현상 최대 일련번호를 구하여야 하는 경우에 한해서 INDEX_DESC 힌트의 사용을 고려하고 그 이외에는 개발과정 중에는 튜닝 이전까지 힌트 사용을 하지 않는 것을 원칙으로 한다.
18) SQL 튜닝의 편의를 위해서 모든 SQL문앞에 주석(REMARK)을 추가한다.
/* 프로그램 소스 ID, 작성자, 작성일자, 프로그램 내 SQL 일련번호 */
예) SELECT /* src1110 홍길동 2007.04.03 1 */ * FROM DUAL;
INSERT /* src1110 홍길동 2007.04.03 2 */ INTO TAB VALUES (1);
2.1.2 FROM CLAUSE
1) DRIVING 순서대로 TABLE을 기술한다.
- 쿼리상에서 기준이 되는 테이블을 좌측에 위치
- CHILD 테이블을 좌측에, PARENT테이블을 우측에 위치
- ROW수가 많은 테이블을 좌측에, ROW수가 적은 테이블을 우측에 위치
2) ALIAS 명칭은 최대한 간단히 a, b, c 등으로 설정하고 (최대 2자리 이니셜)
가장 먼저 DRIVING 되는 TABLE을 a로 설정하고 이후 순차적으로 기술하여 DRIVING 되려는 TABLE의 의도를 쉽게 이해할 수 있도록 한다.
한 SQL 문장에서 같은 ALIAS 명칭을 사용하지 않는다.
테이블이 하나일 경우에는 ALIAS를 지정하지 않는다.
SELECT col1
FROM tab
WHERE col1 = ‘0888’;
3) 하나의 라인에 하나의 TABLE을 나열한다.
4) INLINE VIEW가 있는 경우에는 다음과 같이 "(" 를 맞추어서 기술한다.
SELECT a.col1
,a.col2
,b.col3
,b.col4
FROM (SELECT col1
,col2
FROM tab2
WHERE col3 = '101') a
,tab2 b
WHERE a.col1 = b.col1
AND a.col3 = 'A1101';
(*) INLINE VIEW의 SQL 구문은 표준을 준수한다.
2.1.3 WHERE CLAUSE
1) 기술 요령
ㄱ) ALIAS 명을 기준으로 한 라인에 하나씩 조건절을 기술하고
다음 라인에는 AND부터 기술한다.
쉽게 읽고 이해할 수 있도록 최대한 컬럼을 맞추어서 기술한다.
WHERE a.col2 = b.col2
AND a.col3 = b.col3
AND a.col1 = '101';
ㄴ) 만약 SUB-QUERY가 있는 경우에는 다음과 같이 "(" 를 MAIN-QUERY의
컬럼에 맞춰서 기술한다.
WHERE a.col1 = (SELECT col1
FROM tab2
WHERE col2 = '101')
2) 기술 순서
ㄱ) 조인 문장을 먼저 기술한다. ( 조인되는 순서대로 기술한다. )
ㄴ) 조건 및 범위를 조인 다음에 기술한다.
( 먼저 처리되는 처리 범위부터 순서대로 기술한다. )
ㄷ) ORDER BY 나 GROUP BY 는 WHERE 조건이 아닌 별도 라인에 기술한다.
WHERE a.col2 = b.col2
AND a.col1 = '101‘
GROUP BY a.col2
ORDER BY a.col3
2.1.4 SELECT CLAUSE (SELECT LIST)
1) SELECT-LIST 라인은 다음과 같이 COLUMN명과 ALIAS명을 기술하고, 한 라인에 하나의 컬럼을 기술을 기술하며 세로줄을 맞추어 작성한다.
SELECT a.col1
,a.col2 + a.col3 col2
,b.col4
,b.col5
FROM tab2 a
,b
WHERE a.col2 = b.col2
AND a.col1 = '101'
ORDER BY a.col3
2) ALIAS의 지정은 COLUMN명과 상이한 경우에만 사용하며 “ COLUNM명 ALIAS명 ”으로 기술한다.
SELECT SUM (a.col1) + SUM (a.col2) tot_amt
3) 함수 사용으로 인해 기술 내용이 길어질 경우에는 “(”와 “)” 로 시작과 끝이 쉽게 이해되도록 하고 별도의 ALIAS를 지정한다.
SELECT a.col1
,DECODE (SUBSTR (a.col2
,1
,3
)
,'111', b.col5
,'112', c.col5
,d.col5
) col_sum
FROM tab2 a
,b
WHERE a.col2 = b.col2
AND a.col1 = '101'
ORDER BY a.col3;
4) HINT를 사용하지 않는다.
인덱스 구성이 완료되고 튜닝 시점에 힌트 사용을 허용한다.
5) NOT NULL, PK컬럼에 대해 NVL을 사용하는 등의 불필요한 함수를 사용하지 않도록 한다.
6) SELECT * 구문은 작성하지 않는다.
컬럼 추가, 삭제시 모델의 변경에 대한 대처를 하기 위하여 필요한 컬럼은 모두 기재하도록 한다.
SELECT * ( X : 허용안됨)
FROM TAB
2.2 기타 SQL 구문
2.2.1 UPDATE문
1) 변경 컬럼이 두개 이상일 경우는 ",” 로 나열하며 한 라인에 하나씩 기술한다.
/* AAA001 */
UPDATE tab1
SET col1 = '111'
,col2 = '222'
WHERE col3 = '101'
2) SUB-QUERY와 연결하여 처리될 경우에는 TABLE명에 ALIAS명을 기술하여 컬럼의
모호성(AMBIGOUS)이 발생하지 않도록 한다.
UPDATE tab1 a
SET a.col3 = (SELECT SUM (b.col3)
FROM tab2 b
WHERE a.col1 = b.col1
AND a.col2 = b.col2)
WHERE a.col3 = '101'
3) WHERE 조건 컬럼에 인덱스가 있는지 확인한다.
만약 없으면 TABLE FULL SCAN을 하므로 속도가 저하될 수 있다.
2.2.2 DELETE문
1) 다음과 같이 기술한다.
/* AAA001 */
DELETE FROM tab1
WHERE col1 = '101’
2) WHERE 절에 SUB QUERY도 가능하다.
2.2.3 INSERT문
1) 향후 컬럼 순서 변경이나 추가 시 유연성을 갖고자 INSERT되는 컬럼명을 필히 기술한다. 컬럼과 입력되는 값의 개수를 맞추어 가지런히 정렬한다.
/* AAA001 TEST */
INSERT INTO tab1
(col1
,col2
,col3
)
VALUES (‘101’
,’202’
,SYSDATE
);
잘못된 예)
INSERT INTO TAB1 VALUES (‘A’, 1,2,3);
2.3 데이터 타입 비교
2.3.1 CHAR 타입
1) 고정길이 문자 타입으로 최대 2000 Bytes 까지 입력 가능 (Oracle8 이상)
2) 모든 데이터가 고정길이를 가지는 경우
3) 모든 데이터가 일정한 길이 이상을 가지며 컬럼 길이가 짧은 경우 사용을 고려
4) 컬럼의 길이가 한자리인 경우
5) 가변길이로 지정할 경우 많은 체인(Chain)이 발생이 우려되는 경우 사용을 고려
6) 데이터 길이의 편차가 심한 경우 사용하면 저장공간 낭비와 불필요한 공백까지 네트워크를 타고 이동 등 수행속도가 저하될 수 있음
7) ROW INSERT 시에는 컬럼이 채워지지 않으나 곧 이어 반드시 데이터가 입력되는 경우 사용 고려. CHAR 타입을 사용하더라도 저장공간을 확보해 두려면 테이블 CREATE 시 DEFAULT CONSTRAINT를
‘ .‘ (BLANK)로 지정해 두어야 한다.
2.3.2 VARCHAR2 타입
1) 가변길이 문자 타입으로 최대 4000 Bytes 까지 입력 가능 (Oracle8 이상)
2) 데이터가 가변길이를 가지는 경우
3) 데이터 길이의 편차가 심한 경우
4) NULL로 입력되는 경우
5) 적절한 PCTFREE를 부여하지 않으면 체인(Chain) 발생 가능성이 높음
6) 체인을 감소하기 위해 저장공간을 확보해 두려면 테이블 CREATE 시 DEFAUTL
CONSTRAINT를 원하는 만큼의 ‘ ‘(BLANK)로 지정
7) 체인 감소를 위한 모니터링이나 Re-Org 등에 대한 비용이 CHAR TYPE의 사용보다 비용대비 효과가 크다고 볼 수 있다. (체인 현상 보다 공간 감소 및 성능에 VARCAHR2 TYPE이 효과적)
8) 전체 데이터 용량 감소 효과 지대
8) 가능한 CHAR 타입 보다 VARCHAR2 타입 사용
2.3.3 NUMBER 타입
1) NUMBER(p,s)에서 PRECISION 의 범위는 1 ~ 38, SCALE의 범위는 –84 ~127 까지이며, p 는 s 의 자리수를 포함한 전체 데이터의 길이이고 소수점이하의 값은 반올림되어 저장됨
2)연산이 필요한 컬럼에 사용
3) NUMBER 타입의 컬럼이 문자 값과 비교되면 문자를 숫자로 바꾸어 비교하므로 인덱스를 사용하지 않게 되므로 인덱스로 생성할 컬럼은 가능한 문자타입을 사용
4) NUMBER 타입으로 지정된 컬럼을 LIKE ‘char%’ 로 비교하면 인덱스를 사용할 수 없음 (내부적 변형이 발생)
5) 가변길이 이므로 충분하게 지정하여 사용한다. (Default 22 Byte)
6)기본키(PK)에 포함되는 일련번호는 NUMBER 타입 사용하되 LIKE로 사용되지 않을 경우에만 사용함
2.3.4 DATE 타입
1) YYYYMMDDHH24MISS 일시 [시분초까지 표현]
컬럼명 : INPUT_TIME
입력시 : SYSDATE로 입력한다.
è 컬럼의 변형을 하지 말아야 한다. TO_CHAR(~~,’YYYYMMDD’)
예 (잘못 사용된 경우).
SELECT aa
,bb
,cc
FROM test
WHERE TO_CHAR (aa, 'YYYYMMDD') BETWEEN '20050413‘
AND '20050413’
예 (표준)
SELECT aa
,bb
,cc
FROM test
WHERE aa >= TO_DATE ('20050413')
AND aa < TO_DATE ('20050413') + 1
아래는 위와 동일한 결과를 나타내는 SQL문장이지만 가급적 위 문장을 사용한다.
(1) WHERE AA BETWEEN TO_DATE('20050413')
AND TO_DATE('20050413') + 0.99999
(2) WHERE AA BETWEEN TO_DATE('20050413')
AND TO_DATE('20050413' || '235959','YYYYMMDDHH24MISS')
2) YYYYMMDD 일자 [일자만 표현]
컬럼명 : INPUT_DATE
입력시 : TO_CHAR(SYSDATE,’YYYYMMDD’)로 입력한다.
일자만 있는 타입에서는 아래 SQL이 가능하지만 통일된 SQL문장을 위하여 위와 같이 사용하도록 한다.
SELECT aa
FROM TEST
WHERE aa BETWEEN TO_DATE ('20050413') AND TO_DATE ('20050413')
3) TIMESTAMP 타입 사용
컬럼명 : REGIST_TIME, UPDATE_TIME
입력시 : SYSTIMESTAMP로 입력한다.
입력시
INSERT INTO test
VALUES (SYSTIMESTAMP
)
Select시
SELECT TO_CHAR (a, ' YYYYMMDDHH24MISSFF ')
FROM a
(1) WHERE REGIST_TIME >= TO_DATE('20050413')
AND REGIST_TIME < TO_DATE('20050413') + 1
(2) WHERE UPDATE_TIME = TO_TIMESTAMP(‘20060407150000123456’
, ‘YYYYMMDDHH24MISSFF’)
2.4 인덱스 선정 기준
2.4.1 인덱스 선정 기준
1) 6 블록 이상의 테이블에 적용 (6 블록이하는 연결고리만)
2) 컬럼의 분포도가 10~15% 이내인 경우 적용
3) 분포도가 범위 이내더라도 절대량이 많은 경우에는 단일 테이블 클러스터링 검토
4) 분포도가 범위 이상이더라도 부분범위처리를 목적으로 하는 경우에는 인덱스 적용
5) 인덱스만을 사용하여 요구를 해결하고자 하는 경우는 분포도가 나쁘더라도 적용할 수 있음 (손익분기점)
6) 손익분기점이란 분포도가 10~15%인 경우와 Full Scan 이 같은 경우 Full Scan 과 비교해서 낫다는 것이지 10~15%가 목표는 아님. 데이터가 아주 많은 경우 분포도가1%일지라도 Full Scan 이 더 나을 수 있다
2.4.2 인덱스 컬럼 선정 기준
1) 해당 테이블을 액세스하는 가능한 모든 액세스 형태를 수집
2) 대상 컬럼의 선정 및 분포도 조사
I. 액세스 유형에 자주 등장하는 컬럼
II. 인덱스의 첫번째 컬럼으로 지정해야 할 컬럼
III. 수행속도에 영향을 미칠 것으로 예상되는 컬럼
3) 반복 수행되는 액세스 경로(Critical access path)의 해결
I. 항상 ‘=’로 사용되는 컬럼이 여러 개 있다면 유일성(분포도)이 좋은 컬럼을 먼저 오도록 한다.
4) 클러스터링 검토
5) 매우 좋은 분포도를 가진 컬럼을 독립적인 인덱스로 생성
6) 인덱스 컬럼의 조합 및 순서의 결정
2.4.3 인덱스 활용 시 주의 사항 (인덱스가 사용되지 않는 경우)
1) 비교되기 전에 인덱스 컬럼의 내부적인 변형, 외부적인 변형이 일어나는 경우 -> 비교되는 상대 컬럼(혹은 상수)의 변형하여 인덱스를 사용하게 함
2) 부정형(NOT, <>)으로 조건을 기술한 경우
3) 긍정형으로 바꾸어 인덱스를 사용하게 한다.
4) 인덱스 컬럼이 NULL로 비교되는 경우
5) 컬럼의 값이 NULL 인 로우는 인덱스에 저장되지 않기 때문, 결합 인덱스의 첫번째 컬럼이 아닌 값을 NULL로 비교하는 경우에는 인덱스 사용
6) 옵티마이저가 필요에 따라 상기 적용원칙을 준수했음에도 불구하고 특정 인덱스의 사용을 취사 선택하는 경우
2.5 PL/SQL 및 기타 함수
2.5.1 PL/SQL의 특징 및 장점
1) 프로그래밍 언어 유형과 데이터베이스 유형이 동일하기 때문에 이들 사이에는 변환이 필요 없다.
언어와 데이터베이스 사이의 밀접한 결합에 대한 특성은 다음과 같다.
- 컴파일러가 언어의 변수에 대한 정의 없이 묵시적으로 레코드 유형을 처리
- 쿼리의 열기와 닫기 같은 것들을 자동으로 처리하므로 수행 불필요
- 데이터베이스 오브젝트 변경에 종속되지 않으므로 프로시저 관리에 신경 쓸 필요 없음 (JAVA등 AP는 데이터베이스 오브젝트 변경에 대해서 별도로 수정 작업 수행)
2) PL/SQL 작성은 모든 AP에서 호출하여 사용할 수 있다는 장점이 있다. (JAVA등의 Dynamic SQL 보다 재사용 성 우수)
3) 다른 AP와 다르게 Network I/O의 발생 부담이 적다
4) PL/SQL의 New Feature의 추가 기능에 의하여 부분범위 처리 및 Context Switch등의 획기적인 성능 개선 효과
5) Array Processing 효과 (8i이후 Bulk Collect, Forall 등)로 성능 효과 극대화
2.5.2 PL/SQL 사용 기준 및 유의사항
1) SQL로 처리할 수 있는 부분은 SQL로 처리를 하고 처리가 불가능(Logic이 필요한 경우) 한 부분에 대해서만 코딩 하라.
- JAVA와 같은 Application 프로그램에서의 Logic 처리 보다는 성능의 우월성이 있으나 PL/SQL의 사용은 SQL엔진과 PL/SQL엔진간의 PL/SQL BLOCK에 대한 Context Switch가 발생 (구문 해석을 SQL엔진과 PL/SQL엔진에서 별도로 처리하며 결과값에 대한 Return등에 대한 오버헤드 존재)
- SQL로 처리할 수 있는 경우에는 SQL로 처리하고 SQL로 처리할 수 없는 경우에만 PL/SQL을 사용하는
것을 목표로 한다.
2) 중복 LOOP등 지나치게 절차적인 Logic 처리를 삼가 한다. (단일 행 Fetch, 중첩된 LOOP문 사용 등 , Analytic Function등으로 유도)
3) 코드를 Module 방식으로 작성하라. (각 각의 Module 방식은 가독성을 높이고 구조적인 코딩을 가능하게 한다)
4) Package를 사용하라.
- Package의 사용은 중첩되는 프로시저 (프로시저가 다른 프로시저를 Call하여 사용하는 경우)나 오브젝트의 변경 시에 변경에 대한 영향을 최소화한다. (데이터 베이스 종속성 체인 제거 효과)
- 유사한 기능을 업무단위로 함께 관리하기가 용이하다.
- 세션 지속형 변수를 지원한다.
5) 정적 SQL을 사용할 수 있다면 정적 SQL을 사용하라
6) 대용량 데이터 처리에 대한 효과가 클 때에는 대량처리(Bulk Insert, Bulk Collect, Forall문 등)를 사용하라. 단 메모리의 사용 부담을 고려하여 적은 데이터의 처리시에는 사용을 자제하고 일반 단일 행 처리 PL/SQL을 사용하라. 대량처리 기능은 Context Switch(문맥전환을)를 줄여 주는 조인 효과가 있다.
7) 공통으로 사용하는 부분은 PL/SQL(STORED PROCEDURE/ FUNCTION)을 활용하여 Parsing을 줄여서 메모리의 성능을 최대화 한다.
8) 단일 SQL문으로 처리되는 경우에는 SQL문으로 처리한다.
9) 패키지의 활용을 통해서 프로시저의 종속성을 제거한다. (하위 오브젝트가 INVALID라도 VALID 상태 유지)
10) PL/SQL의 CURSOR 사용시 OPEN과 CLOSE는 반드시 일치 되어야 한다. (OPEN_CURSOR 초과시
신규 프로시저 OPEN 불가)
11) EXCEPTION 처리에 대해서 발생 가능한 모든 EXCEPTION에 대한 정의를 하여야 한다.
12) COMMIT은 가급적 트랜잭션이 완료된 이후에 수행한다.
13) PL/SQL 작성 시 LOOP안에서 CURSOR OPEN/CLOSE를 반복하지 않도록 한다. 불가피하게 LOOP 안에서 CUSRO OPEN를 반복적으로 수행하더라도 해당 CURSOR의 CLOSE는 LOOP 밖에서 한번만 수행되게 함으로써 OPEN시의 반복적인 PARSING을 줄일 수 있다. (PL/SQL 유의 사항 예제)
예) LOOP안에 LOOP를 반복적으로 사용하는 것보다 CURSOR 선언으로 FETCH만 LOOP를 사용할 수 있도록 하는 예
14) %TYPE, %ROWTYPE, REF CURSOR등을 사용하여 테이블의 데이터 타입의 변경에 대비한다. (PL/SQL 블록에서 지정 시 타입이 불일치 하는 경우 발생 가능성 존재)
LOOP
FETCH c1 INTO :v1 :v2
LOOP
FETCH c2 INTO :v21 :v22
LOOP
SELECT xx
FROM tab3 <-------- (1)
WHERE col1 = :v21
AND col2 = :v22;
. . . .
END LOOP;
END LOOP;
END LOOP;
LOOP 내에 (1)처럼 SELECT 문장을 반복 수행하는 것보다는 아래와 같이 커서를 선언하여 사용한다.
DECLARE
CURSOR C1 IS
SELECT .,
.,
FROM tab1 a,
tab2 b,
tab3 c
WHERE a.col1 = b.col2
BEGIN
OPEN c1
LOOP
FETCH c1 INTO :xx
END LOOP;
COMMIT;
END;
2.5.3 대용량 데이터 처리 기능 (PL/SQL New Feature)
8i이전 버전에서 PL/SQL의 기능이 단일 행 처리 (Cursor, Fetch)에 대한 수행만 가능할 때는 대량의 데이터를 처리
하는 것은 성능 악화의 결정적인 요소였던 적이 있었으며, 이에 대한 해결책으로 SQL의 처리로 유도하는 것이 해결책인 적이
있었다.
하지만 PL/SQL에서 대용량 처리를 위한 새로운 기능들이 추가 되었으며 이를 통해서 SQL의 처리와 같은
효과를 보게 되었다.
1) PL/SQL의 성능 저하 요인
PL/SQL 블록에서 SQL문은 SQL엔진으로 넘겨진 후 처리 결과를 다시 PL/SQL 엔진으로 넘겨준다. 이 과정에서 문맥전환 (CONTEXT SWITCH)이 발생한다. 이의 오버헤드는 자원 낭비를 가져온다. 이 경우 BULK BIND으로 변환하여 한 번의 처리에 많은 ROWS를 처리한다면 이런 오버헤드를 최소화 할 수 있다.
따라서 FORALL문을 이용하여 문맥 전환을 줄인다. 이를 통해서 BULK DML (UPDATE, DELETE, INSERT)를 처리를 하면 CONTEXT SWITCH를 줄일 수 있다.
또 한 PL/SQL블록의 성능저하의 주 원인 이였던 FETCH 기능도 BULK CONTEXT를 이용하여 한번에 처리를 하여 CONTEXT SWITCH를 줄여줄 수 있다. 이는 테이블과 테이블의 조인 처리와 같은 효과가 있으며 이런 기능들을 적절하게 활용하면 성능 개선 효과가 크다고 할 수 있다.
2) Bulk Collect
예전 PL/SQL의 단점 중의 하나였던 결과값에 대한 INTO 절의 처리가 단일 행에 대한 처리에 한한다는 한계가 있었으며 이는 PL/SQL의 성능 저하의 요인 이였던 PL/SQL의 Context Switch를 가중시키는 결과가 되어 성능저하의 원인 이였다. 이에 대한 INTO절의 처리를 단일 행이 아닌 배열(Arrary)기능의 BULK Collect라는 기능을 사용하여 INTO문에 대한 배열처리를 가능하게 하였으며 이에 대한 성능 개선 효과는 탁월하다.
예) BULK COLLECT 문 예제
bulk_collect_bind.sql
DECLARE
TYPE Numlist IS TABLE OF emp.empno%TYPE;
Id Numlist;
BEGIN
SELECT empno
BULK COLLECT INTO Id
FROM emp
WHERE sal < 2000
FORALL i IN Id.FIRST ..Id.LAST
UPDATE emp SET sal= 1.1*sal
Where mgr(Id(i);
END;
Numlist라는 type을 empno type으로 선언하고 Numlist를 이용하여 ID라는 변수를 선언하여 Bulk Collect문으로 id 변수에 배열 처리 (SQL구문에서 BULK COLLECT INTO 절에서 사용)
예) BULK COLLECT의 다른 예제
DECLARE
CURSOR all_depts IS
SELECT deptno, dname
FROM dept
ORDER BY dname;
TYPE dept_id IS TABLE OF dept.deptno%TYPE;
TYPE dept_name IS TABLE OF dept.dname%TYPE;
dept_ids dept_id;
dept_names dept_name;
inx1 PLS_INTEGER;
v_InsertStmt VARCHAR2(2000);
BEGIN
OPEN all_depts;
FETCH all_depts BULK COLLECT INTO dept_ids, dept_names;
CLOSE all_depts;
CURSOR문을 이용하여 데이터를 처리하고 테이블의 데이터 타입을 이용하여 TYPE선언을 한 후에 그 TYPE으로 변수를
선언하고 정의된 CURSOR를 열고 선언된 변수에 BULK COLLECT INTO를 이용하여 FETCH작업의 대량 데이터 처리
예 제와 같이 Bulk Collect는 데이터 타입을 지정하고 지정된 데이터 타입으로 변수를 선언하고 그 선언된 변수에 데이터를 Array 처리를 하는 것을 의미하며, 8i이전 버전에서 SELECT INTO 절, FETCH INTO 절에서 단일 행에 대한 처리의 한계를 극복하여 CONTEXT SWITCH문을 줄여서 성능 향상 효과가 있다.
3) Forall
예 전에 FOR문을 이용하여 LOOP를 순환 시키는 형태의 PL/SQL도 Context Switch를 유발하는 유형인데 이에 대해서는 Forall이라는 세 기능을 이용하면 FOR LOOP문 없이 처리가 가능하다. (For Loop문을 한번에 처리하므로 PL/SQL블록의 FOR문을 다시 수행하여 SQL엔진과 Context Switch를 줄여 주어서 한번의 처리로 테이블 조인과 같은 효과를 갖는다)
이는 테이블간의 조인 처리 효과를 갖는다.
/** Load한 데이터의 변형 **/
DECLARE
TYPE Numlist IS TABLE OF emp.empno%TYPE;
Id Numlist;
BEGIN
SELECT empno BULK COLLECT INTO Id
FROM emp
WHERE sal < 2000;
FORALL i IN Id.FIRST..Id.LAST
UPDATE emp SET Sal = 1.1 * Sal
WHERE mgr = Id(i);
END;
위의 구문을 비교해 보면 FORALL문을 이용해서 FOR LOOP문의 처리를 한번에 수행한 예제이며, emp.empno의 데이터
타입을 지정하고 그 데이터 타입으로 변수를 선언하고 선언된 변수의 Array의 첫 번째 row부터 마지막 row까지 FORALL문을
이용하여 한번에 UPDATE문을 처리한다. (테이블 조인 효과, 여러 번의 FOR LOOP을 대체하였다)
4) REF CURSOR
데이터를 CLIENT에 반환하는 것은 REF CURSOR를 이용하면 효율적이다.
REF CURSOR는 PL/SQL로 반환 집합만 정의하면 쉽게 사용할 수 있으며 ARRY SIZE를 적절하게 설정할 수 있으며, 또한
ARRAY SIZE 설정에 따라 데이터 처리에 대한 대기 없이 ARRAY SIZE에 의해 즉사 데이터 값을 반환 받을 수 있는 이점이
있다 (Partial Range Scan 효과)
또한 NETWORK I/O의 감소 효과도 있다. (여러 행의 SQL 대신 한줄의 PROCEDURE만 호출하면 된다)
예) REF CURSOR의 예제
variable a refcursor
variable b refcursor
variable c refcursor
begin
open :a for select empno form emp q1 where ename = 'blake';
open :b for select empno form emp q1 where ename = 'smith';
open :c for select empno form emp q1 where ename = 'james';
end;
예) REF CURSOR의 프로시저 활용 예제
CREATE OR REPLACE PACKAGE CURSOR_PKG AS
TYPE T_CURSOR IS REF CURSOR;
PROCEDURE OPEN_ONE_CURSOR (N_EMPNO IN NUMBER, IO_CURSOR IN OUT T_CURSOR);
PROCEDURE OPEN_TWO_CURSORS (EMPCURSOR OUT T_CURSOR, DEPTCURSOR OUT T_CURSOR);
END CURSPKG;
CREATE OR REPLACE PACKAGE BODY CURSOR_PKG AS
PROCEDURE OPEN_ONE_CURSOR (N_EMPNO IN NUMBER, IO_CURSOR IN OUT T_CURSOR)
IS
V_CURSOR T_CURSOR;
BEGIN
IF N_EMPNO <> 0
THEN
OPEN V_CURSOR FOR
SELECT EMP.EMPNO, EMP.ENAME, DEPT.DEPTNO, DEPT.DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO
AND EMP.EMPNO = N_EMPNO;
ELSE
OPEN V_CURSOR FOR
SELECT EMP.EMPNO, EMP.ENAME, DEPT.DEPTNO, DEPT.DNAME
FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO;
END IF;
IO_CURSOR := V_CURSOR;
END OPEN_ONE_CURSOR;
PROCEDURE OPEN_TWO_CURSORS (EMPCURSOR OUT T_CURSOR, DEPTCURSOR OUT T_CURSOR)
IS
V_CURSOR1 T_CURSOR;
V_CURSOR2 T_CURSOR;
BEGIN
OPEN V_CURSOR1 FOR SELECT * FROM EMP;
OPEN V_CURSOR2 FOR SELECT * FROM DEPT;
EMPCURSOR := V_CURSOR1;
DEPTCURSOR := V_CURSOR2;
END OPEN_TWO_CURSORS;
END CURSPKG;
/
REF CURSOR 로 T_CURSOR TYPE을 선언하고 CURSOR_PKG, OPEN_TWO_CURSORS 프로시저에서 CUSROR
타입을 지정하여 변수 V_CURSOR를 지정하여 REF CURSOR를 사용하도록 하여 V_CURSOR를 OPEN하여 SQL을 실행
하고 실행된 결과를 다시 프로시저에 결과값을 OUT (IO_CURSOR ARGUMENT, T_CURSOR TYPE지정으로 REF
CURSOR TYPE이므로 ARRAY로 처리 가능)
2.5.4 기타 함수의 사용
1) 복잡한 로직으로 수행되는 SQL은 Analytic Function을 활용하여 Logic을 간단하게 처리한다.
아래의 결과의 값은 같지만 처리 비용은 많은 차이가 있으며 데이터의 크기가 커질수록 그 차이는 비례한다.
예) 월별 매출금액과 매출누계를 구하는 예문
SELECT a.월, a.매출금액,
SUM(b.매출금액) AS 매출누계
FROM TEST1 a, TEST1 b
WHERE a.월 >= b.월
GROUP BY a.월, a.매출금액;
Analytic Fuction 변환 예문
SELECT 월, 매출금액,
SUM(매출금액) OVER (PARTITION BY a.월) 매출누계
FROM TEST1 a;
2) DECODE나 CASE문의 적절한 사용은 바람직하지만 과도한 사용은 자제한다.
특히 OR문의 경우를 DECODE문을 이용하여 효율적으로 처리할 수 있는 경우가 있으므로 적절하게 사용한다면 효과적일 수
있다.
OR문을 UNION ALL로 처리할 수 있으며 UNION ALL문을 DECODE문으로 처리할 수 있다.
3) SCALAR QUERY의 활용은 데이터의 범위를 줄여 주고 성능상의 이점이 있으므로 적극적으로 활용하는
좋으나 다음과 같은 경우에는 절대 SCALAR QUERY의 사용을 자제한다.
I. GROUP BY 함수에 의하여 GROUP 함수가 사용되는 경우 (MIN,MAX)
II. SCALAR QUERY내의 데이터 건수가 많은 경우
III. MAIN QUERY의 데이터 건수가 어느 정도 이상일 경우
이 세 가지 (특히 I,II)를 만족하는 경우에는 MAIN QUERY의 데이터가 범위를 줄여 주더라도 SCALAR QUERY 자체가 효과적이지 못하며 해당 GROUP BY 처리 (즉 전체 처리를 MAIN QUERY의 데이터 건수 만큼 처리가 되어서 역효과 발생)
4) MERGE문을 이용하여 UPDATE, INSERT 구문을 효율적으로 처리한다.
(PL/SQL에서 데이터가 있는지 COUNT하여 처리 여부를 결정할 필요가 없으므로 성능 향상 효과가 있다)
예) MERGE 문
merge into bonus D
using (select id,salary from emp) S
on (D.id = S.id)
when matched
then update
set D.bonus=D.bonus + S.salary*0.01
when not matched
then insert(D.id, D.bonus)
values(S.id,S.salary*0.01);
5) SQL 처리시에 많은 부분 중복되는 처리를 하여야 하는 경우가 발생하는데 이에 대한 처리는 기존에는 IN-LINE-VIEW나 VIEW를 생성하여 처리하거나 임시적인 TEMP 테이블을 생성하여 처리하였는데 이를 대신하여 편하게 사용할 수 있는 WITH문을 사용한다.
I. SQL구문 어디서든 지정하면 쉽게 사용할 수 있다.
II. SCALAR QUERY에서 중첩 처리를 가능하게 한다.
III. IN-LINE-VIEW와 다르게 한번 지정하면 반복 사용 가능하다.
WITH V_TARGET
AS(SELECT * FROM T_V_TARGET)
SELECT * FROM V_TARGET
UNION ALL
SELECT * FROM V_TARGET
WHERE ROWNUM = 1;
2.6 SQL TIP
1) 전체자료의 15% 미만인 경우 인덱스를 사용하도록 유도한다.
예)통계 및 현황을 제외하고는 인덱스 사용하도록 한다.
2) WHERE절에서 컬럼을 변형시키지 말아야 한다. 컬럼의 변형이 일어난 경우 인덱스를 사용할 수 없다.(단 Function Based Index인 경우는 제외)
3) 가능하면 Subquery 혹은 Join을 사용하여 하나의 SQL로 작성하도록 한다
4) 조인 후 GROUP BY를 수행하는 것 보다는 GROUP BY를 수행한 후 조인을 실시한다.
5) 결합인덱스와 PK의 순서를 지켜가면서 SQL을 작성하도록 한다. (인덱스 LEADING부문이 가능하면 포함되게 작성)
6) Execution Plan 확인 후 ‘FULL SCAN’이 나타나면 인덱스의 사용 여부와 적절성을 검토하여야 하며, 적절성의 판단이 안 되면 DBA와 상의한다.
(단 FULL SCAN, HASH JOIN이 발생되었다고 모두 잘못된 것은 아니다.)
7) SQL작성 후 PLAN을 항상 확인해 보는 습관을 갖도록 한다.
8) UNION 보다는 UNION ALL을 사용하도록 한다.
9) 가급적이면 SQL상에서 ORDER BY를 사용하지 않는다. Order by를 사용하여야 한다면 인덱스 생성이 필요한지 검토한다 (특히 대용량 테이블인 경우)
10) INSERT, UPDATE, DELETE를 실행후에는 즉시 COMMIT 이나 ROLLBACK을 실행시켜서LOCK을 유발시키지 않도록 한다.
11) 프로그램상에서 DISTINCT 구문의 사용은 자제한다.
12) DML(Insert,Update,Delete)문 처리 후 항상 ROW 컬럼을 확인한다.
13) 컬럼의 변형이 일어나지 않도록 컬럼TYPE에 맞는 형태로 자료를 입력한다.
예) WHERE COL_VAR2 = 123 è WHERE TO_NUMBER(COL_VAR2) = 123
묵시적 변형이 일어난다.
묵시적 변형 우선순위 1) NUMBER > CHAR,VARCHAR2
묵시적 변형 우선순위 2) DATE > CHAR, VARCHAR2
14) SQL구문의 연관성과 업무 Logic을 잘 파악한다. (특히 Subquery에서 EXISTS, IN, NOT IN, NOT EXISTS)
의 특성을 고려하여 적절한 Logic을 구현한다. 가급적이면 긍정문인 IN, EXISTS로 유도한다.
15) REMARK는 반드시 달아 주는 습관이 필요하다. (개발보
2.7 기타 오라클 오브젝트 정책
1) 오라클 함수 (FUNCTION)
- 공통코드명, 품목명, 업체명등 대량의 조인을 회피하기 위하여 사용한다.
- 프로그램에서 처리해야 될 공통 모듈은 Application 프로그램을 이용한다. (계산식)
2) 오라클 프로시져
- 업무와 무관한 일반적인 로직 처리를 위한 프로시져는 사용하지 않는다. (단순 INSERT, UPDATE, DELETE)
- 배치 혹은 대량의 데이터 처리시에 프로시져를 사용하도록 한다.
3) 뷰
- 뷰 대신에 인라인 뷰를 사용하도록 한다.
- 반복적으로 사용되는 SQL이나, 복잡한 SQL을 단순화 시키고자 할 때만 사용한다.
- WITH문으로 대체가 가능한지 고려하여 잘 활용하도록 한다.
4) 시퀀스
- 시퀀스는 성능의 문제나 LOCK의 문제 소지가 있는 곳에서만 사용한다
5) 트리거
- 트리거의 사용은 가급적 사용하지 않는다.
- 여러 테이블의 동시적인 DML작업은 Application 프로그램에서 제어를 하는 것을 원칙으로 한다.
6) 인덱스
- PK인덱스의 순서는 매우 중요하며, 개발 시 필히 염두에 두어야 한다
- Foreign Key(FK)에 대한 인덱스는 자동으로 생성하지 않는다. 프로그래밍시 포린키 인덱스가 필요하다면 추후에 추가하도록 한다.
7) 제약사항
- 포린키(FK) 설정시 제약사항은 물리적으로 반영하도록 한다.(데이터 무결성)
(자식테이블 입력시 부모가 항상 존재하여야 한다)
- 부모-자식간의 삭제 로직은 프로그램에서 직접 제어 하도록 한다
- 컬럼의 Validation 체크는 프로그램에서 제어함을 원칙으로 하되, 확정적인 값에 대해서는 테이블 컬럼에서 valid check를 지원하도록 한다.
- 필수적으로 데이터가 입력되어야 하는 컬럼은 NOT NULL을 지정하고, 프로그램상에서 가능한 NVL()를 사용하지 않도록 한다.
3. 데이터 표준
3.1 DB 환경 구성
3.1.1 DB 사용자
t-MALL DB 계정은 상품, 회원, 거래, 마케팅 등 여러 업무 영역을 하나로 공유할 수 있는 사용자 계정이 필요하며 이에 대해서는 전체의 의미를 파악할 수 있도록 @@@이라는 사용자 계정을 생성한다.
테이블 등에서는 업무 영역 분류를 TM이리고 한다. (이후 추가되는 업무 영역과 구분하기 위함)
계정 계정명 (영문) 설명
@@@ 계정 @@@ @@@의 전체 업무를 하나로 가져 가야 한다는 업무 분석에 따라서 공통 계정 생성
입력, 갱신, 삭제등의 DML 처리
@@@ 관리자 계정 TADMIN @@@의 모든 테이블 생성 및 DROP 권한을 소유한 관리자 계정
@@@ 계정에는 DML 처리 외
테이블의 DDL에 대한 권한은
관리자 계정인 TADMIN에서 수행
3.1.2 테이블 업무 영역 분류
DB 사용자 계정의 업무 영역 분류는 @@@ 공통 계정으로 구성하고 이에 대해서는 약어 명으로 TM이라고
분류한다.
업무 영역 영문명 약어 설명
거래 TRADE TR 거래 업무 영역
마케팅 MARKETING MT 마케팅 업무 영역
상품 PRODUCT PD 상품 업무 영역
커뮤니티 COMMUNITY CM 커뮤니티 업무 영역
회원 MEMBER MB 회원 업무 영역
정산 STALLEMENT ST 정산 업무 영역
TNS TNS TNS TNS 업무 영역
통계 STATISTICS ST 통계 업무 영역
3.1.3 테이블스페이스
@@@ 테이블스페이스는 상품,회원,거래,마케팅 등의 업무를 공통으로 처리할 테이블스페이스와 각 각의 테이블에 대한 파티션 정책에 따른 테이블스페이스를 사용한다.
테이블스페이스 명 구분 테이블스페이스 용도
TSD_@@@ @@@의 공통 데이터 전체 업무처리를 위한 Tablespace
(단 , 코드 성격의 테이블과 대용량
테이블은 제외)
TSI_@@@ @@@의 공통 데이터 인덱스 @@@ 데이터의 인덱스용 테이블스페이스
TSD_TCODE @@@의 코드 성격 테이블 @@@의 코드 성격 테이블스페이스 (DML 데이터와 코드 성격 테이블 분리)
TSI-TCODE @@@ 코드 성격 테이블 인덱스 @@@의 코드 성격 데이터에 대한 인덱스용 테이블스페이스
UNDOTBS1 UNDO 테이블스페이스 UNDO 테이블스페이스
TS_TEMP USER용 Temporary Tablespace 가공 및 Sort를 위해서 할당되는
User용 Temp 테이블스페이스
업무용도에 따라서 통계 업무 및
OLTP 용 TEMP 분리 (성능 측면)
관리 및 공간의 효율성 측면에서는
단일 테이블스페이스 권장
3.2 Naming Rule
3.2.1 사용자
• 사용자는 사용자명을 잘 표현할 수 있는 의미 있는 단어(또는 약어)를 사용한다.
• 사용자는 가급적 1개의 단어(또는 약어)를 사용한다.
• 사용자명은 가급적이면 최대 8자를 넘기지 않도록 한다.
• 사용자명은 테이블스페이스 및 테이블 분류어와 연관이 있는 것을 원칙으로 한다.
예) 상품 : PROD, 마켓 : MARKET, 고객 : CUST
3.2.2 업무영역
업무영역 영문명 약어명
거래 TRADE TR
마케팅 MARKETING MT
상품 PRODUCT PD
커뮤니티 COMMUNITY CM
회원 MEMBER MB
정산 STALLEMENT ST
TNS TNS TNS
통계 STATISTICS ST
3.2.3 테이블스페이스
• 테이블스페이스는 접두사 + ‘_’ 테이블스페이스명 으로 사용한다.
• 테이블스페이스명의 접두사는 ‘TSD_’,’TSI_’로 시작하여야 한다.
• ‘TSD_’는 테이블용 테이블스페이스를 ‘TSI_’는 인덱스용 테이블스페이스를 나타낸다.
• 해당 테이블스페이스 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 30 자를 넘지 않도록 지정한다.
• 테이블스페이스명은 대문자로 표기한다.
• 가급적이면 사용자명을 기준으로 테이블스페이스명을 정하도록 한다.
예) 공통 테이블스페이스 : TSD_COMM
3.2.4 테이블
• 테이블명은 접두사 + ‘_’ + 업무 영역 분류 ‘_’ + 단어 + 단어 형태로 사용한다.
• 테이블명의 접두사는 ‘TB_’를 사용한다.
• VIEW인 경우에는 접미사 ‘_V’를 사용한다.
• 분류는 사용자별 또는 주제별로 적절한 단어를 사용한다.
• 업무 영역 분류 는 의미의 중복이 없는한 가급적 2자 이내의 약어를 사용한다.
• 테이블명은 논리적 의미를 갖는 영문 단어를 이용하여 정의하며, 대문자로 표기 한다.
• 해당 테이블 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 26자를 넘지 않도록 지정한다.
예) 회원정보 마스터 : TB_MB_INFO_MST (MB는 MEMBER의 약어, 회원 업무 분류어 )
상품 View : TB_PD_INFO_MST_V (PD는 PRODUCT의 약어, 상품 업무 분류어 )
3.2.5 임시 테이블
• 테이블명은 [접두사] + ‘_’ + [업무 영역 분류] ‘_’ + 테이블 + 접미사 형태로 사용한다.
• 테이블명의 접미사는 ‘_TMP’를 사용한다.
• 모든 것은 테이블과 동일하며 가급적이면 접두사와 분류의 형식을 지킨다.
• 테이블명은 논리적 의미를 갖는 영문 단어를 이용하여 정의하며, 대문자로 표기 한다.
• 최대 30자를 넘지 않도록 지정한다.
예) 회원정보 마스터 임시 테이블 : TB_MB_INFO_MST_TMP
3.2.6 컬럼 명
• 컬럼명을 잘 표현할 수 있는 단어 또는 약어를 사용한다.
• 논리적 의미를 갖는 영문 단어를 이용하여 정의하며, 컬럼명 모두를 대문자로 한다.
• 컬럼명은 1개 이상의 단어로 구성하며 단어와 단어 사이에는 ‘_’를 사용한다.
• 단어 + ‘_’ + [단어] 형태로 사용한다.
예) ID번호 : IDNO, 등록일자 : RG_DT
3.2.7 주 키 (Primary Key)
• 주 키는 PK + ‘-‘ + 테이블명 로 정의한다.
• 주 키는 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 마스터 : TB_CT_INFO_MST
Primary Key : PK_CT_INFO_MST
3.2.8 외래 키 (Foreign Key)
• 외래 키는 FK + ‘-‘ + 테이블명 로 정의한다.
• 외래 키는 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 마스터 : TB_CT_INFO_MST
Foreign Key : FK_TB_CT_INFO_MST
3.2.9 인덱스
• 인덱스는 IX + ‘일련번호’ + ‘_’ + 테이블 명으로 한다.
• 인덱스는 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 마스터 : TB_CT_INFO_MST
인덱스 : IX1_ CT_INFO_MST, IX2_ TB_CT_INFO_MST
3.2.10 프로시저
• 프로시저명은 접두사 + ‘_’ + 업무 영역 분류 + ‘_’ + 프로시저명 형태로 사용한다.
• 프로시저명의 접두사는 ‘SP_’를 사용한다.
• 업무 영역 분류는 사용자 계정의 약어를 사용한다,
• 프로시저명은 의미를 갖는 영문 단어를 이용하여 정의하며, 대문자로 표기 한다.
• 같은 프로그램 내에서 같은 의미로 프로시저명을 부여하고 싶다면 세 자리 수 일련번호 사용
• 가급적이면 같은 프로그램 내에서도 처리 루틴에 대한 의미 있는 이름을 사용한다.
• 해당 프로시저 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 30자를 넘지 않도록 사용한다.
예) 회원정보 입력 처리 : SP_MB_INFO_MST_INS
상품 판매 집계 처리 : SP_PD_SALE_RESULT_001, SP_PD_SALE_RESULT_002
SP_MT_SALE_RESULT_TMP, SP_MT_SALE_RESULT_SUM
3.2.11 Function
• Function 접두사 + ‘_’ + 업무 영역 분류 + ‘-‘ + 프로시저명 형태로 사용한다.
• 테이블명의 접두사는 ‘FN_’를 사용한다.
• 모든 것은 프로시저와 동일하다.
예) 회원 최종 접속일자 호출 : FN_MB_LT_CONN_DT
3.2.12 Package
• 패키지 명은 접두사 + ‘_’ + 업무 영역 분류 + ‘_’ + 패키지 명 형태로 사용한다.
• 패키지명의 접두사는 ‘PKG_’를 사용한다.
• 분류는 사용자 계정의 약어를 사용한다,
• 해당 패키지 명을 잘 표현할 수 있는 단어를 사용한다.
• 최대 30자를 넘지 않도록 사용한다.
예) 회원 접속 Package : PKG_MB_CONN
[출처] [SQL] SQL 작성을 위한 표준 지침 (사이버 비즈니스 크로스) |작성자 개발팀장
PURPOSE
WHERE조건의 동적구성에 따른 OR 또는 UNION ALL 활용(실행계획분리) 방안 이해
SCOPE & APPLICATION
실무에서는 프로그램 변수 값에 따라서 SQL WHERE 조건을 달리 가지고 가는 경우를 흔히 볼 수 있다. 예를 들어,
if (sw = 0) strSQL = “SELECT EMPNAME, SAL FROM EMP WHERE SAL > 2000000
else strSQL = “SELECT EMPNAME, SAL FROM EMP WHERE SAL > 2000000 AND DEPTNO = 1
와 같이 sw 값에 따라 SQL이 동적으로 구성되는 경우이다. 이러한 프로그램 방식은 dynamic SQL을 이용하는 방식으로서 변수 값에 따라 최적의 SQL을 만들어 낼 수 있는 장점이 있는 반면, 변수 값이 바뀜에 따라서 계속적인 SQL 파싱이 일어나 메모리 overhead가 많을 뿐 아니라 수행속도도 떨어진다는 것이다.
그래서, 본 topic에서는 OR이나 UNION ALL을 이용하여 dynamic SQL의 장점을 취하면서 단점을 보완할 수 있는 방법을 실무예제를 통해서 알아본다.
KEY IDEA
논리합연산자, OR, UNION ALL, 실행계획분리, dynamic SQL
SUPPOSITION
다음은 모 통신회사에서 고객에 대한 개통 회선정보를 보고자 하는 perl 프로그램의 일부이다.
if($link eq '0') { $query_link = "";
} else { $query_link = "AND publlink=$link"; }
………
$query1 = "
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,lineband
FROM publ,line
WHERE publnumb > 1000 $query_link
AND publnumb=linenumb AND to_char(linelast,'yyyymm')=?";
$cursor1 = $dbh->prepare("$query1");
$cursor1->execute;
- 인덱스 : PUBL_PK = publnumb, LINE_PK = linenumb+lineused+lineband
- publlink : 회선지역을 나타내는 코드성 컬럼
위 프로그램에서는 변수 $link 값에 따라서 SQL 구성이 달라진다. 즉, dynamic SQL을 사용한다. 이것을 static SQL로 고쳐서 parsing overhead도 줄이면서 수행속도도 보장 받을 수 있는 방안은 무엇인가?
DESCRIPTION
위 SQL의 내용을 살펴보면, $link 값이 0이면 “AND publlink=$link” 조건을 체크하지 말고, 0가 아니면 “AND publlink=$link” 조건을 체크하여 질의결과를 구하라는 의미의 dynamic SQL이다. 이것을 static SQL로 바꾸기 위한 방법은 대체로 3가지 정도의 방법이 있다.
1. OR 이용
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND (? = 0 OR (? != 0 AND publlink = ?))
2. UNION ALL 이용
SELECT *
FROM ( SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND ? = 0
UNION ALL
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,linebd
FROM publ,line
WHERE publnumb > 1000
AND publnumb = linenumb
AND to_char(linelast,'yyyymm')=?
AND ? != 0 AND publlink = ? )
3. DECODE() 함수 이용
SELECT publnumb,to_char(linelast,'yyyy.mm.dd'),linehyta,lineband
FROM publ,line
WHERE publnumb > 1000 AND nvl(publlink,0) = decode(?,0,nvl(publlink,0),?)
AND publnumb = linenumb AND to_char(linelast,'yyyymm') = ?
이 3가지 방법 중 어떤 방법을 선택하느냐?에 있어서 반드시 고려해야 할 사항이 있다. 그것은 dynamic WHERE 조건이 주관조건(driving condition)이 되느냐의 여부이다. 위 SQL에서는 dynamic WHERE 조건을 구성하는 컬럼인 publlink가 분포도가 안 좋은 코드성 컬럼이기 때문에 publ 테이블의 PK인 publnumb의 조건이나 line 테이블의 linelast의 조건이 주관조건이 되고 dynamic WHERE 조건은 체크조건으로 활용될 것이다. 그러므로, 1,2,3 중 어떤 방법을 이용하더라도 수행속도에 큰 차이는 없다.
그러나, publlink가 분포도가 좋은 컬럼으로 인덱스가 잡혀 있어 주관조건으로 사용된다면 1번과 3번 방법은 사용하지 않는 것이 좋다. 1번(OR이용) 방법의 경우, ‘(? = 0 OR (? != 0 AND publlink = ?))’ 조건에서 ‘(? != 0 AND publlink = ?)’ 조건은 publlink 인덱스를 사용하겠지만 ‘? = 0’ 조건은 publlink 인덱스를 사용하지 않으므로 full scan 방식을 택할 수 밖에 없다. (Index scan OR full scan)은 full scan 이므로 1번 방법은 변수 $link 값에 무엇이 들어오든 full scan 실행계획이 수립되어 전체 SQL 수행속도를 떨어뜨릴 것이다. 3번(DECODE()사용) 방법의 경우, ‘nvl(publlink,0) = decode(?,0,nvl(publlink,0),?)’ 조건은 좌변이 가공되어 있으므로 publlink 인덱스를 원척적으로 사용할 수 없다. 또한, $link 조건이 보다 복잡하게 들어올 경우는 DECODE()문이 복잡해져서 구현하기도 쉽지 않다. 그러므로, 2번(UNION ALL사용) 방법을 사용해야 한다. 이러한 방법을 ‘분리실행계획’을 세운다고 하는데, 문제에서 $link 값에 0이 들어오면 full scan을 하고 0이외의 값이 들어오면 index scan을 하므로 각각의 경우에 따라 최적의 실행계획을 보장받을 수 있다.
이와 같이, dynamic SQL을 bind variable을 사용하는 static SQL로 바꾸는 방법은 다양하게 존재하나 dynamic WHERE 조건이 전체 SQL에 어떤 성격의 조건으로 활용되느냐에 따라서 신중하게 생각해서 선택해야 한다.


